Изучение аналитики данных в Microsoft Fabric
В этом упражнении вы изучите прием данных и аналитику в Microsoft Fabric Lakehouse.
Завершив эту лабораторию, вы выполните следующие действия.
- Общие сведения о концепциях Microsoft Fabric Lakehouse. Узнайте, как создавать рабочие области и озера, которые являются центральными для организации ресурсов данных и управления ими в Fabric.
- Прием данных с помощью конвейеров: используйте управляемый конвейер для переноса внешних данных в lakehouse, что делает его готовым к запросу без ручного написания кода.
- Изучение и запрос данных с помощью SQL: анализ приема данных с помощью знакомых SQL-запросов, получение аналитических сведений непосредственно в Fabric.
- Управление ресурсами. Ознакомьтесь с рекомендациями по очистке ресурсов, чтобы избежать ненужных расходов.
Фон в наборе данных такси Нью-Йорка:
Набор данных “Такси Нью-Йорка - Зеленый” содержит подробные записи о поездках на такси в Нью-Йорке, включая время сбора и удаления, места, расстояния поездки, тарифы и количество пассажиров. Он широко используется в аналитике данных и машинном обучении для изучения городской мобильности, прогнозирования спроса и обнаружения аномалий. В этой лаборатории вы будете использовать этот реальный набор данных для практики приема и анализа данных в Microsoft Fabric.
Выполнение этого задания займет около 25 минут.
Примечание. Для выполнения этого упражнения потребуется лицензия Microsoft Fabric. Дополнительные сведения о том, как включить бесплатную пробную лицензию Fabric, см. в статье Начало работы с Fabric. Для этого вам понадобится учебная или рабочая учетная запись Microsoft. Если у вас ее нет, вы можете зарегистрироваться для пробной версии Microsoft Office 365 E3 или более поздней версии.
При первом использовании функций Microsoft Fabric могут появиться подсказки. Отклонить их.
Создание рабочей области
Прежде чем работать с данными в Fabric, создайте рабочую область с включенной пробной версией Fabric.
Совет. Рабочая область — это контейнер для всех ресурсов (lakehouses, конвейеров, записных книжек, отчетов). Включение емкости Fabric позволяет выполнять эти элементы.
-
Перейдите на домашнюю страницу
https://app.fabric.microsoft.com/home?experience=fabricMicrosoft Fabric в браузере и войдите с помощью учетных данных Fabric. -
В строке меню слева выберите Рабочие области (значок выглядит как ).
-
Создайте рабочую область с выбранным именем, выбрав режим лицензирования в разделе Дополнительно, который включает возможности Fabric (пробная версия, premium или Fabric).
Совет по выбору емкости, которая включает Fabric, дает рабочей области подсистемы, необходимые для задач проектирования данных. Использование выделенной рабочей области обеспечивает изоляцию и простоту очистки ресурсов лаборатории.
-
Когда откроется новая рабочая область, она должна быть пустой.
Создание озера данных
Теперь, когда у вас есть рабочая область, пришло время создать lakehouse для файлов данных.
Совет: Lakehouse объединяет файлы и таблицы в OneLake. Вы можете хранить необработанные файлы, а также создавать управляемые разностные таблицы, которые можно запрашивать с помощью SQL.
-
В строке меню слева нажмите кнопку “Создать”. ** На новой странице в разделе Инжиниринг данных выберите Lakehouse. Присвойте ему уникальное имя вашего выбора.
Примечание. Если параметр “Создать “ не закреплен на боковой панели, сначала необходимо выбрать параметр с многоточием (…).
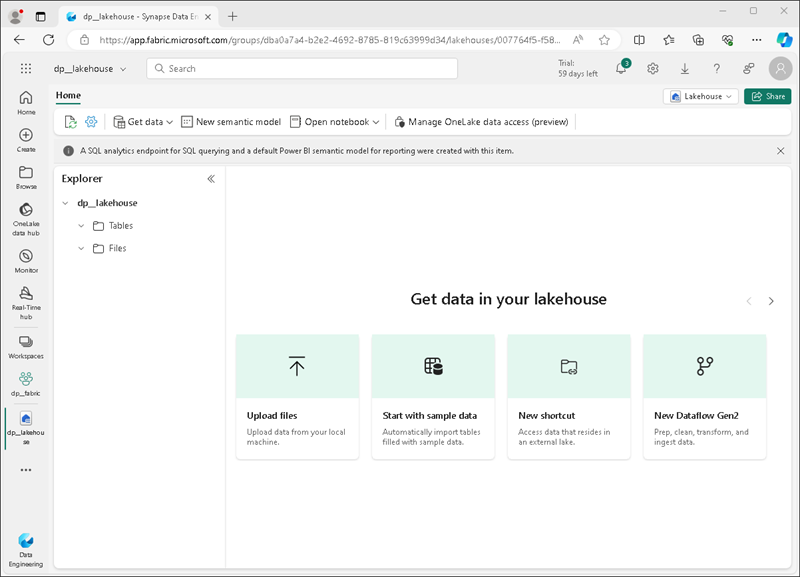
Через минуту или около того будет создано новое озеро данных:
-
Просмотрите новое озеро данных и обратите внимание, что Панель обозревателя озера данных слева позволяет просматривать таблицы и файлы в озере данных:
- Папка “Таблицы” содержит таблицы, которые можно запрашивать семантикой SQL. Таблицы в озере Microsoft Fabric основаны на формате файла с открытым кодом Delta Lake, часто используемом в Apache Spark.
- Папка Файлы содержит файлы данных в хранилище OneLake для озера данных, которые не связаны с управляемыми таблицами Delta. Вы также можете создать ярлыки в этой папке, чтобы ссылаться на данные, которые хранятся во внешней памяти.
В настоящее время в озере данных нет таблиц или файлов.
Совет. Использование файлов для необработанных или промежуточных данных и таблиц для курированных наборов данных, готовых к запросу. Таблицы поддерживаются Delta Lake, поэтому они поддерживают надежные обновления и эффективные запросы.
Прием данных
Простой способ приема данных — использовать действие Копировать данные в конвейере, чтобы извлечь данные из источника и скопировать их в файл в озере данных.
Совет. Конвейеры предоставляют интерактивный, повторяемый способ переноса данных в lakehouse. Они проще, чем написание кода с нуля и могут быть запланированы позже при необходимости.
-
На домашней странице озера в меню “Получение данных” выберите **“Создать конвейер данных” и создайте новый конвейер данных с именем **“Прием данных”.
-
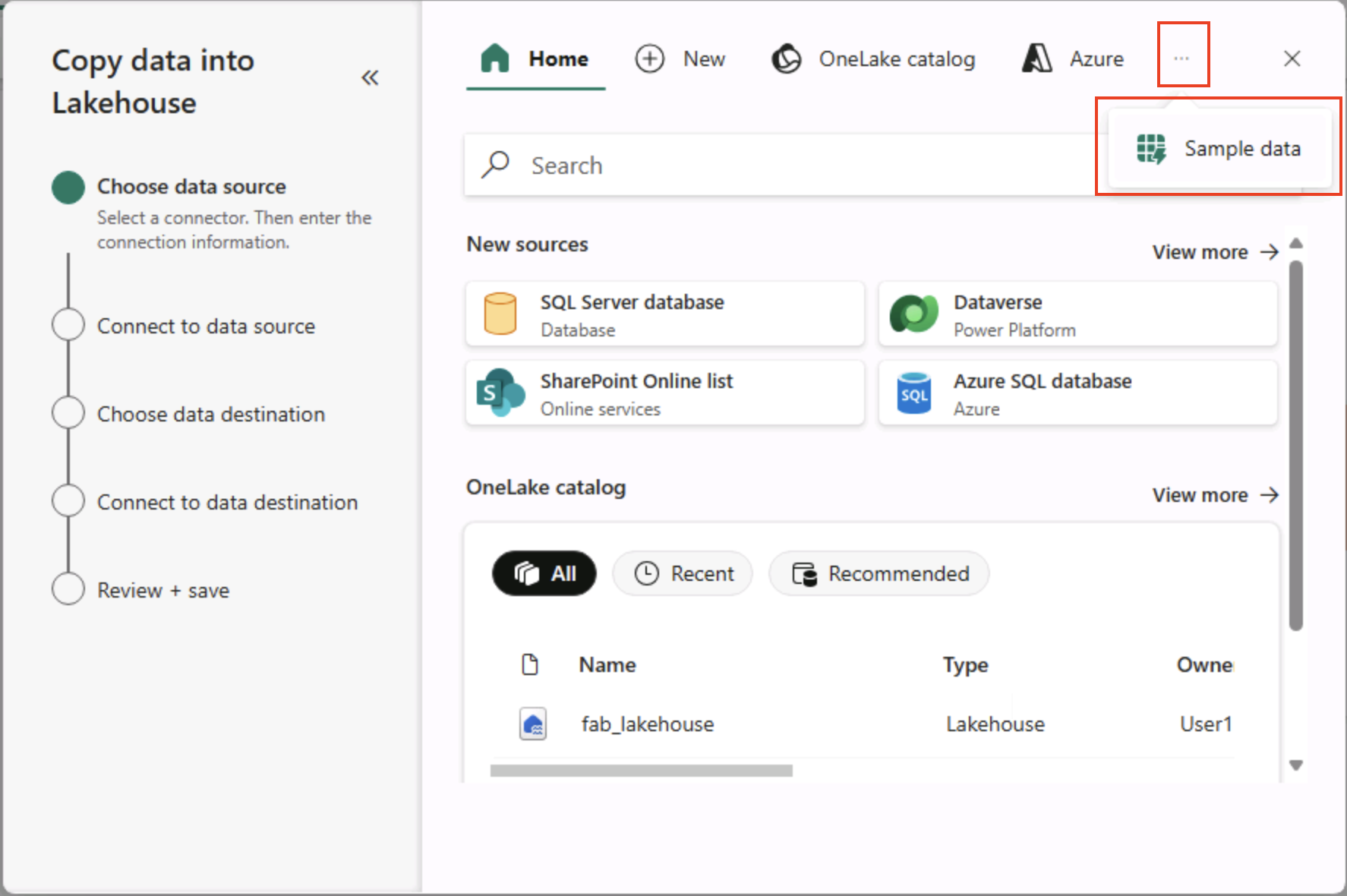
В мастере копирования данных на странице “Выбор источника данных” выберите пример данных, а затем выберите набор данных NYC Taxi — Зеленый ** набор данных.
-
На странице “Подключение к источнику данных” просмотрите таблицы в источнике данных. Должна быть одна таблица, содержащая подробные сведения о поездках на такси в Нью-Йорке. Затем нажмите кнопку “Далее “, чтобы перейти на страницу “Подключение к назначению данных”.
- На странице “Подключение к назначению данных” задайте следующие параметры назначения данных и нажмите кнопку “Далее”.
- Корневая папка: Таблицы
- Загрузка параметров: загрузка в новую таблицу
- Имя целевой таблицы: taxi_rides (возможно, потребуется дождаться предварительного просмотра сопоставлений столбцов, прежде чем изменить это)
- Сопоставления столбцов: оставьте эту настройку по умолчанию как есть
- Включить раздел: Не выбрано
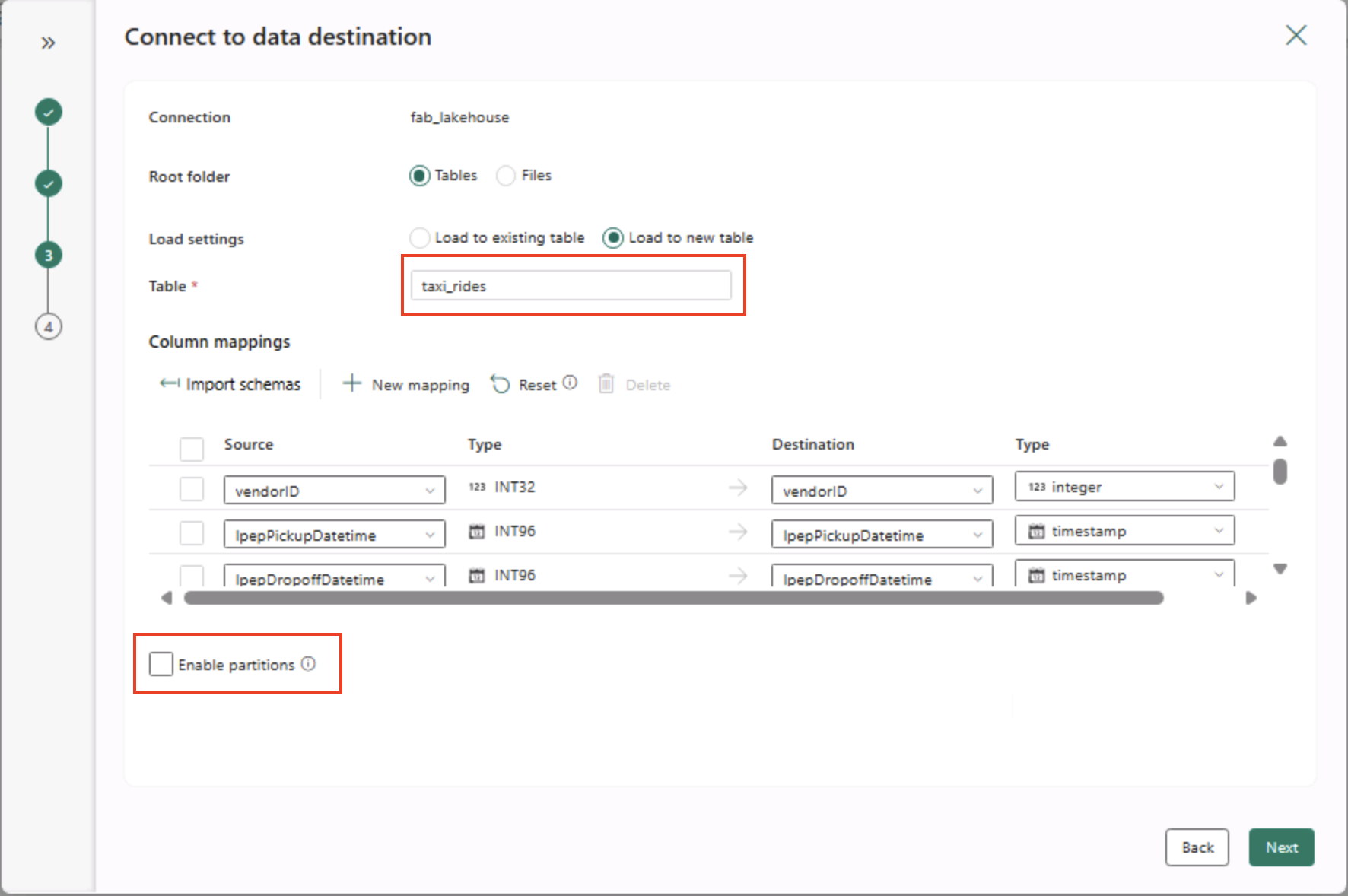
Почему эти варианты?
Мы начинаем с таблиц в качестве корня, чтобы данные сразу переходились в управляемую разностную таблицу, которую можно запрашивать сразу. Мы загружаем его в новую таблицу , поэтому эта лаборатория остается автономной **и ничего существующего не получает перезаписывать. Мы будем придерживаться **сопоставлений столбцов по умолчанию, так как образцы данных уже соответствуют ожидаемой структуре— не требуется настраиваемого сопоставления. Секционирование отключено, чтобы обеспечить простоту для этого небольшого набора данных. При этом секционирование полезно для крупномасштабных данных, здесь не требуется.
-
На страницеПросмотреть и сохранить убедитесь, что выбран параметр Немедленно начать передачу данных и нажмите кнопку Сохранить и запустить.
Совет. Запуск немедленно позволяет отслеживать конвейер в действии и подтвердить поступление данных без дополнительных шагов.
Создается новый конвейер, содержащий действие Копировать данные, как показано ниже:
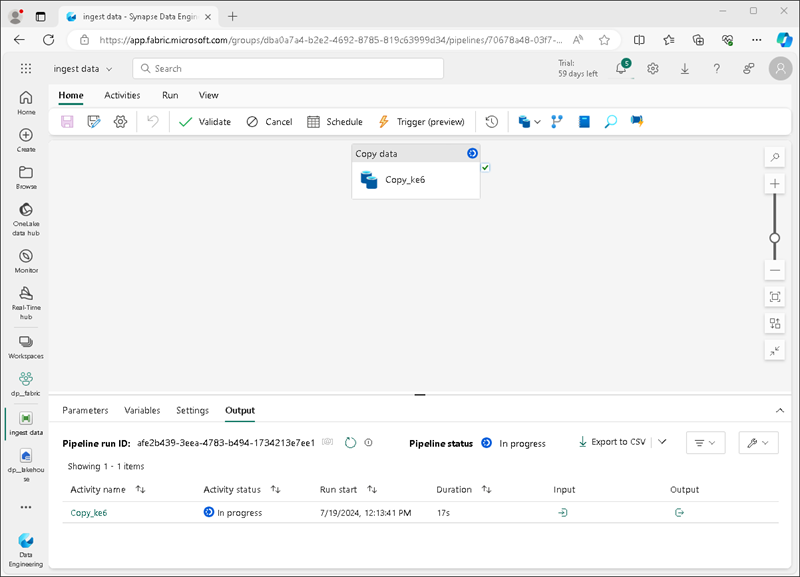
При запуске конвейера можно отслеживать его состояние на панели Вывод в разделе конструктора конвейеров. Используйте значок ↻ (обновить) для обновления состояния и дождитесь успешного выполнения (что может занять 10 минут или больше). Этот конкретный набор данных содержит более 75 миллионов строк, сохраняя около 2,5 ГБ данных.
-
В строке меню концентратора слева выберите озеро данных.

-
На домашней странице в области обозревателя Lakehouse в меню “ Таблицы” в узле “Таблицы” выберите “Обновить **”, а затем разверните **“Таблицы**”, чтобы убедиться, что **таблица taxi_rides создана.
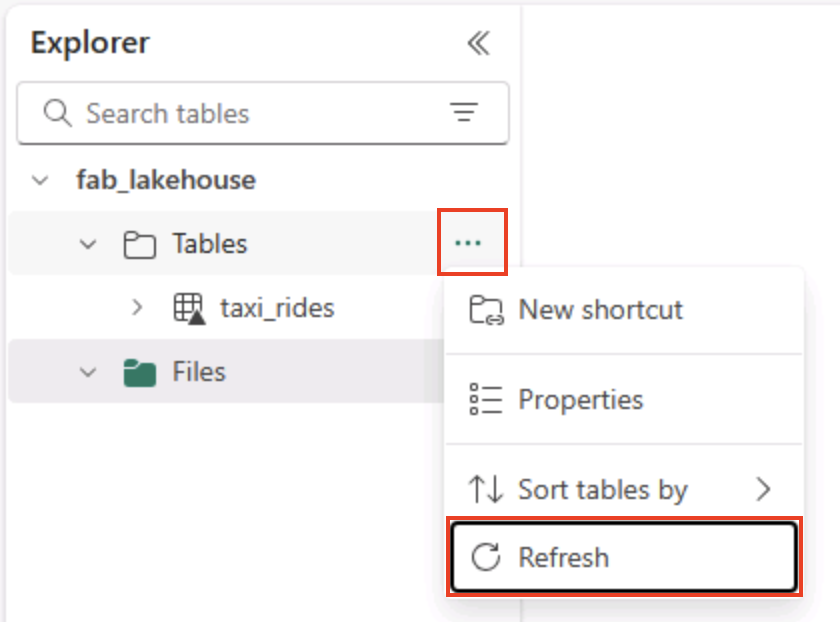
Примечание. Если новая таблица указана как неопознанная, используйте его меню “Обновить “, чтобы обновить представление.
Совет. Представление обозревателя кэшируется. Обновление заставляет его получить последние метаданные таблицы, чтобы новая таблица отображалась правильно.
-
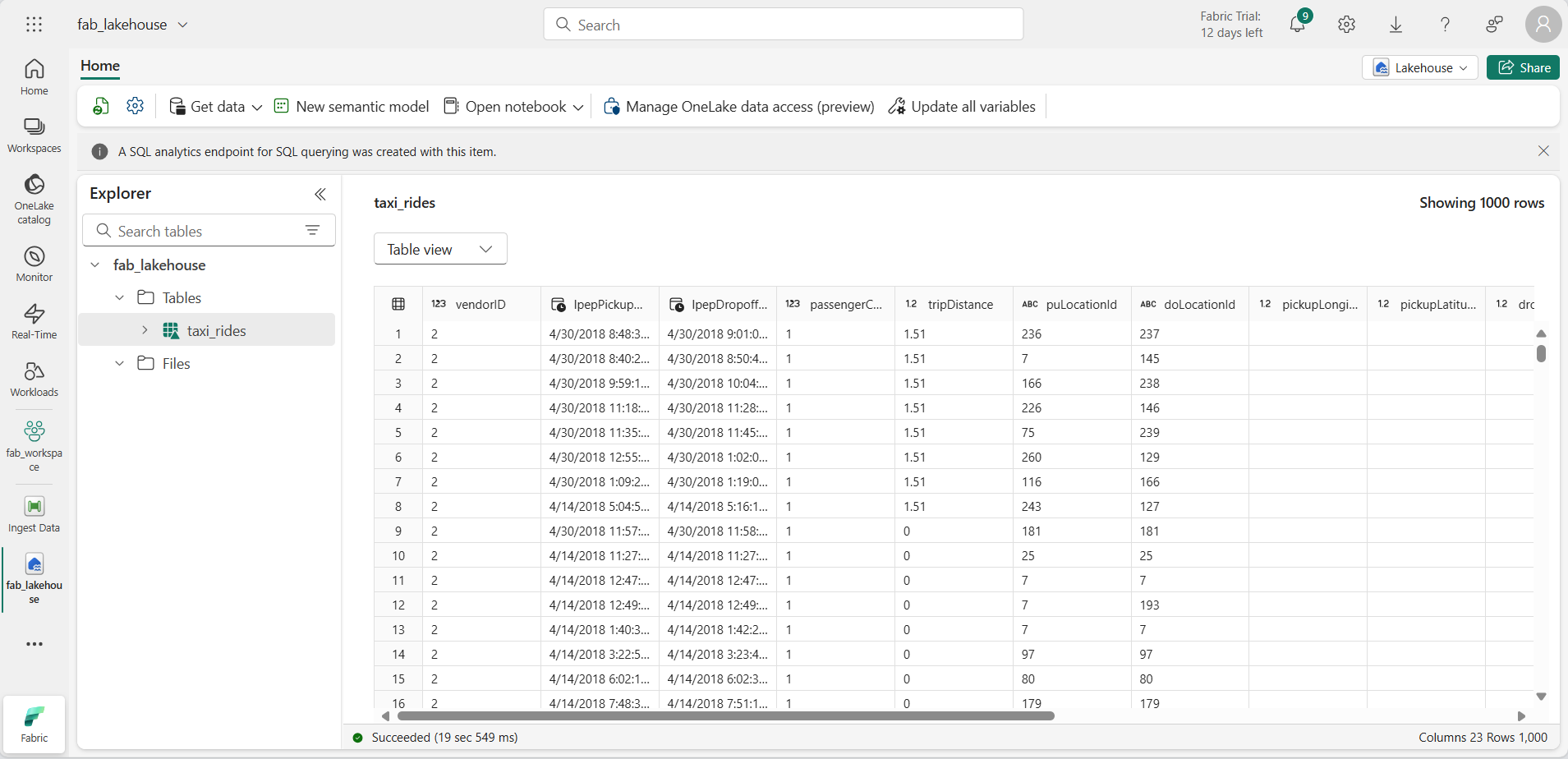
Выберите таблицу taxi_rides , чтобы просмотреть ее содержимое.
Запрос данных в озере данных
Теперь, когда вы получили данные в таблицу в озере данных, вы можете использовать SQL для его запроса.
Совет. Таблицы Lakehouse являются понятными для SQL. Вы можете сразу анализировать данные, не перемещая их в другую систему.
-
В правом верхнем углу страницы Lakehouse перейдите из представления Lakehouse в конечную точку аналитики SQL для озера.
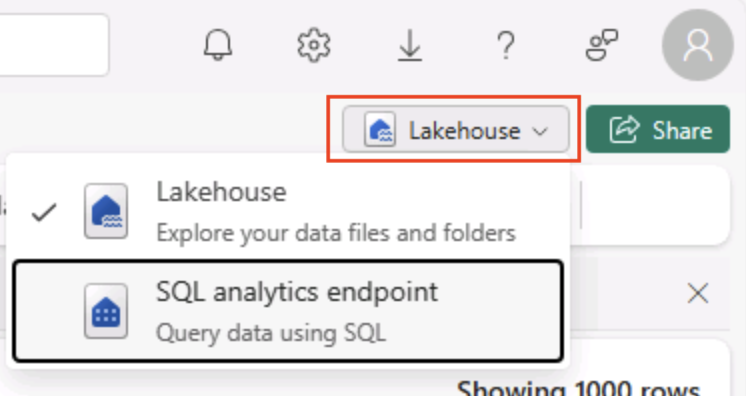
Совет. Конечная точка аналитики SQL оптимизирована для выполнения запросов SQL по таблицам Lakehouse и интегрируется с знакомыми инструментами запросов.
-
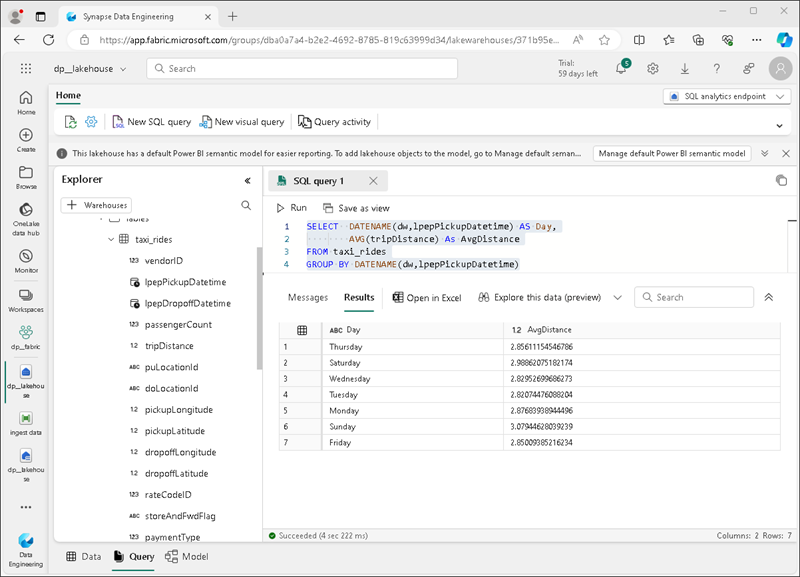
На панели инструментов выберите Новый SQL-запрос. Введите в редактор запросов следующий код SQL:
SELECT DATENAME(dw,lpepPickupDatetime) AS Day, AVG(tripDistance) As AvgDistance FROM taxi_rides GROUP BY DATENAME(dw,lpepPickupDatetime) -
Выберите ▷ Нажмите кнопку запуска, чтобы запустить запрос и просмотреть результаты, которые должны включать среднее расстояние поездки для каждого дня недели.
Совет. Этот запрос группирует поездки по имени дня и вычисляет среднее расстояние, показывающее простой пример агрегирования, на котором можно построить.
Очистка ресурсов
По окончании изучения Microsoft Fabric можно удалить рабочую область, созданную для этого упражнения.
Совет. Удаление рабочей области удаляет все элементы, созданные в лаборатории, и помогает предотвратить текущие расходы.
-
На панели слева выберите значок рабочей области, чтобы просмотреть все содержащиеся в ней элементы.
-
На панели инструментов выберите параметры рабочей области.
-
В разделе “Общие” выберите “Удалить эту рабочую область”.