Изучение аналитики данных в Azure с помощью Azure Synapse Analytics
В этом упражнении вы подготовите к работе рабочую область Azure Synapse Analytics в своей подписке Azure и будете использовать ее для приема и запроса данных.
Выполнение этого задания займет около 30 минут.
Перед началом работы
Вам потребуется подписка Azure с доступом уровня администратора.
Подготовьте рабочую область Azure Synapse Analytics
Чтобы использовать Azure Synapse Analytics, необходимо подготовить ресурс рабочей области Azure Synapse Analytics в подписке Azure.
-
Войдите на портал Azure по адресу https://portal.azure.com, используя учетные данные, связанные с вашей подпиской Azure.
Совет. Убедитесь, что работаете в каталоге, содержащем вашу подписку. Он указан в правом верхнем углу под идентификатором пользователя. В противном случае нажмите значок пользователя и переключите каталог.
- На портале Azure на домашней странице используйте значок + Создать ресурс, чтобы создать новый ресурс.
Azure Synapse AnalyticsВыполните поиск и создайте новый ресурс Azure Synapse Analytics со следующими параметрами:- Подписка: ваша подписка Azure
- Группа ресурсов — создайте новую группу ресурсов с подходящим именем, например “synapse-rg”.
- Управляемая группа ресурсов — введите подходящее имя, например “synapse-managed-rg”.
- Имя рабочей области — *введите уникальное имя рабочей области, например “synapse-ws-<ваше_имя>"*.
- Регион: выберите любой из следующих регионов:
- Восточная Австралия
- Центральная часть США
- Восточная часть США 2
- Северная Европа
- Центрально-южная часть США
- Юго-Восточная Азия
- южная часть Соединенного Королевства
- Западная Европа
- западная часть США
- WestUS 2
- Выбор Data Lake Storage 2-го поколения — из подписки.
- Имя учетной записи — *создайте новую учетную запись с уникальным именем, например “datalake
".* - Имя файловой системы — *создайте новую файловую систему с уникальным именем, например “fs
".*
- Имя учетной записи — *создайте новую учетную запись с уникальным именем, например “datalake
Примечание. Для рабочей области Synapse Analytics требуются две группы ресурсов в подписке Azure: одна для ресурсов, явно создаваемых вами, а другая — для управляемых ресурсов, используемых службой. Для нее также необходима учетная запись хранения Data Lake, в которой она будет хранить данные, скрипты и другие артефакты.
- Подписка: ваша подписка Azure
- После ввода этих сведений выберите Просмотр и создание, а затем выберите Создать, чтобы создать рабочую область.
- Дождитесь создания рабочей области. Это займет около пяти минут.
- После завершения развертывания перейдите к созданной группе ресурсов и обратите внимание, что она содержит рабочую область Synapse Analytics и учетную запись хранения Data Lake.
- Выберите рабочую область Synapse и на странице Обзор в карточке Открыть Synapse Studio выберите Открыть, чтобы открыть Synapse Studio на новой вкладке браузера. Synapse Studio — это веб-интерфейс, с помощью которого можно использовать рабочую область Synapse Analytics.
-
В левой части Synapse Studio используйте значок ››, чтобы развернуть меню. Будут показаны различные страницы в Synapse Studio для управления ресурсами и выполнения задач аналитики данных, как показано ниже:
Прием данных
Одной из основных задач, которые можно выполнить с помощью Azure Synapse Analytics, является определение конвейеров, которые передают (и при необходимости преобразуют) данные из широкого диапазона источников в рабочую область для анализа.
- На домашней странице Synapse Studio выберите Прием, чтобы открыть средство Копирование данных.
- В средстве “Копирование данных” на шаге Свойства убедитесь, что выбран параметр Встроенная задача копирования и Запустить сейчас один раз, а затем нажмите кнопку Далее >.
- На шаге Источник во вложенном шаге Набор данных выберите следующие параметры:
- Тип источника: все
- Подключение:создайте новое подключение и на появившейся панели Новое подключение выберите HTTP на вкладке Общий протокол. Затем нажмите “Продолжить” и создайте подключение к файлу данных со следующими параметрами:
- Имя:
AdventureWorks Products - Description (Описание):
Product list via HTTP - Подключить через среду выполнения интеграции — AutoResolveIntegrationRuntime.
- Базовый URL-адрес —
https://raw.githubusercontent.com/MicrosoftLearning/DP-900T00A-Azure-Data-Fundamentals/master/Azure-Synapse/products.csv. - Проверка сертификата сервера — включите.
- Тип проверки подлинности — анонимный.
- Имя:
- После создания подключения во вложенном шаге Источник/набор данных убедитесь, что выбраны следующие параметры, а затем выберите Далее >:
- Относительный URL-адрес — оставьте пустым.
- Метод запроса: GET
- Дополнительные заголовки — оставьте пустым.
- Двоичное копирование — не выбрано.
- Время ожидания запроса — оставьте пустым.
- Максимальное число одновременных подключений — оставьте пустым.
- На шаге источник во вложенном шаге Конфигурация выберите Предварительный просмотр данных, чтобы просмотреть данные о продуктах, которые будет принимать конвейер, а затем закройте предварительный просмотр.
- После предварительного просмотра данных на шаге Источник/конфигурация убедитесь, что выбраны следующие параметры, а затем выберите Далее >:
- Формат файла: DelimitedText
- Разделитель столбцов: Запятая (,)
- Разделитель строк — перевод строки (\n).
- Первая строка как заголовок — выбрано.
- Тип сжатия: Нет
- На шаге Назначение на вложенном шаге Набор данных выберите следующие параметры.
- Тип целевого объекта: Azure Data Lake Storage 2-го поколения.
- Подключение: выберите существующее подключение к хранилищу озера данных (оно было создано при создании рабочей области).
- Выбрав подключение, на шаге Назначение и набор данных убедитесь, что выбраны следующие параметры, и щелкните Далее >.
- Путь к папке — перейдите к папке файловой системы.
- Имя файла — products.csv.
- Поведение копирования: нет.
- Максимальное число одновременных подключений — оставьте пустым.
- Размер блока (МБ) — оставьте пустым.
- На шаге Назначение на вложенном шаге Конфигурация убедитесь, что выбраны следующие свойства. Затем выберите Далее >:
- Формат файла: DelimitedText
- Разделитель столбцов: Запятая (,)
- Разделитель строк — перевод строки (\n).
- Добавить заголовок в файл — выбрано.
- Тип сжатия: Нет
- Максимальное число строк на файл — оставьте пустым.
- Префикс имени файла — оставьте пустым.
- На шаге Настройки укажите следующие сведения, а затем нажмите кнопку Далее >:
- Имя задачи — “Копирование продуктов”.
- Описание задачи — “Копирование данных продуктов”.
- Отказоустойчивость — оставьте пустым.
- Включить ведение журнала: не выбрано.
- Включить промежуточное хранение — не выбрано.
- На шаге Проверка и завершение на вложенном шаге Проверка прочтите сводку и нажмите кнопку Далее >.
- На вложенном шаге Развертывание дождитесь развертывания конвейера и щелкните Готово.
- Откройте в Synapse Studio страницу Монитор и на вкладке Запуски конвейера дождитесь завершения конвейера Копирование продуктов с состоянием Выполнено (чтобы обновить состояние, используйте на странице запусков конвейера кнопку ↻ Обновить).
-
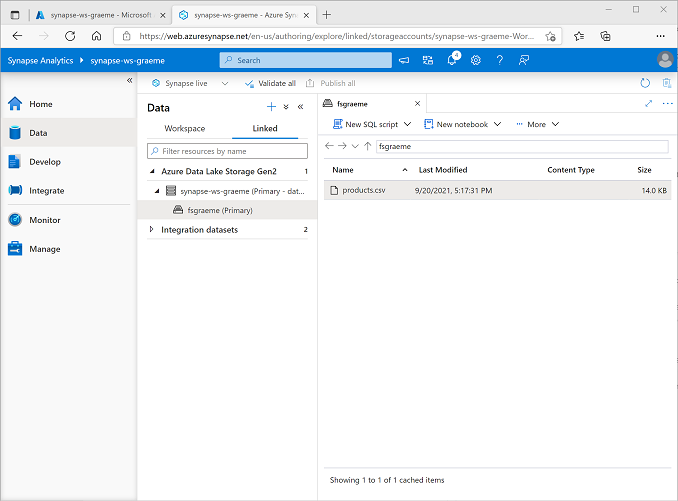
На странице Данные выберите вкладку Связанные и разворачивайте иерархию Azure Data Lake Storage 2-го поколения до тех пор, пока не появится хранилище файлов для рабочей области Synapse. Затем выберите хранилище файлов, чтобы убедиться, что файл с именем products.csv скопирован в это расположение, как показано ниже:
Использование пула SQL для анализа данных
Теперь, когда вы приняли данные в рабочую область, вы можете использовать Synapse Analytics для запросов и анализа. Одним из наиболее распространенных способов для запроса данных является использование SQL. В Synapse Analytics можно использовать пул SQL для выполнения кода SQL.
- В Synapse Studio щелкните правой кнопкой мыши файл products.csv в хранилище файлов для рабочей области Synapse, наведите указатель на пункт Новый скрипт SQL и выберите Выбрать первые 100 строк.
-
В открывшейся области Сценарий SQL 1 проверьте созданный код SQL, который должен выглядеть примерно так:
-- This is auto-generated code SELECT TOP 100 * FROM OPENROWSET( BULK 'https://datalakexx.dfs.core.windows.net/fsxx/products.csv', FORMAT = 'CSV', PARSER_VERSION='2.0' ) AS [result]Этот код открывает набор строк из импортированного текстового файла и извлекает первые 100 строк данных.
- Убедитесь, что в списке Подключение к выбрано значение Встроенный — это встроенный пул SQL, который был создан в рабочей области.
-
На панели инструментов используйте кнопку ▷ Выполнить, чтобы выполнить код SQL, и просмотрите результаты, которые должны выглядеть примерно так:
C1 c2 c3 c4 ProductID НаименованиеПродукта Категория ПрейскурантнаяЦена 771 Mountain-100 Silver, 38 Горные велосипеды 3399.9900 772 Mountain-100 Silver, 42 Горные велосипеды 3399.9900 … … … … -
Обратите внимание, что результаты состоят из четырех столбцов с именами C1, C2, C3 и C4, и что первая строка в результатах содержит имена полей данных. Чтобы устранить эту проблему, добавьте в функцию OPENROWSET параметры HEADER_ROW = TRUE, как показано ниже (замените datalakexx и fsxx на имена учетной записи хранения озера данных и файловой системы), а затем повторно выполните запрос:
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://datalakexx.dfs.core.windows.net/fsxx/products.csv', FORMAT = 'CSV', PARSER_VERSION='2.0', HEADER_ROW = TRUE ) AS [result]Теперь результаты выглядят следующим образом:
ProductID НаименованиеПродукта Категория ПрейскурантнаяЦена 771 Mountain-100 Silver, 38 Горные велосипеды 3399.9900 772 Mountain-100 Silver, 42 Горные велосипеды 3399.9900 … … … … -
Измените запрос следующим образом (заменив datalakexx и fsxx именами учетной записи хранения озера данных и файловой системы):
SELECT Category, COUNT(*) AS ProductCount FROM OPENROWSET( BULK 'https://datalakexx.dfs.core.windows.net/fsxx/products.csv', FORMAT = 'CSV', PARSER_VERSION='2.0', HEADER_ROW = TRUE ) AS [result] GROUP BY Category; -
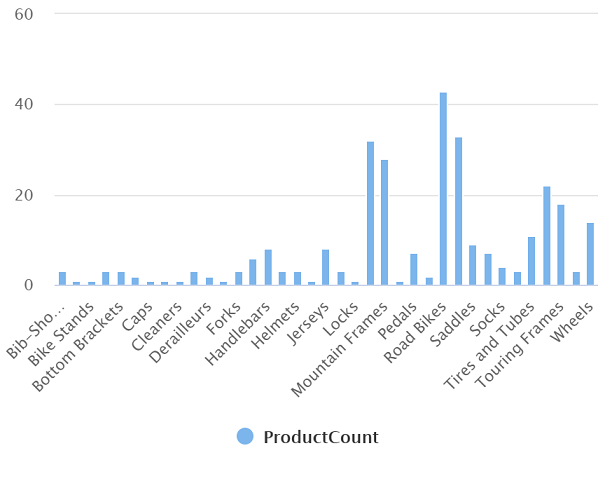
Выполните измененный запрос, который должен возвращать результирующий набор, содержащий количество продуктов в каждой категории, например:
Категория ProductCount Велошорты 3 Багажники для велосипедов 1 … … -
В области свойств** скрипта SQL 1 измените **имя
Count Products by Categoryна . Затем на панели инструментов выберите Опубликовать, чтобы сохранить скрипт. -
Закройте панель скриптов Подсчет продуктов по категориям.
-
В Synapse Studio выберите страницу Разработка и обратите внимание, что в ней был сохранен скрипт SQL Подсчет продуктов по категориям.
-
Выберите скрипт SQL Подсчет продуктов по категориям, чтобы снова открыть его. Затем убедитесь, что скрипт подключен к встроенному пулу SQL и запустите его для получения количества продуктов.
- В области Результаты выберите представление Диаграмма, а затем выберите следующие параметры диаграммы:
- Тип диаграммы — гистограмма.
- Столбец категории — категория.
- Столбцы условных обозначений (рядов) — ProductCount.
- Расположение условных обозначений — снизу по центру.
- Метка условных обозначений (рядов) — оставьте пустым.
- Минимальное значение условных обозначений (рядов) — оставьте пустым.
- Максимальное значение условных обозначений (рядов) — оставьте пустым.
- Метка категории — оставьте пустым.
В итоге диаграмма должна выглядеть примерно так:
Использование пула Spark для анализа данных
Хотя SQL является стандартным языком для запросов к структурированным наборам данных, многие специалисты по анализу и обработке данных находят такие языки, как Python, полезными для изучения и подготовки данных для анализа. В Azure Synapse Analytics можно выполнять код Python (и другой) в пуле Spark. который использует распределенный механизм обработки данных на основе Apache Spark.
- В Synapse Studio выберите страницу Управление.
- Перейдите на вкладку Пулы Apache Spark, а затем используйте значок + Создать, чтобы создать новый пул Spark со следующими параметрами:
- Имя пула Apache Spark — spark
- Семейство размеров узла — оптимизированные для операций в памяти.
- Размер узла — малый (4 виртуальных ядра, 32 ГБ).
- Автомасштабирование — включено.
- Количество узлов — 3—-3.
- Просмотрите и создайте пул Spark, а затем дождитесь его развертывания (это может занять несколько минут).
- После развертывания пула Spark в Synapse Studio на странице Данные перейдите в файловую систему для рабочей области Synapse. Затем щелкните правой кнопкой мыши products.csv, наведите указатель на пункт Создать записную книжку и выберите Загрузка в DataFrame.
- В открывшейся области Записная книжка 1 в списке Присоединить выберите созданный ранее пул Spark под названием spark и убедитесь, что для параметра Язык задано значение PySpark (Python).
-
Просмотрите код в первой (и только) ячейке записной книжки, которая должна выглядеть следующим образом:
%%pyspark df = spark.read.load('abfss://fsxx@datalakexx.dfs.core.windows.net/products.csv', format='csv' ## If header exists uncomment line below ##, header=True ) display(df.limit(10)) -
Нажмите #9655; Запуск слева от ячейки кода, чтобы запустить ее, и дождитесь результата. При первом запуске ячейки в записной книжке пул Spark запускается, поэтому для возврата результатов может потребоваться около минуты.
Примечание. Если возникает ошибка из-за того, что ядро Python еще недоступно, запустите ячейку еще раз.
-
В конечном итоге результаты должны появиться под ячейкой и должны выглядеть примерно так:
c0 c1 c2 c3 ProductID НаименованиеПродукта Категория ПрейскурантнаяЦена 771 Mountain-100 Silver, 38 Горные велосипеды 3399.9900 772 Mountain-100 Silver, 42 Горные велосипеды 3399.9900 … … … … -
Раскомментируйте строку ,header=True (так как файл products.csv содержит заголовки столбцов в первой строке), чтобы код выглядел следующим образом:
%%pyspark df = spark.read.load('abfss://fsxx@datalakexx.dfs.core.windows.net/products.csv', format='csv' ## If header exists uncomment line below , header=True ) display(df.limit(10)) -
Запустите ячейку повторно и убедитесь, что результаты выглядят следующим образом:
ProductID НаименованиеПродукта Категория ПрейскурантнаяЦена 771 Mountain-100 Silver, 38 Горные велосипеды 3399.9900 772 Mountain-100 Silver, 42 Горные велосипеды 3399.9900 … … … … Обратите внимание, что повторное выполнение ячейки занимает меньше времени, так как пул Spark уже запущен.
- Под результатами нажмите значок + Код, чтобы добавить новую ячейку кода в записную книжку.
-
В новой пустой ячейке кода добавьте следующий код:
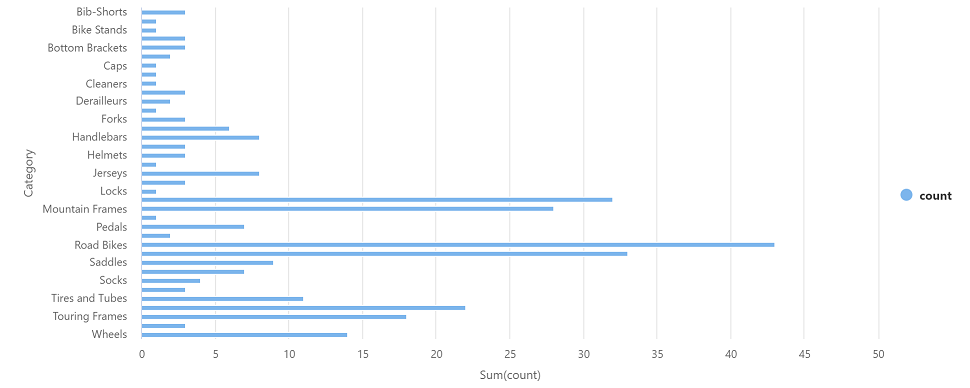
df_counts = df.groupBy(df.Category).count() display(df_counts) -
Нажмите ▷ Запуск слева, чтобы запустить новую ячейку кода. Результат должен выглядеть примерно так:
Категория count Рулевые колонки 3 Колеса 14 … … -
В выходных данных результатов для ячейки выберите представление Диаграмма. В итоге диаграмма должна выглядеть примерно так:
- Закройте область Записная книжка 1 и отклоните изменения.
Удаление ресурсов Azure
Если вы завершили изучение Azure Synapse Analytics, вы должны удалить созданные ресурсы, чтобы избежать ненужных затрат на Azure.
- Закройте вкладку браузера Synapse Studio с открытой страницей GitHub и вернитесь на портал Azure.
- На домашней странице портала Azure выберите Группы ресурсов.
- Выберите группу ресурсов для рабочей области Synapse Analytics (не управляемую группу ресурсов) и убедитесь, что она содержит рабочую область Synapse, учетную запись хранения и пул Spark для вашей рабочей области.
- В верхней части страницы Обзор группы ресурсов выберите Удалить группу ресурсов.
-
Введите имя группы ресурсов, чтобы подтвердить ее удаление, и выберите Удалить.
Через несколько минут рабочая область Azure Synapse и связанная с ней управляемая рабочая область будут удалены.