探索 Azure 存储
在本练习中,你将了解如何预配和配置 Azure 存储帐户,并探索其核心服务:Blob 存储、Data Lake Storage Gen2、Azure 文件存储和 Azure 表。 你将获得创建容器、上传数据、启用分层命名空间、设置文件共享和管理表实体的实践经验。 这些技能将帮助你理解如何在 Azure 中为各种分析和应用场景存储、组织和保护非关系数据。
完成本实验室大约需要 15 分钟。
**** 提示:理解每个操作的目的有助于以后设计用于平衡成本、性能、安全性和分析目标的存储解决方案。这些简短的原因说明将每个步骤与现实世界的原因联系起来。
开始之前
需要一个你在其中具有管理级权限的 Azure 订阅。
预配 Azure 存储帐户
使用 Azure 存储的第一步是在 Azure 订阅中预配 Azure 存储帐户。
**** 提示:存储帐户是所有 Azure 存储服务(Blob、文件、队列、表)的安全计费边界。策略、冗余、加密、网络和访问控制从此处向下应用。
-
如果你还没有完成此操作,请登录 Azure 门户。
-
在 Azure 门户主页的左上角,选择“+ 创建资源”,并搜索
Storage account。 然后在出现的“存储帐户”页中,选择“创建”。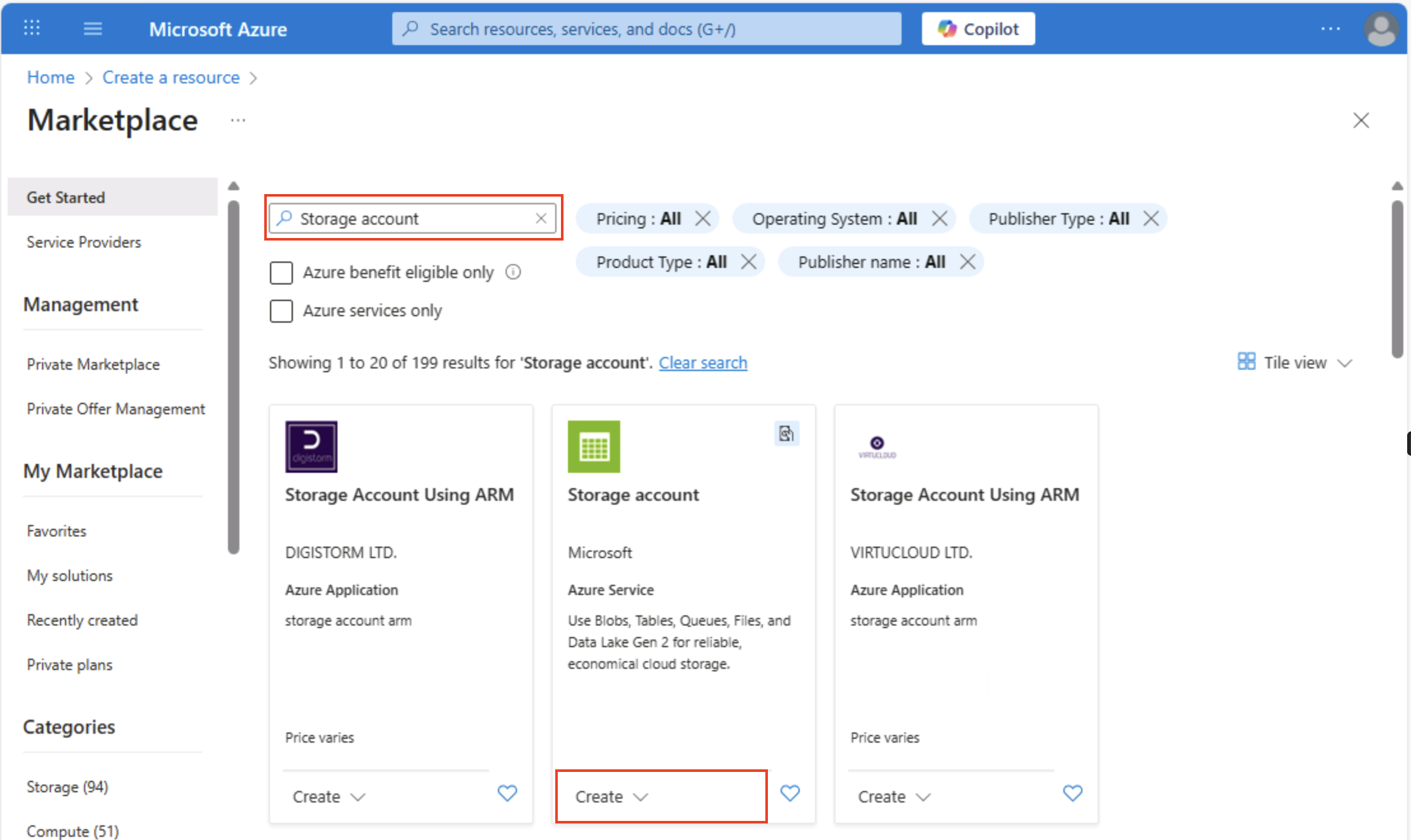
-
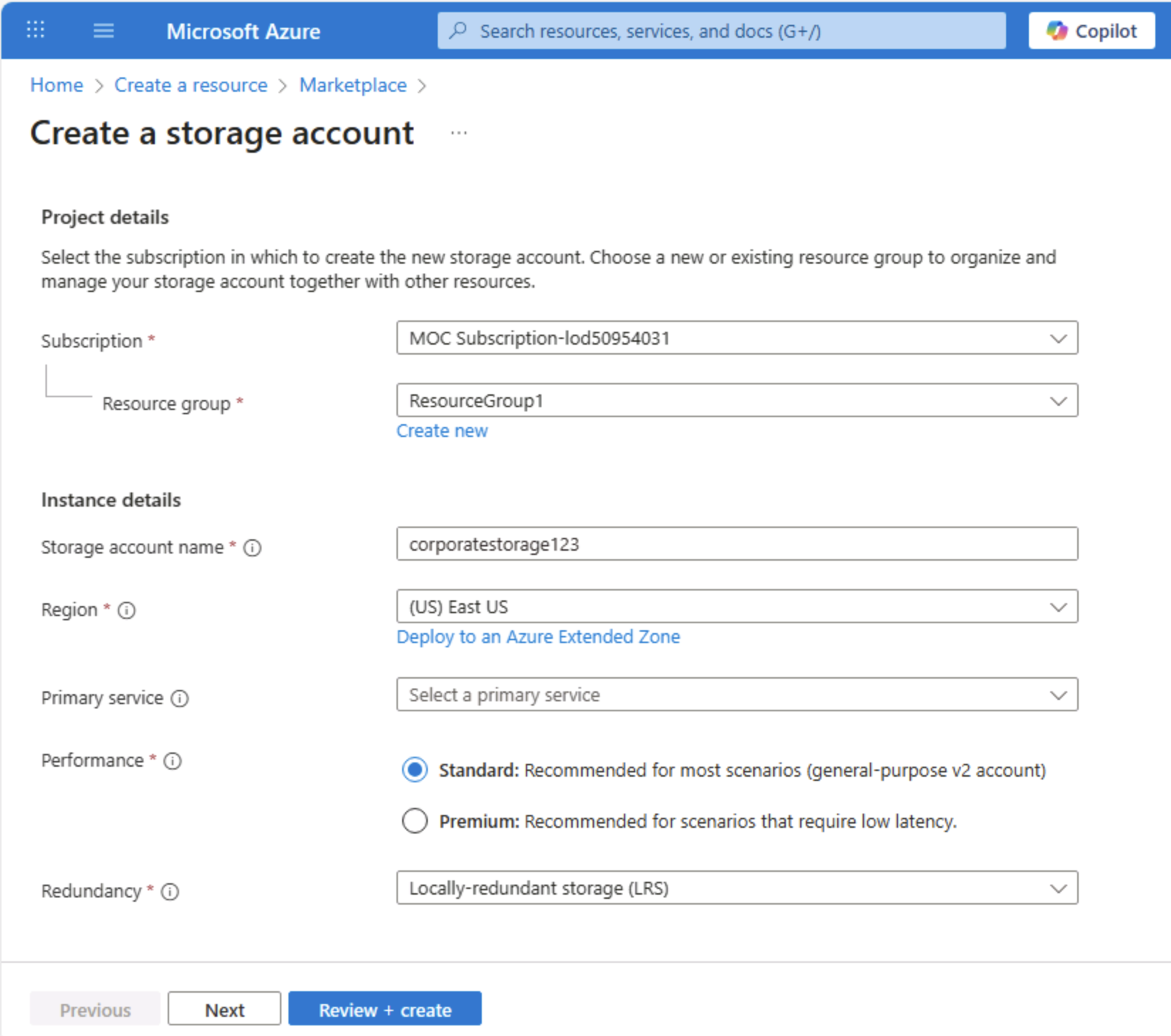
在“创建存储帐户”页上,输入以下值:
- 订阅:选择 Azure 订阅。
- 资源组:使用所选名称创建新资源组。
- 存储帐户名称:使用小写字母和数字输入存储帐户的唯一名称。
- 区域:选择任何可用位置。
- 性能:标准
- 冗余:本地冗余存储 (LRS)
**** 提示:新的资源组使清理变得简单。标准 + LRS 是成本最低的基线,非常适合学习。LRS 在一个区域中保留三个同步副本,对于非关键演示数据来说已经足够,而无需为异地复制付费。
-
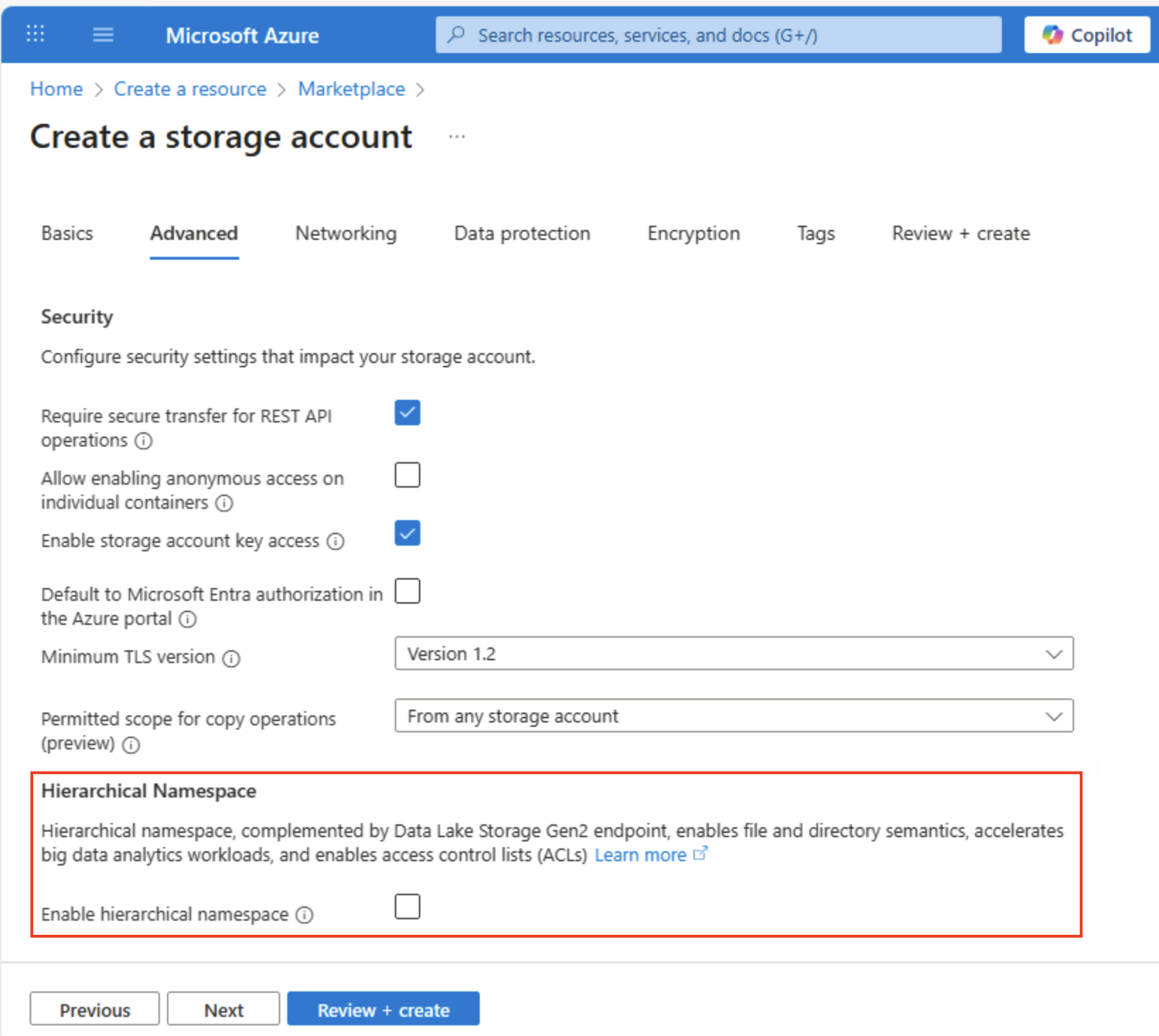
选择“下一步: 高级 >”以查看高级配置选项。 特别要注意的是,可在此处启用分层命名空间,以支持 Azure Data Lake Storage Gen2。 将此选项保留为“未选中”状态(稍后会启用),然后选择“下一步: 网络 >”以查看存储帐户的网络选项。
-
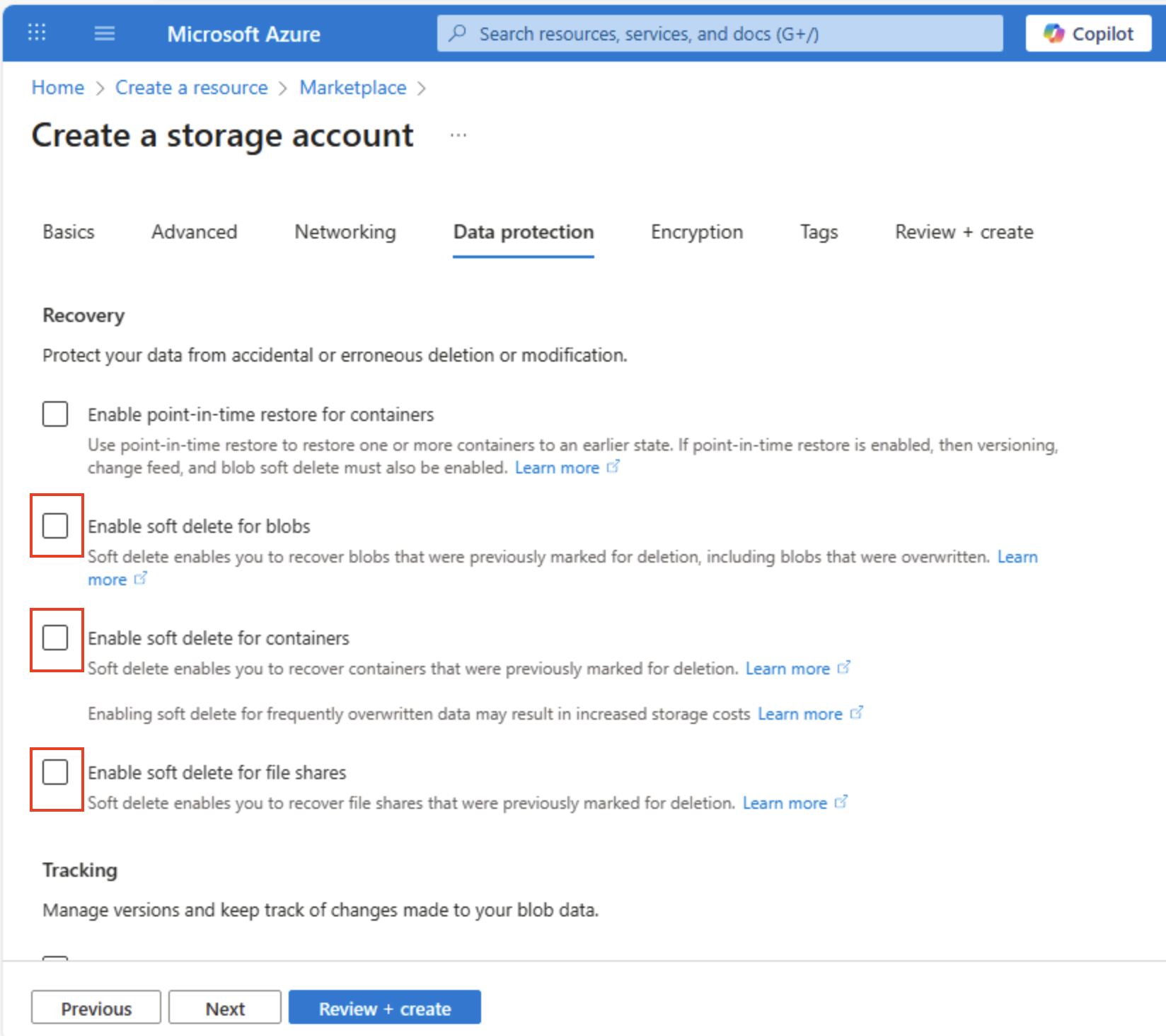
选择“下一步: 数据保护 >”,然后在“恢复”部分中,取消选中所有“启用软删除…”选项。 这些选项会保留已删除的文件以供后续恢复,但以后当你启用分层命名空间时,可能会导致问题。
-
继续转到其余的“下一步 >”页面,不更改任何默认设置,然后在“查看”页上,等待你的选择通过验证,然后选择“创建”以创建 Azure 存储帐户。
-
等待部署完成。 然后,转到已部署的资源。
了解 Blob 存储
现在,你已有一个 Azure 存储帐户,可以为 blob 数据创建容器。
**** 提示:容器对 Blob 进行分组,是访问控制的第一个范围级别。从普通 Blob 存储(无分层命名空间)开始,显示了你之后要与 Data Lake Gen2 进行比较的虚拟文件夹行为。
-
从
https://aka.ms/product1.json下载 product1.json JSON 文件,并将它保存在你的计算机上(可以将它保存在任何文件夹中 - 稍后将它上传到 Blob 存储)。如果浏览器中显示了 JSON 文件,请将该页另存为 product1.json。
-
在存储容器的“Azure 门户”页左侧的“数据存储”部分中,选择“容器”。
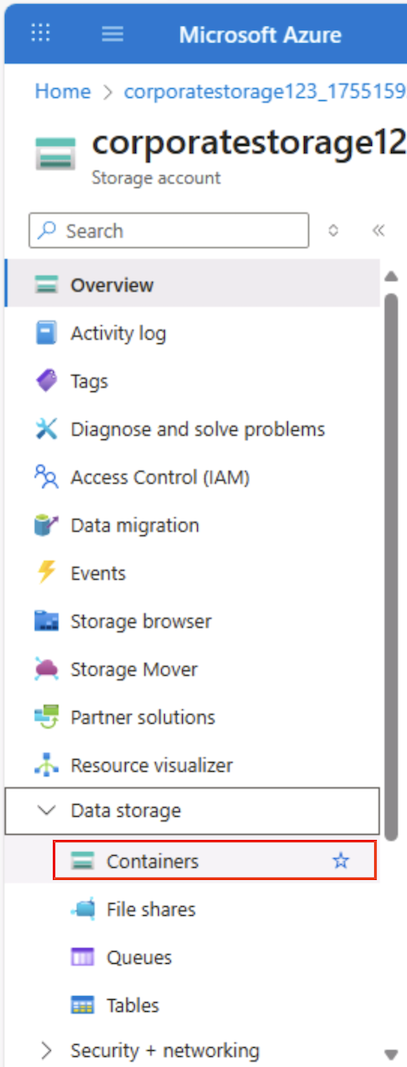
-
在“容器”页中,选择“+ 添加容器”,然后添加一个名为
data的新容器,其匿名访问级别为“专用(不允许匿名访问)”****。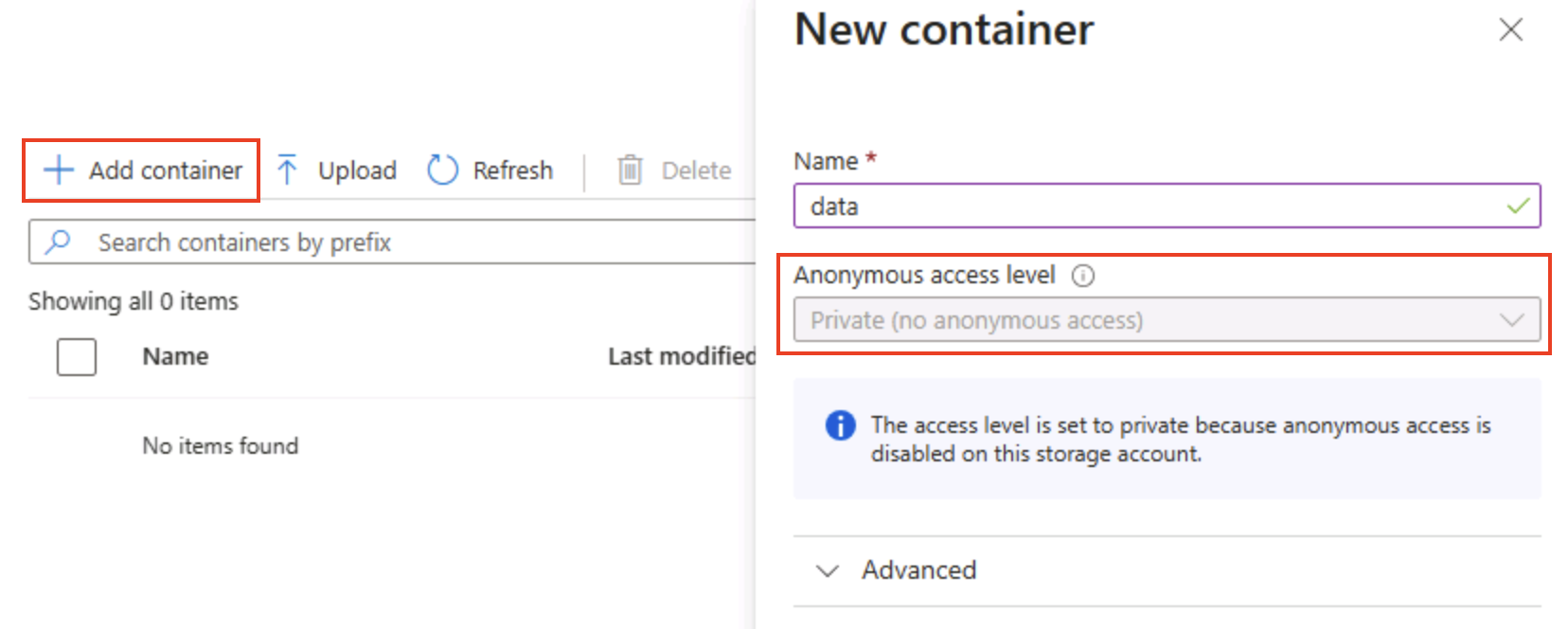
**** 提示:“专用”可保护示例数据的安全。除了静态网站或开放数据场景外,很少需要公共访问。将它命名为
data可使此示例保持简单且可读。 -
创建“data”容器后,验证它是否在“容器”页中列出。
-
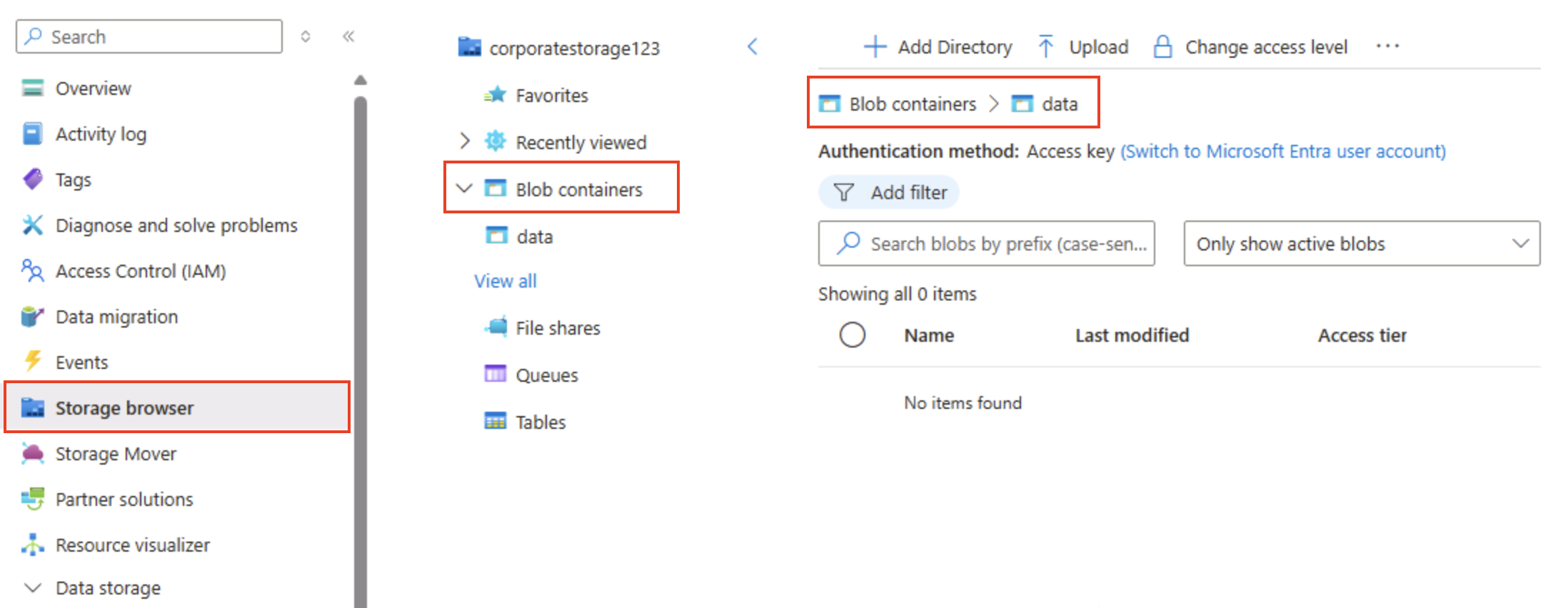
在左侧窗格的顶部,选择“存储浏览器”。 此页提供一个基于浏览器的界面,可用于处理存储帐户中的数据。
-
在“存储浏览器”页中,选择“Blob 容器”,然后验证是否已列出“data”容器。
-
选择“data”容器,注意它是空的。
-
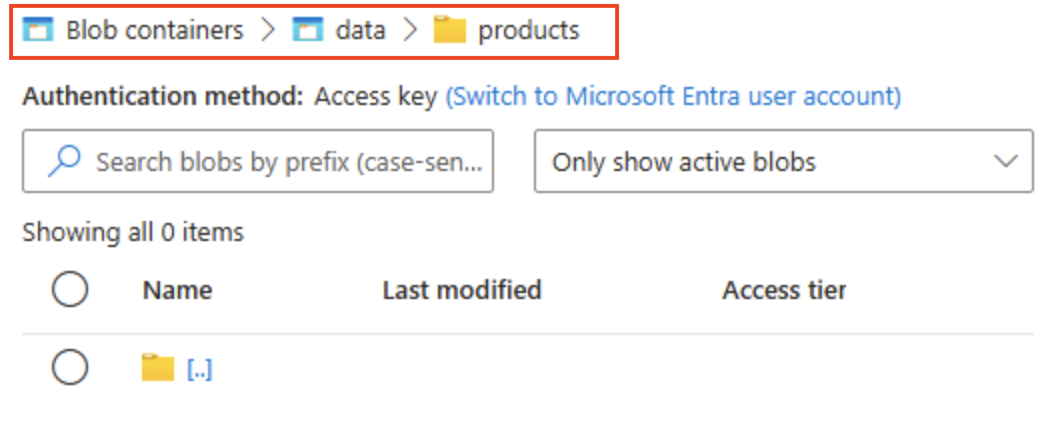
选择“+ 添加目录”,阅读有关文件夹的信息,然后创建名为
products的新目录。 -
在存储浏览器中,验证当前视图是否显示刚刚创建的“products”文件夹的内容,观察页面顶部的“痕迹导航”是否反映了路径“Blob 容器”>“data”>“products” 。
-
在痕迹导航中,选择“data”以切换到“data”容器,注意它不包含名为“products”的文件夹。
Blob 存储中的文件夹是虚拟文件夹,仅作为 blob 路径的一部分存在。 由于“products”文件夹不包含任何 blob,所以它并不真正存在!
**** 提示:平面命名空间意味着目录只是名称前缀 (products/file.json)。此设计可实现大规模缩放,因为服务为 Blob 名称编制索引,而不是维护真正的树结构。
-
使用“⤒ 上传”按钮打开“上传 blob”面板。
-
在“上传 blob”面板中,选择先前保存在本地计算机上的 product1.json 文件。 然后,在“高级”部分的“上传到文件夹”框中,输入
product_data并选择“上传”按钮。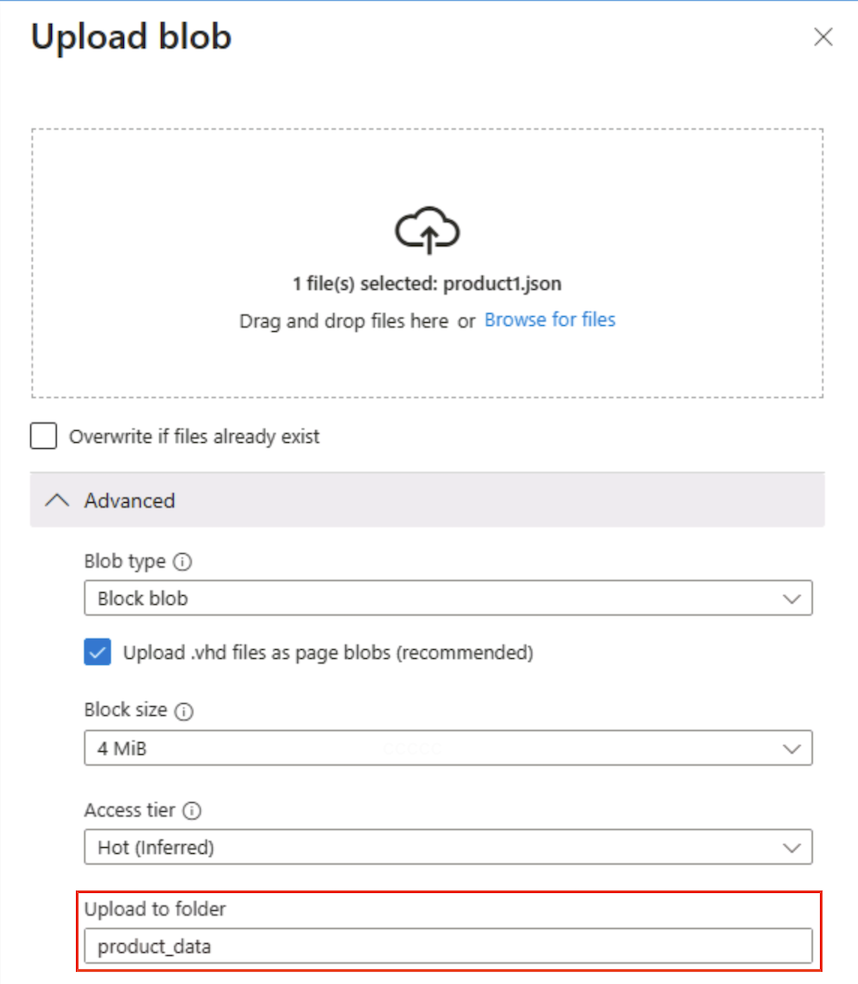
**** 提示:上传时提供文件夹名称会自动创建虚拟路径,说明了 Blob 的存在会使“文件夹”出现。
-
如果“上传 blob”面板仍处于打开状态,请将其关闭,并验证是否已在“data”容器中创建 product_data 虚拟文件夹。
-
选择 product_data 文件夹,并验证它是否包含已上传的 product1.json blob。
-
在左侧的“数据存储”部分中,选择“容器”。
-
打开“data”容器,并验证是否已列出你创建的 product_data 文件夹。
-
选择文件夹右端的 ‧‧‧ 图标,注意它不显示任何选项。 平面命名空间 Blob 容器中的文件夹是虚拟文件夹,不能进行管理。
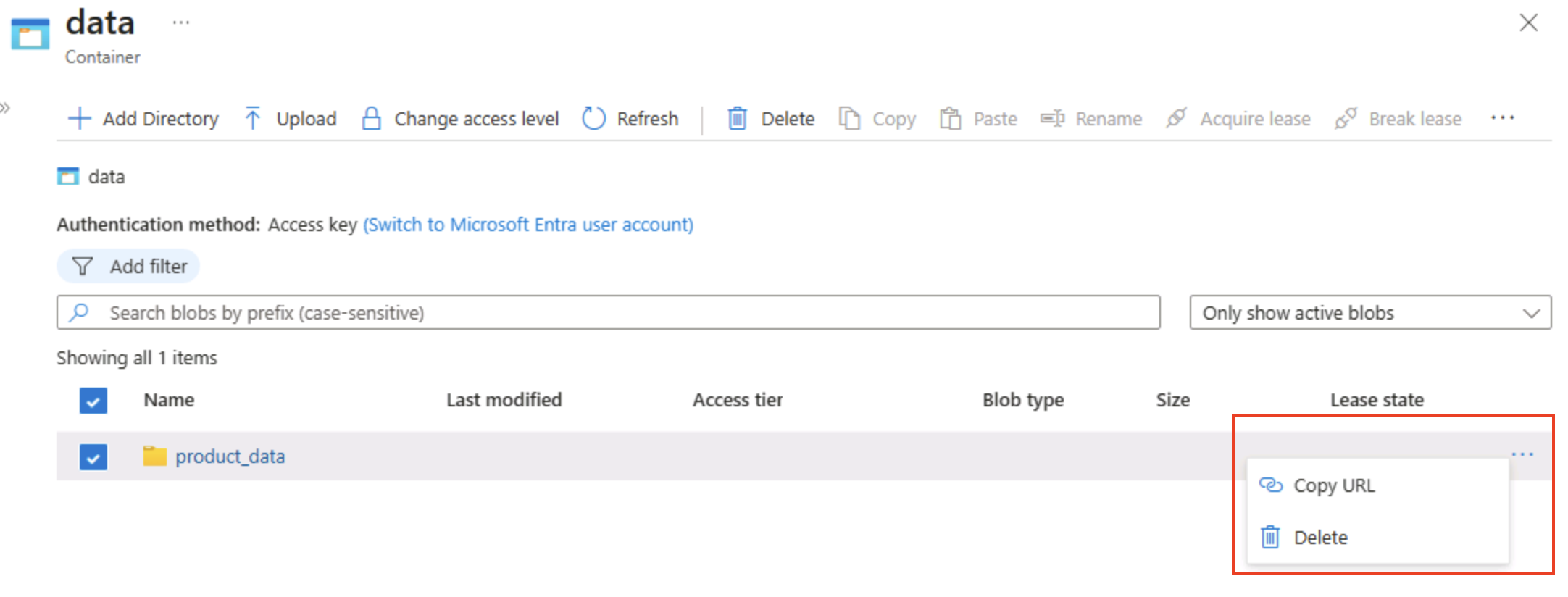
**** 提示:不存在真正的目录对象,因此没有重命名/权限操作 — 这些操作需要分层命名空间。
-
使用“data”页右上角的“X”图标关闭页面并返回到“容器”页。
了解 Azure Data Lake Storage Gen2
Azure Data Lake Storage Gen2 支持使你能够使用分层文件夹来组织和管理对 blob 的访问。 它还使你能够使用 Azure Blob 存储来托管用于常见大数据分析平台的分布式文件系统。
**** 提示:启用分层命名空间会使文件夹的行为类似于真实目录。它还使你能够安全地执行文件夹操作(一次完成,没有错误),并提供类似于 Linux 中的文件权限控制。当使用 Spark 或 Hadoop 等大数据工具或管理有组织的大型数据湖时,这尤其有用。
-
从
https://aka.ms/product2.json下载 product2.json JSON 文件,并将其保存在计算机上(之前下载 product1.json 的同一文件夹中),稍后将其上传到 Blob 存储。 -
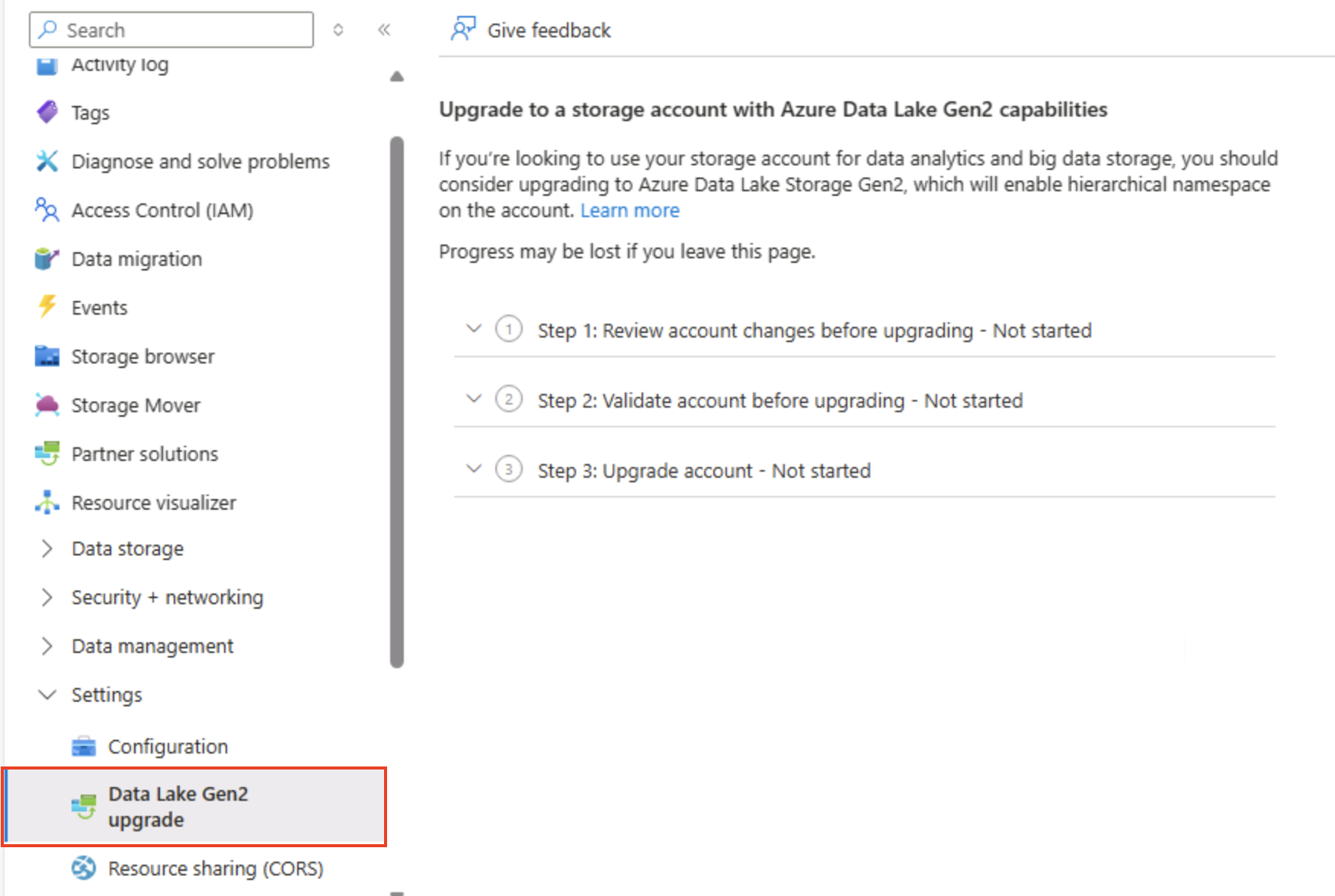
在存储账户的“Azure 门户”页的左侧,向下滚动到“设置”部分,然后选择“Data Lake Gen2 升级” 。
-
在“Data Lake Gen2 升级”页上,展开并完成每个步骤以升级存储帐户,从而启用分层命名空间并支持 Azure Data Lake Storage Gen**。 这可能需要一些时间。
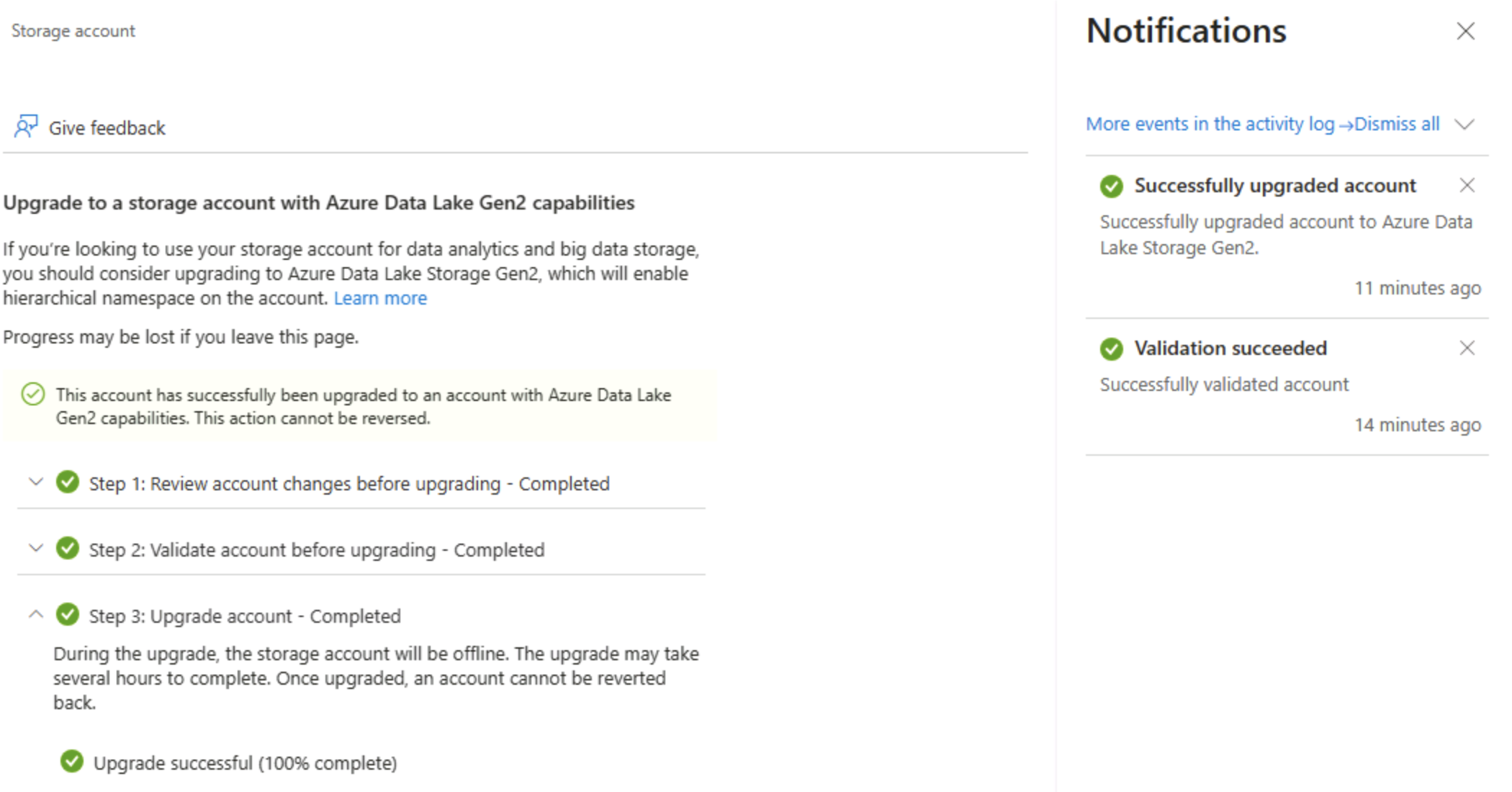
**** 提示:升级是帐户级功能开关 - 数据保持不变,但目录语义更改以支持高级操作。
-
升级完成后,在左侧窗格中的顶部,选择“存储浏览器”,然后导航回 data Blob 容器的根目录,其中仍包含 product_data 文件夹。
-
选择 product_data 文件夹,并确认它仍包含之前上传的 product1.json 文件。
-
使用“⤒ 上传”按钮打开“上传 blob”面板。
-
在“上传 blob”面板中,选择保存在本地计算机上的 product2.json 文件。 然后选择“上传”按钮。
-
如果“上传 blob”面板仍处于打开状态,请将其关闭,并验证 product_data 文件夹现在是否包含 product2.json 文件。
**** 提示:在升级后添加第二个文件可确认无缝连续性:现有 Blob 仍然工作,新的 Blob 将获得分层优势,例如目录 ACL(访问控制列表)。
-
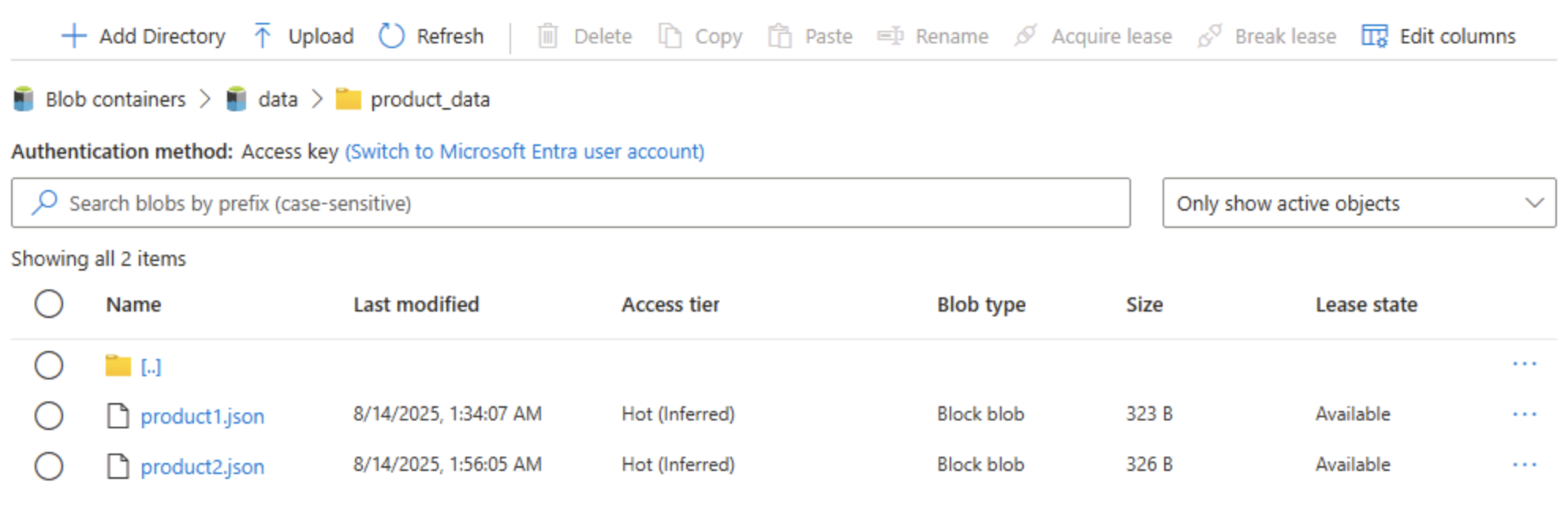
在左侧的“数据存储”部分中,选择“容器”。
-
打开“data”容器,并验证是否已列出你创建的 product_data 文件夹。
-
选择文件夹右端的 ‧‧‧ 图标,并注意在启用分层命名空间后,你可以在文件夹级别执行配置任务;包括重命名文件夹和设置权限。
**** 提示:实际文件夹使你能够在文件夹粒度上应用最小特权安全性、安全地重命名并加快递归列表的速度,而不是扫描数千个带前缀的 Blob 名称。
-
使用“data”页右上角的“X”图标关闭页面并返回到“容器”页。
了解 Azure 文件存储
Azure 文件存储为创建基于云的文件共享提供了一种方法。
**** 提示:Azure 文件存储为应用需要传统文件系统的直接迁移场景提供 SMB/NFS 终结点。它通过支持文件锁定和 OS 本机工具来补充(而非替换)Blob 存储。
-
在存储容器的“Azure 门户”页左侧的“数据存储”部分中,选择“文件共享”。

-
在“文件共享”页中,选择“+ 文件共享”,并使用“事务优化”层添加名为
files的新文件共享。 -
选择“下一步: 备份 >”并禁用备份。 然后,选择“审阅并创建”**。
**** 提示: 禁用备份可降低短期实验室环境的成本 — 可以启用它以实现生产复原能力。
-
在“文件共享”中,打开新的“文件”共享。
-
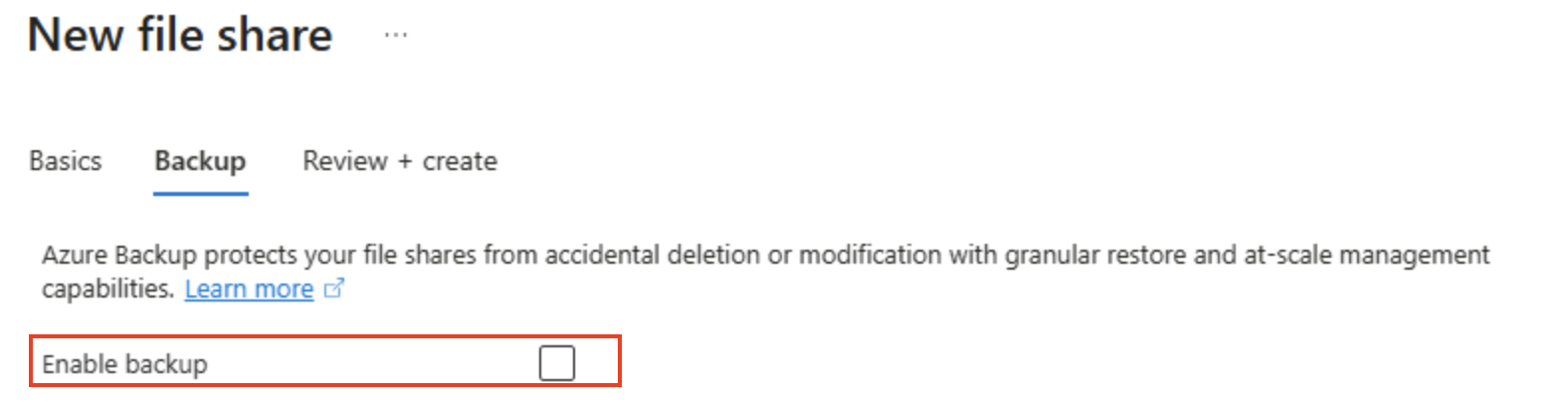
在页面顶部,选择“连接”。 然后,在“连接”窗格中,注意有常见操作系统(Windows、Linux 和 macOS)的选项卡,其中包含可运行以从客户端计算机连接到共享文件夹的脚本。
**** 提示:生成的脚本确切地显示了如何使用平台本机命令装载共享,说明了来自虚拟机、容器或本地服务器的混合访问模式。
-
关闭“连接”窗格,然后关闭“文件”页以返回到 Azure 存储帐户的“文件共享”页。
了解 Azure 表
Azure 表为需要存储数据值但不需要关系数据库的完整功能和结构的应用程序提供了键/值存储。
**** 提示:表存储以丰富的查询和联接换取超低成本、无架构灵活性和水平缩放 — 非常适合日志、IoT 数据或用户配置文件。
-
在存储容器的“Azure 门户”页左侧的“数据存储”部分中,选择“表”。
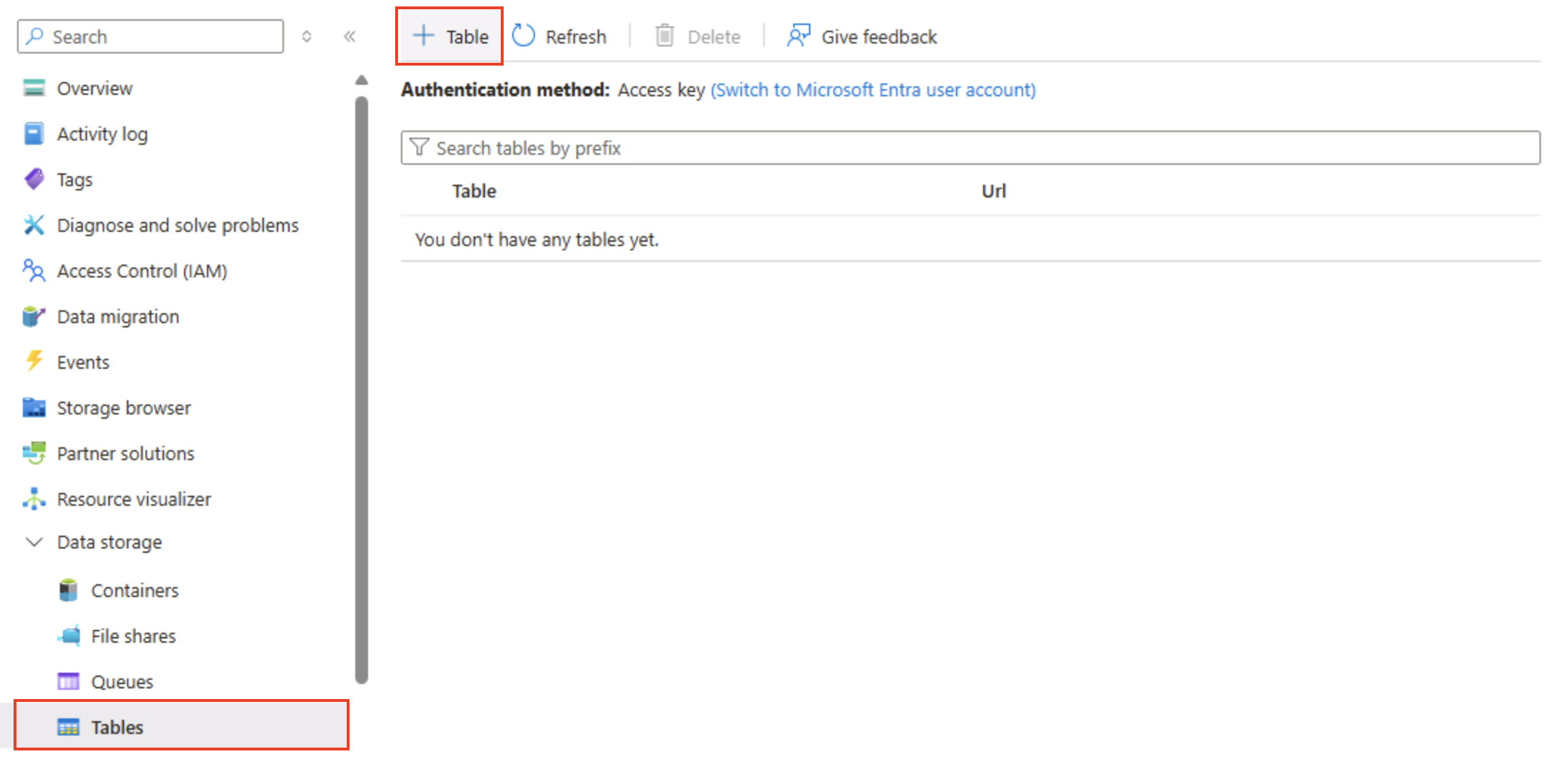
-
在“表”页上,选择“+ 表”并创建名为
products的新表。 -
创建 products 表后,在左侧窗格的顶部,选择“存储浏览器” 。
-
在存储资源管理器中,选择“表”并验证是否已列出“products”表。
-
选择“products”表。
-
在 products 页中,选择“+添加实体” 。
- 在“添加实体”面板中,输入以下键值:
- PartitionKey:1
- RowKey:1
**** 提示:PartitionKey 将相关实体分组以分发负载;RowKey 在分区内唯一地进行标识。它们共同构成用于查找的快速复合主键。
-
选择“添加属性”**,然后创建两个具有以下值的新属性:
属性名称 类型 值 名称 String 小组件 价格 Double 2.99 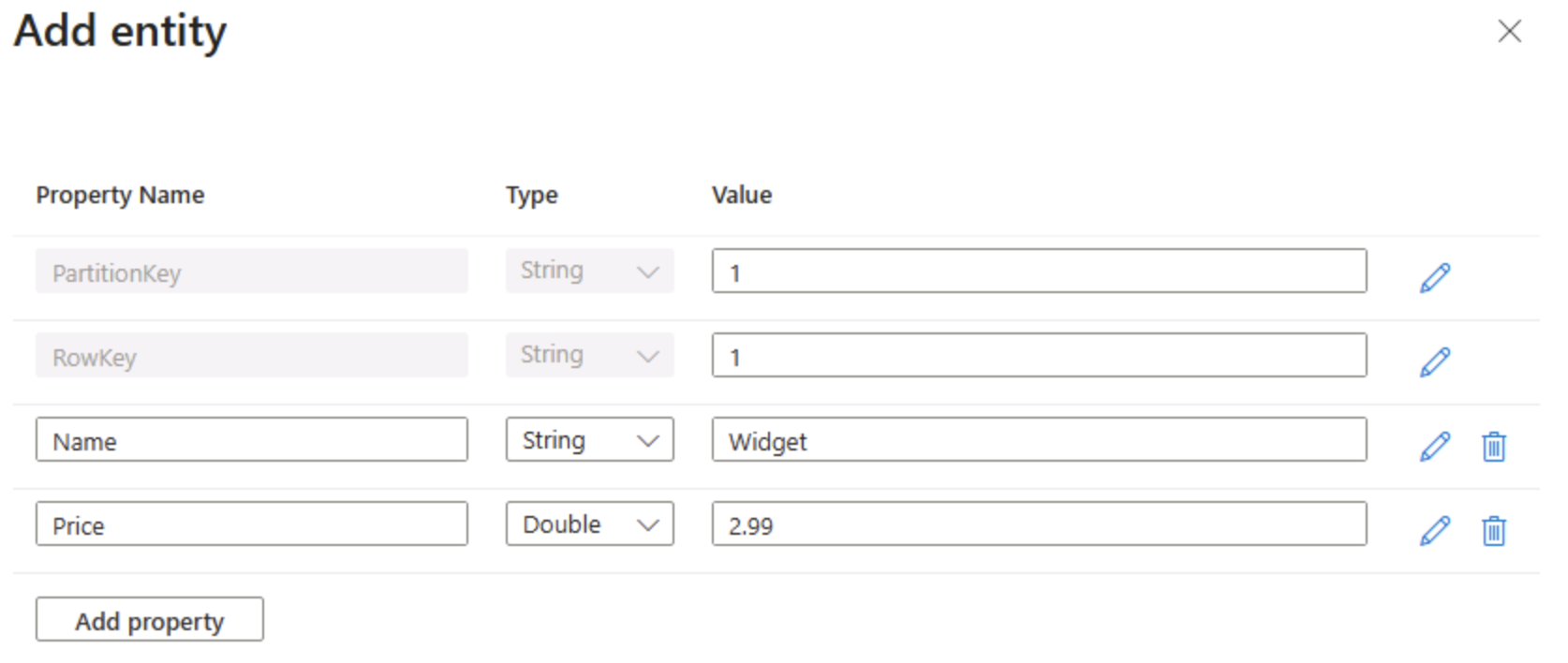
-
选择“插入”,将新实体的行插入表中。
-
在存储浏览器中,验证是否已向“products”表添加行,并且是否已创建“Timestamp”列来指示上次修改该行的时间。
-
使用以下属性将另一个实体添加到“products”表中:
属性名称 类型 值 PartitionKey 字符串 1 RowKey 字符串 2 名称 String Kniknak 价格 Double 1.99 已中断 布尔 是 **** 提示:添加具有不同键和额外布尔属性的第二个实体展示了写入时架构的灵活性 — 新属性不需要迁移。
-
插入新实体后,验证表中是否显示了包含已停用产品的行。
你已使用存储浏览器界面将数据手动输入到表中。 在实际场景中,应用程序开发人员可以使用 Azure 存储表 API 生成可读取表值和向表写入值的应用程序,这使得它成为 NoSQL 存储的经济高效且可缩放的解决方案。
**** 提示:如果已完成对 Azure 存储的探索,可删除在本练习中创建的资源组。删除资源组是通过一次性删除创建的每个资源来避免持续收费的最快捷方法。