Знакомство со службой хранилища Azure
В этом упражнении вы узнаете, как подготовить и настроить учетную запись служба хранилища Azure, а также изучите основные службы: хранилище BLOB-объектов, Data Lake Storage 2-го поколения, Файлы Azure и таблицы Azure. Вы получите практический опыт создания контейнеров, отправки данных, включения иерархических пространств имен, настройки общих папок и управления сущностями таблиц. Эти навыки помогут вам понять, как хранить, упорядочивать и защищать нереляционные данные в Azure для различных сценариев аналитики и приложений.
Выполнение этого задания займет около 15 минут.
Совет. Понимание цели каждого действия поможет вам позже разработать решения для хранения, которые балансирует затраты, производительность, безопасность и аналитику. Эти краткие заметки о том, почему каждый шаг привязан к реальной причине.
Перед началом работы
Вам потребуется подписка Azure с доступом уровня администратора.
Подготовка учетной записи службы хранилища Azure
Первый шаг при использовании службы хранилища Azure — подготовка учетной записи службы хранилища Azure в подписке Azure.
Совет. Учетная запись хранения — это безопасная, оплачиваемая граница для всех служб служба хранилища Azure (большие двоичные объекты, файлы, очереди, таблицы). Политики, избыточность, шифрование, сеть и управление доступом применяются отсюда вниз.
-
Если вы еще этого не сделали, войдите на портал Azure.
-
На домашней странице портал Azure выберите &65291; Создайте ресурс в левом верхнем углу и выполните поиск
Storage account. Затем на полученной странице Службы хранилища учетной записи выберите Создать.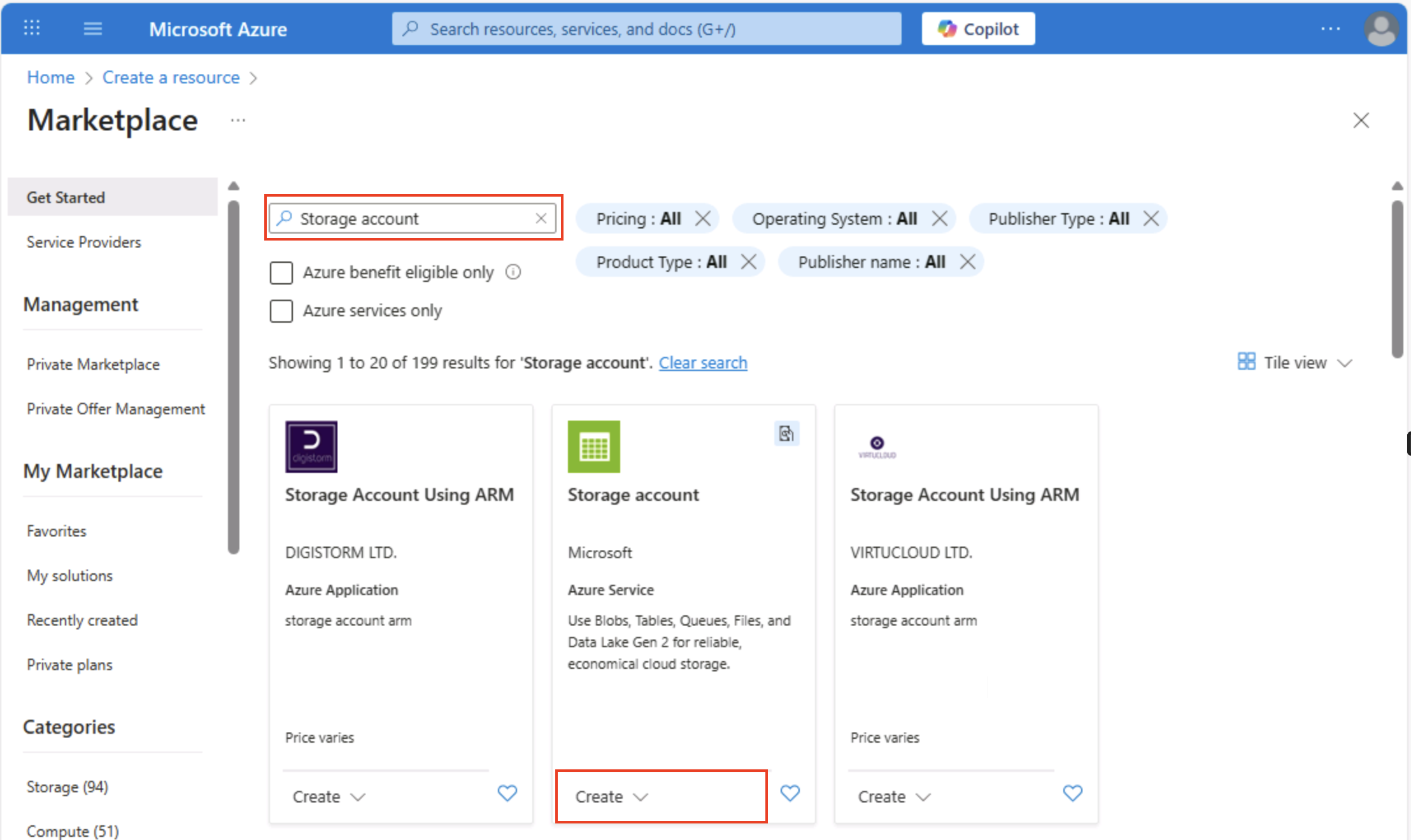
-
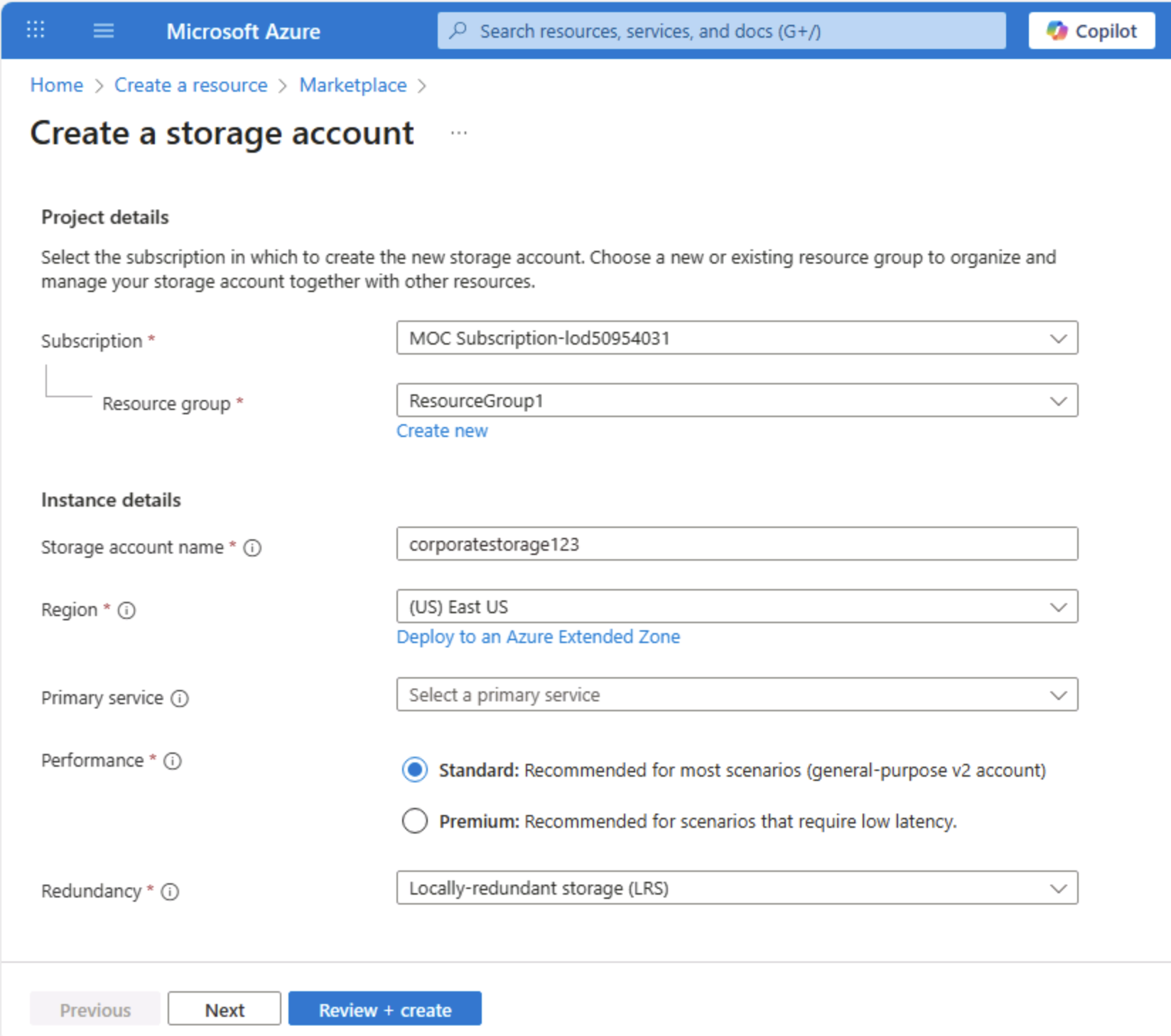
В мастере Создание учетной записи хранения введите приведенные ниже значения:
- Подписка. Выберите подписку Azure.
- Группа ресурсов: создайте группу ресурсов с именем по своему выбору.
- Служба хранилища имя учетной записи: введите уникальное имя для учетной записи хранения, используя буквы и цифры в нижнем регистре.
- Регион: выберите любое доступное расположение.
- Производительность: стандартная
- Избыточность: выберите Локально избыточное хранилище (LRS)
Совет. Новая группа ресурсов упрощает очистку. Стандарт + LRS — это базовый план с наименьшей стоимостью, хорошо подходит для обучения. LRS сохраняет три синхронные копии в одном регионе, достаточно для некритических демонстрационных данных без оплаты георепликации.
-
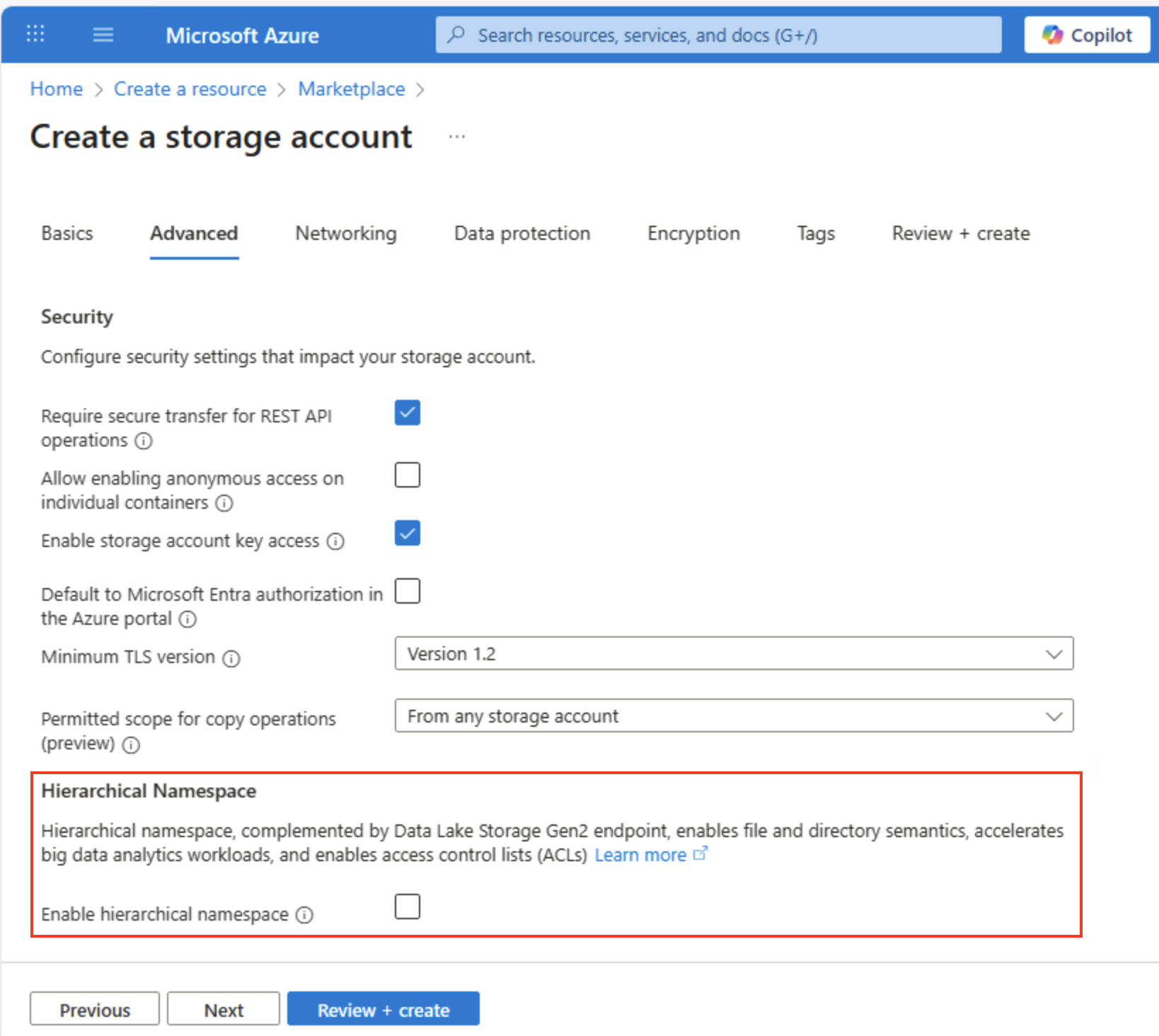
Выберите Далее: Дополнительно > и просмотрите расширенные параметры конфигурации. В частности, обратите внимание, что в этом случае можно включить иерархическое пространство имен для поддержки Azure Data Lake Storage 2-го поколения. Оставьте этот параметр невыбранным (он будет включен позже), а затем нажмите Далее: Сеть >, чтобы просмотреть параметры сети для вашей учетной записи хранения.
-
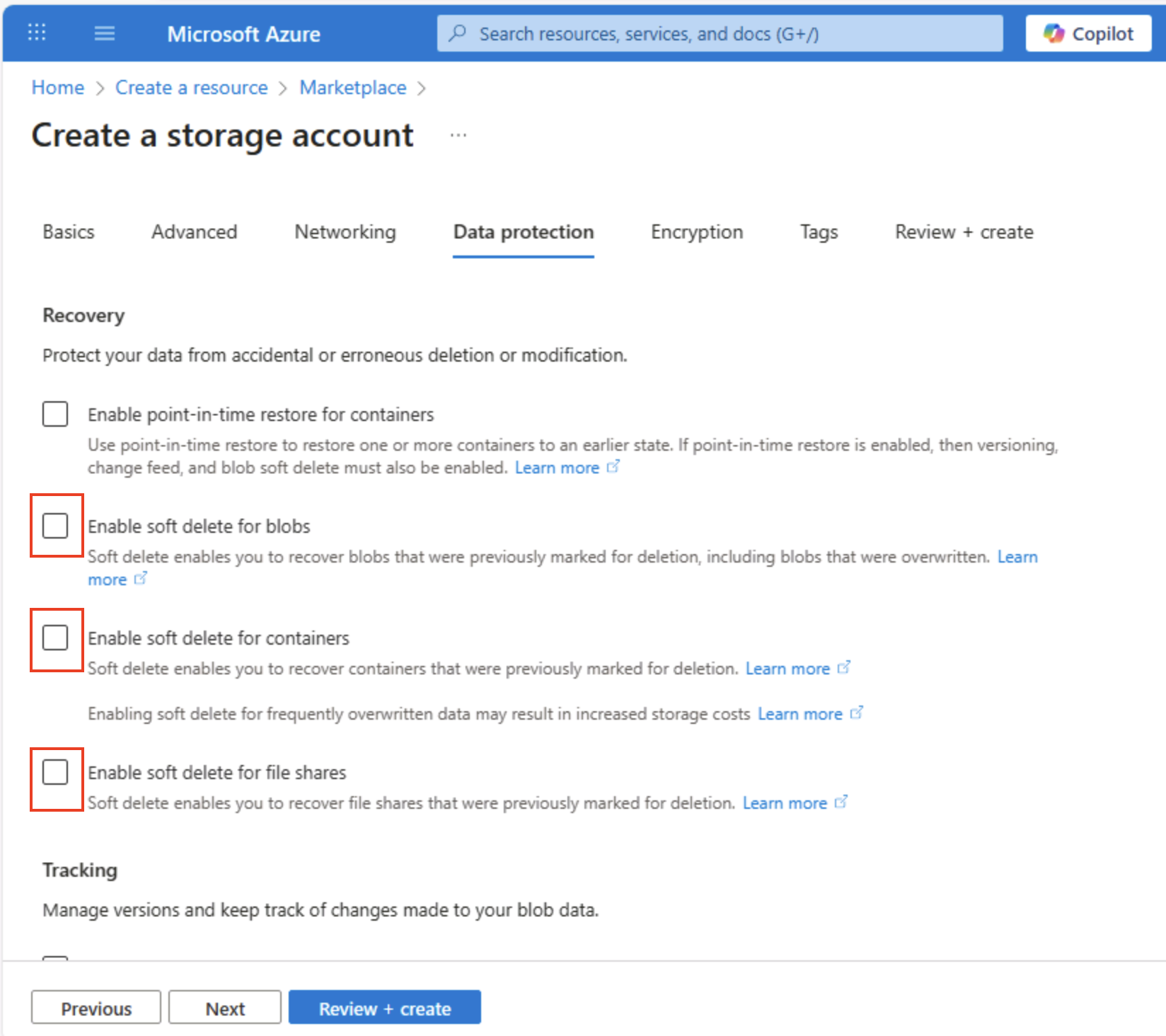
Выберите Далее: Защита данных >, а затем в разделе Восстановление снимите все флажки Включить обратимое удаление…. Эти параметры позволяют хранить удаленные файлы для последующего восстановления, но могут вызвать проблемы позже при включении иерархического пространства имен.
-
Листайте оставшиеся страницы, нажимая Далее > и не меняя параметры по умолчанию, а затем на странице Проверка дождитесь подтверждения своих настроек и выберите Создать. Ваша учетная запись хранения Azure будет создана.
-
Дождитесь завершения развертывания. Затем перейдите к развернутому ресурсу.
Исследуйте хранилище BLOB-объектов
Теперь, когда у вас есть учетная запись службы хранилища Azure, можно создать контейнер для данных BLOB-объектов.
Совет. Большие двоичные объекты групп контейнеров и первый уровень области для управления доступом. Начиная с обычного хранилища BLOB-объектов (без иерархического пространства имен) отображается поведение виртуальной папки, по сравнению с Data Lake 2-го поколения позже.
-
Скачайте JSON-файл product1.json из
https://aka.ms/product1.jsonи сохраните его на компьютере (его можно сохранить в любой папке — вы сможете отправить его в хранилище BLOB-объектов позже).Если JSON-файл отображается в браузере, сохраните страницу как product1.json.
-
На странице контейнера хранилища на портале Azure слева в разделе Хранилище данных выберите Контейнеры.
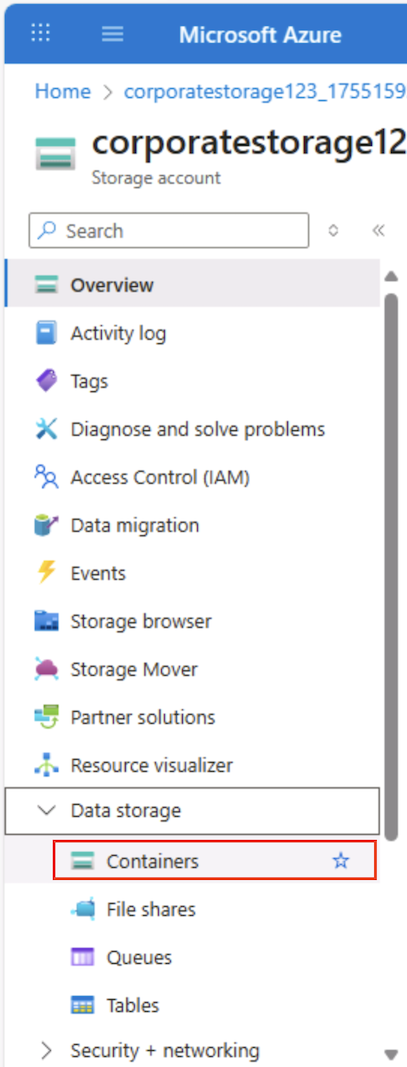
-
На странице “Контейнеры” выберите + Добавьте контейнер и добавьте новый контейнер
dataс анонимным уровнем доступа частного (без анонимного доступа).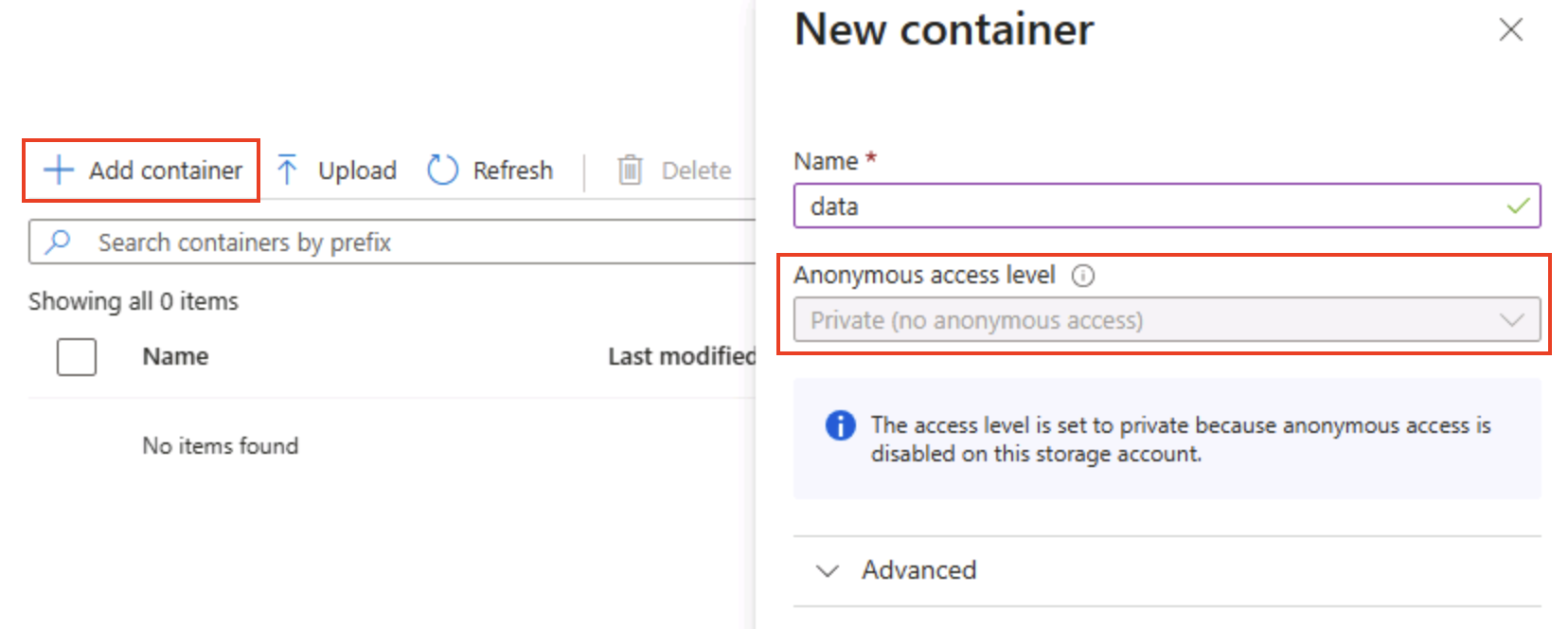
Совет. Приватный обеспечивает безопасность примеров данных. Общедоступный доступ редко требуется, за исключением статических веб-сайтов или сценариев открытых данных. Именование сохраняет
dataэтот пример простым и читаемым. -
После создания контейнера data убедитесь, что он указан на странице Контейнеры.
-
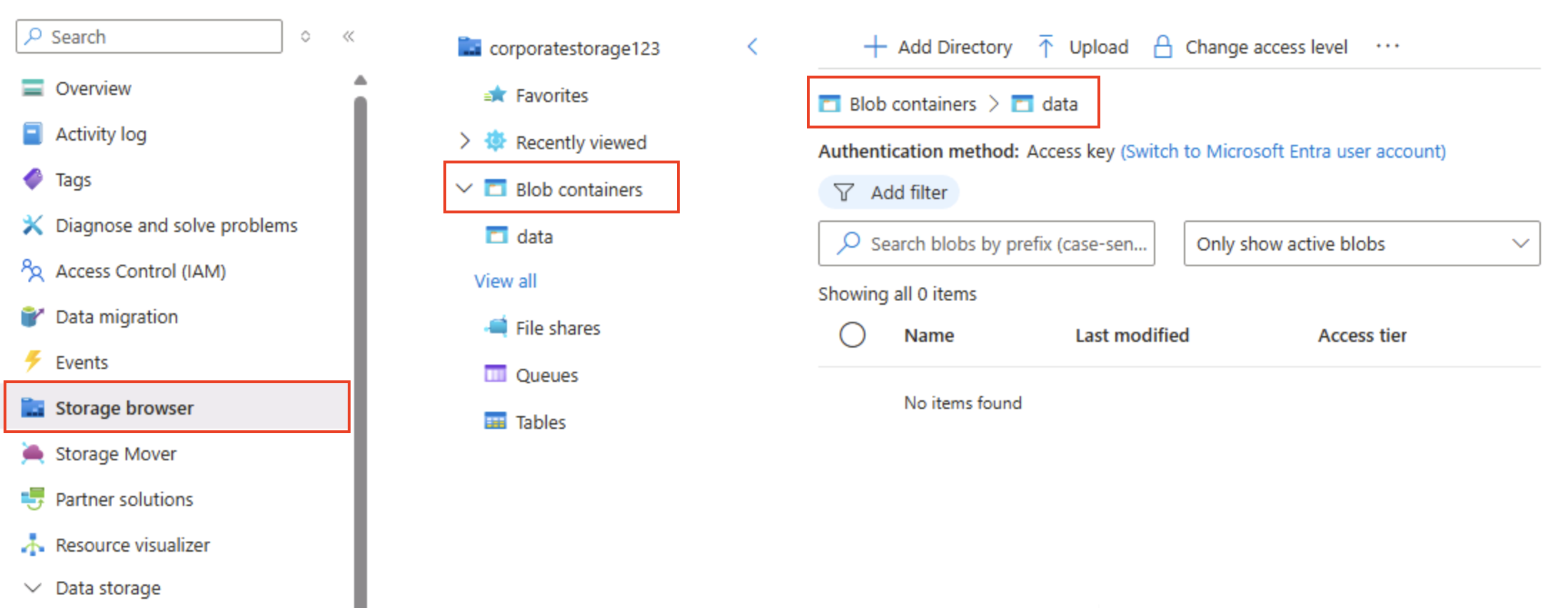
В верхней части области слева выберите Обозреватель хранилища. На этой странице представлен интерфейс на основе браузера, который можно использовать для работы с данными в вашей учетной записи хранения.
-
На странице обозревателя хранилища выберите Контейнеры BLOB-объектов и убедитесь, что контейнер data присутствует в списке.
-
Выберите контейнер data и обратите внимание, что он пуст.
-
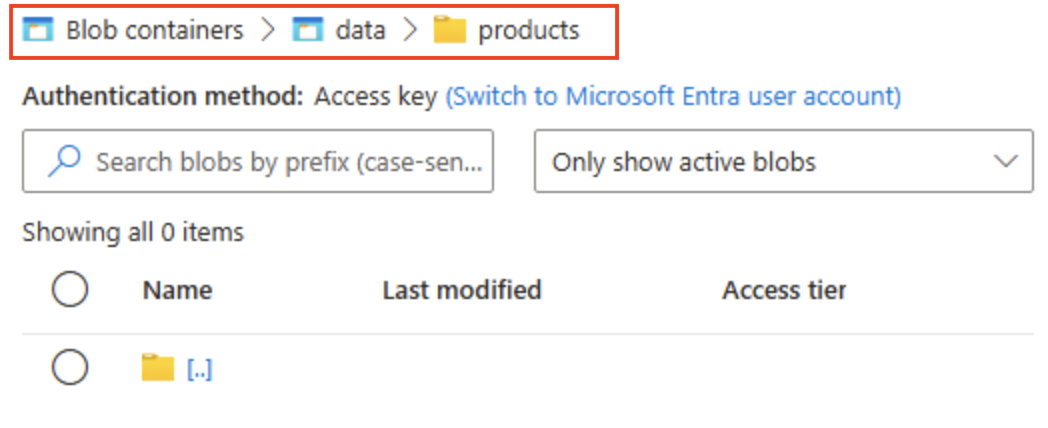
Выберите &65291; Добавьте каталог и прочитайте сведения о папках перед созданием нового каталога с именем
products. -
В обозревателе хранилища убедитесь, что содержимое только что созданной папки products отображается в текущем представлении. Вверху страницы должна быть цепочка навигации Контейнеры BLOB-объектов > data > products.
-
В навигационной цепочка выберите data для переключения в контейнер data и обратите внимание, что она не содержит папку Products.
Папки в хранилище BLOB-объектов являются виртуальными и существуют только как часть пути к BLOB-объекту. Так как папка Products не содержит BLOB-объектов, на самом деле это не так.
Совет. Неструктурированное пространство имен означает, что каталоги являются просто префиксами имен (products/file.json). Эта конструкция позволяет масштабироваться, так как имена БОЛЬШИХ двоичных объектов индексов служб вместо поддержания истинной структуры дерева.
-
Нажмите кнопку ⤒ Отправить, чтобы открыть панель Отправить BLOB-объект.
-
На панели Загрузка BLOB-объектов выберите файл product1.json, сохраненный на локальном компьютере ранее. Затем в разделе “Дополнительно” в поле “Отправить в папку **” введите **
product_dataи нажмите кнопку **“Отправить”.**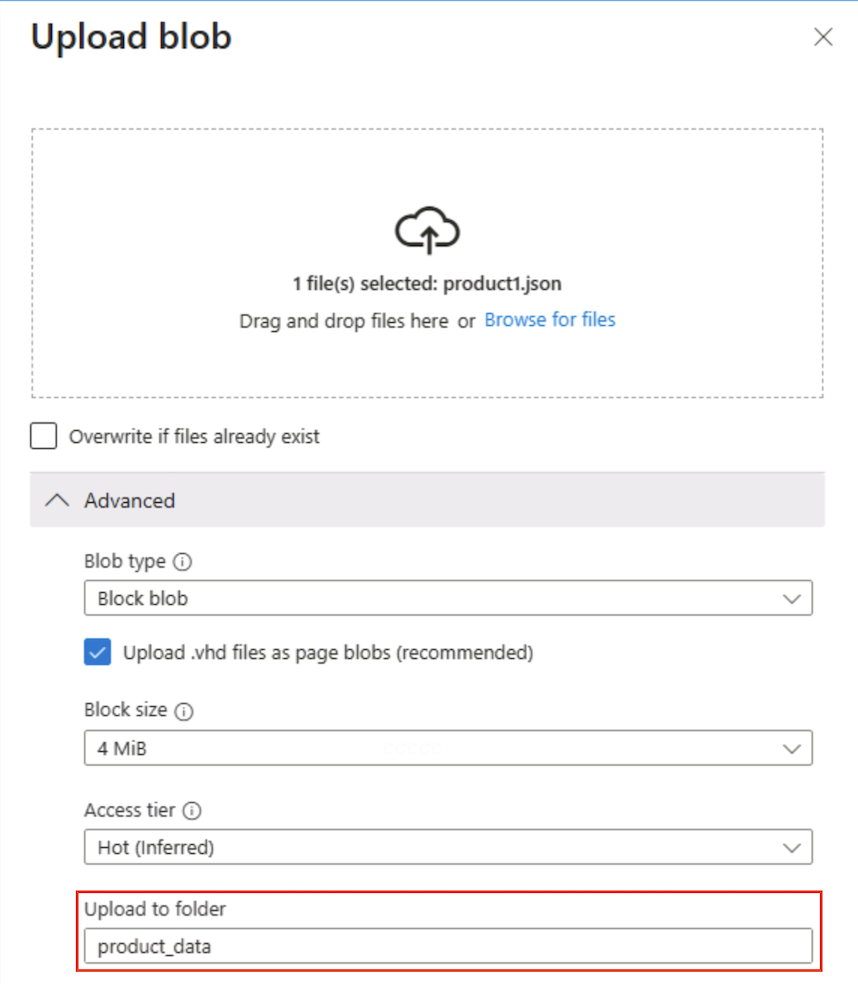
Совет. Указание имени папки при отправке автоматически создает виртуальный путь, иллюстрируя наличие большого двоичного объекта, отображается “папка”.
-
Закройте панель Загрузка BLOB-объектов, если она еще открыта, и убедитесь, что в контейнере data создана product_data виртуальная папка.
-
Выберите папку product_data и убедитесь, что она содержит отправленный BLOB-объект product1.json.
-
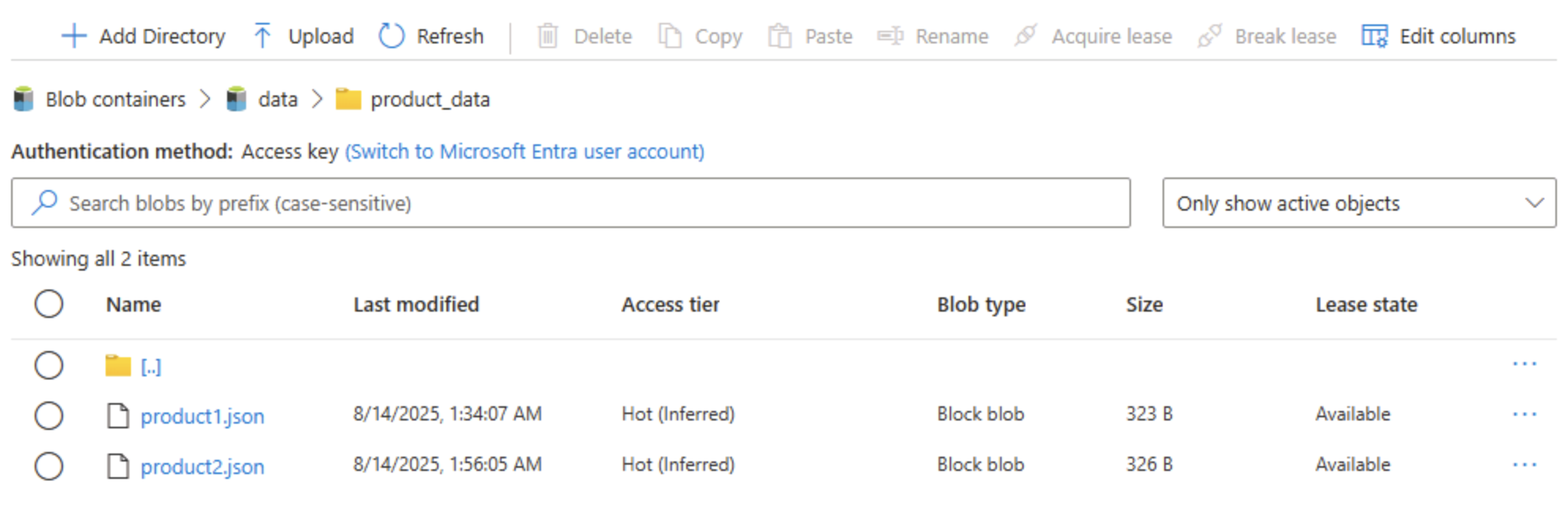
В левой части в разделе Хранилище данных выберите Контейнеры.
-
Откройте контейнер data и убедитесь, что в списке указана созданная папка product_data.
-
Щелкните значок ‧‧‧ с правого края папки и обратите внимание, что никаких функций не отображается. Папки в контейнере BLOB-объектов с неструктурированным пространством имен являются виртуальными, и управлять ими невозможно.
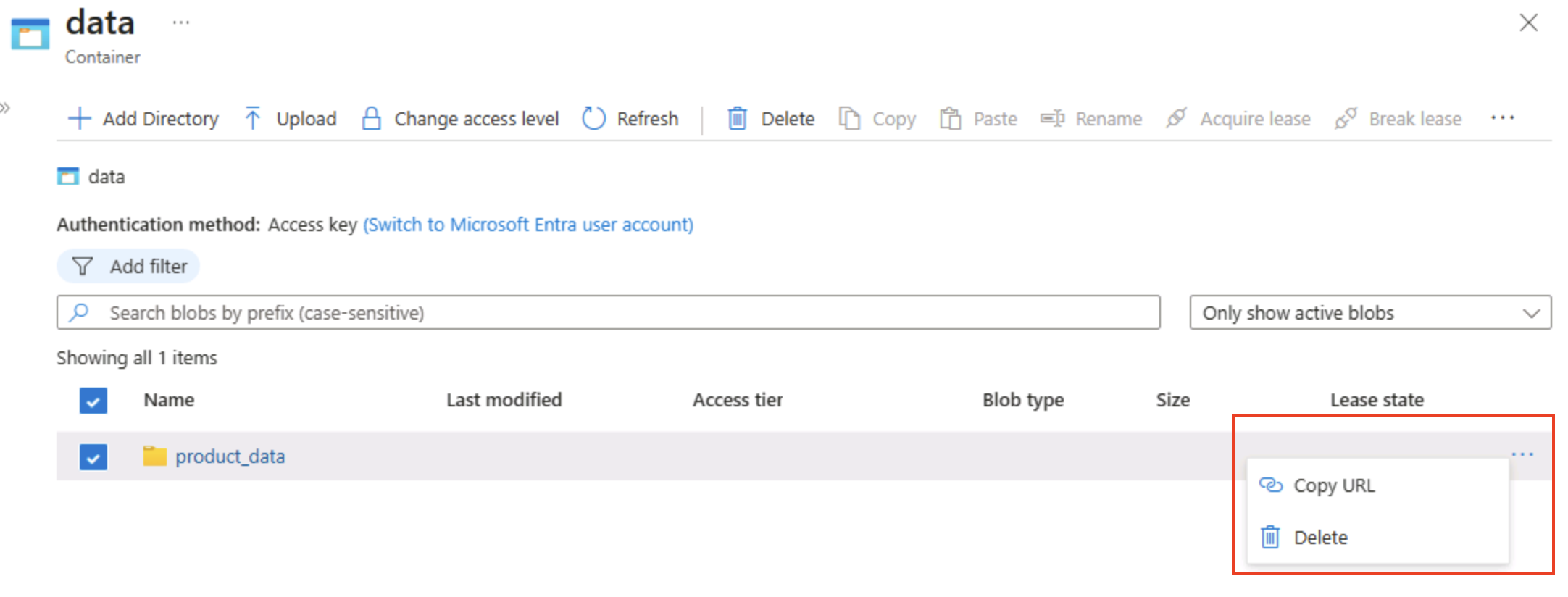
Совет. Нет реального объекта каталога, поэтому для них не требуется иерархическое пространство имен.
-
Используйте значок X в правом верхнем углу страницы data, чтобы закрыть страницу и вернуться на страницу Контейнеры.
Знакомство с Azure Data Lake Storage 2-го поколения
Поддержка Azure Data Lake Store Gen2 позволяет использовать иерархические папки для организации и управления доступом к BLOB-объектам. Она также позволяет использовать хранилище BLOB-объектов Azure для размещения распределенных файловых систем с общими платформами для аналитики больших данных.
Совет. Включение иерархического пространства имен позволяет папкам вести себя как реальные каталоги. Он также позволяет безопасно выполнять действия папок (все одновременно без ошибок) и предоставляет элементы управления разрешениями на файлы, аналогичные элементам управления в Linux. Это особенно полезно при работе с инструментами больших данных, такими как Spark или Hadoop, или при управлении большими, упорядоченными озерами данных.
-
[Скачайте product2.json JSON-файл
https://aka.ms/product2.jsonиз и сохраните его на компьютере в той же папке, в которой вы скачали product1.json](https://aka.ms/product2.json?azure-portal=true) ранее, вы отправите его в хранилище BLOB-объектов позже. -
С левой стороны страницы портала Azure для учетной записи хранения прокрутите экран вниз до раздела Параметры и выберите Обновление Data Lake 2-го поколения.
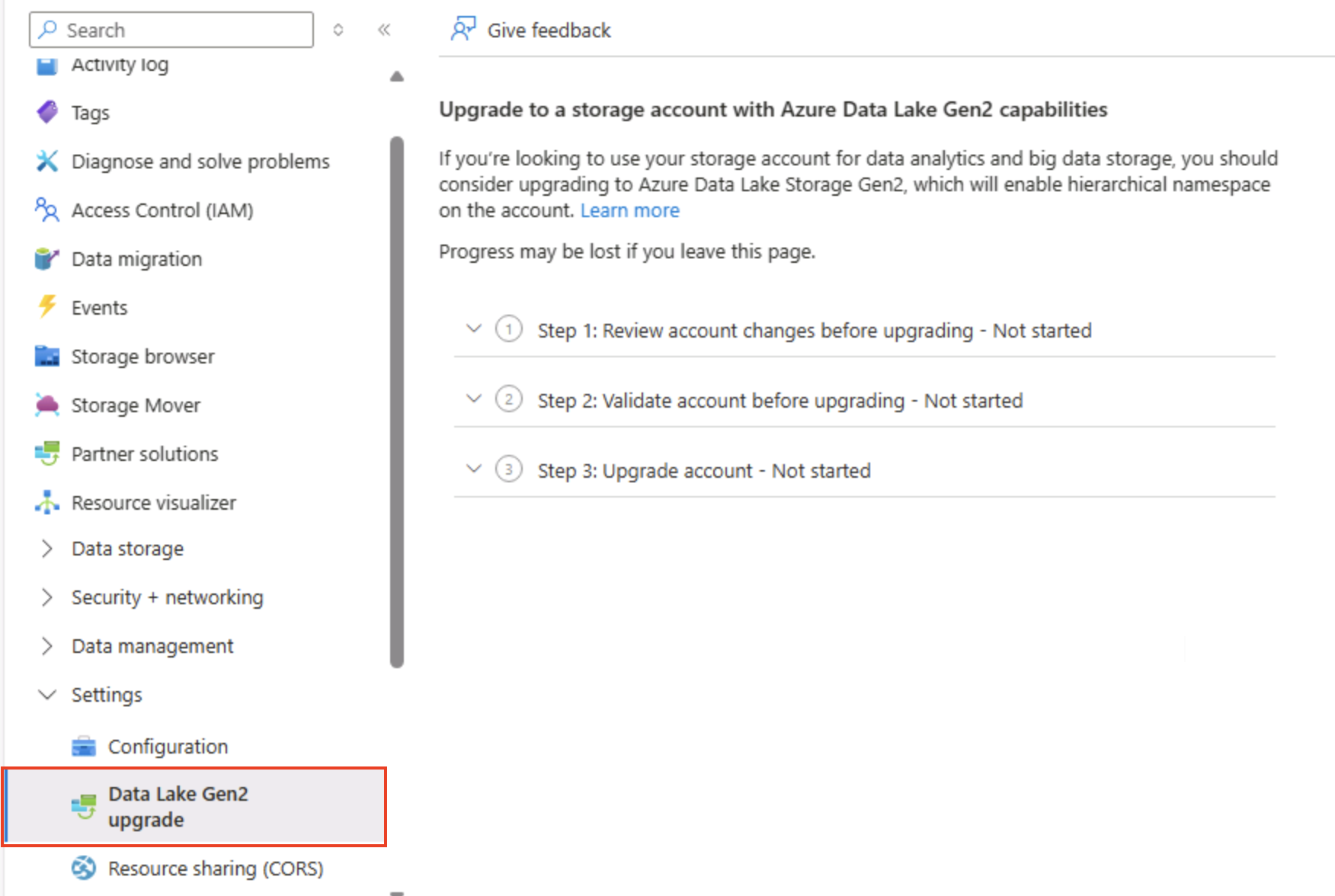
-
На странице обновления Data Lake 2-го поколения разверните и выполните каждый шаг, чтобы обновить учетную запись хранения, чтобы включить иерархическое пространство имен и поддержку Azure Data Lake Storage Gen. Это может занять некоторое время.
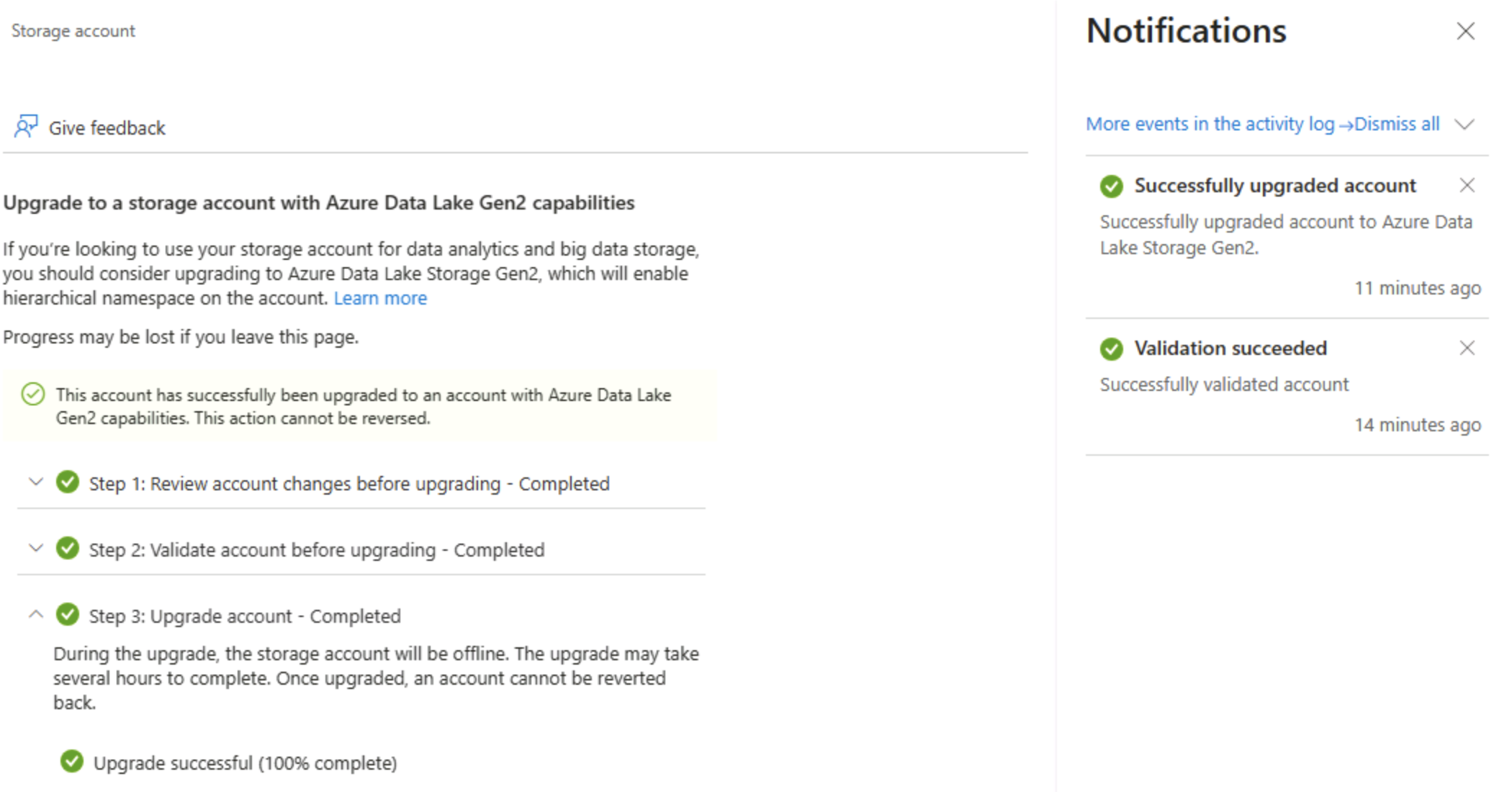
Совет. Обновление — это переключатель возможностей на уровне учетной записи— данные остаются, но семантика каталога изменяется для поддержки расширенных операций.
-
После завершения обновления в верхней части области слева выберите Обозреватель хранилища и вернитесь к корню контейнера BLOB-объектов data, который по-прежнему содержит папку product_data.
-
Выберите папку product_data и убедитесь, что она все еще содержит файл product1.json, который вы ранее перегрузили.
-
Нажмите кнопку ⤒ Отправить, чтобы открыть панель Отправить BLOB-объект.
-
На панели Загрузка BLOB-объектов выберите файл product2.json, сохраненный на локальном компьютере. Затем нажмите кнопку Отправить.
-
Закройте панель Загрузка BLOB-объектов, если она еще открыта, и убедитесь, что в папке product_data теперь есть файл product2.json.
Совет. Добавление второго файла после обновления подтверждает непрерывную непрерывность: существующие большие двоичные объекты по-прежнему работают, а новые получают иерархические преимущества, такие как списки управления доступом к каталогу (контроль доступа списки).
-
В левой части в разделе Хранилище данных выберите Контейнеры.
-
Откройте контейнер data и убедитесь, что в списке указана созданная папка product_data.
-
Щелкните значок ‧‧‧ с правого края папки и обратите внимание, что при включенном иерархическом пространстве имен можно выполнять задачи настройки на уровне папки, в том числе переименование папок и задание разрешений.
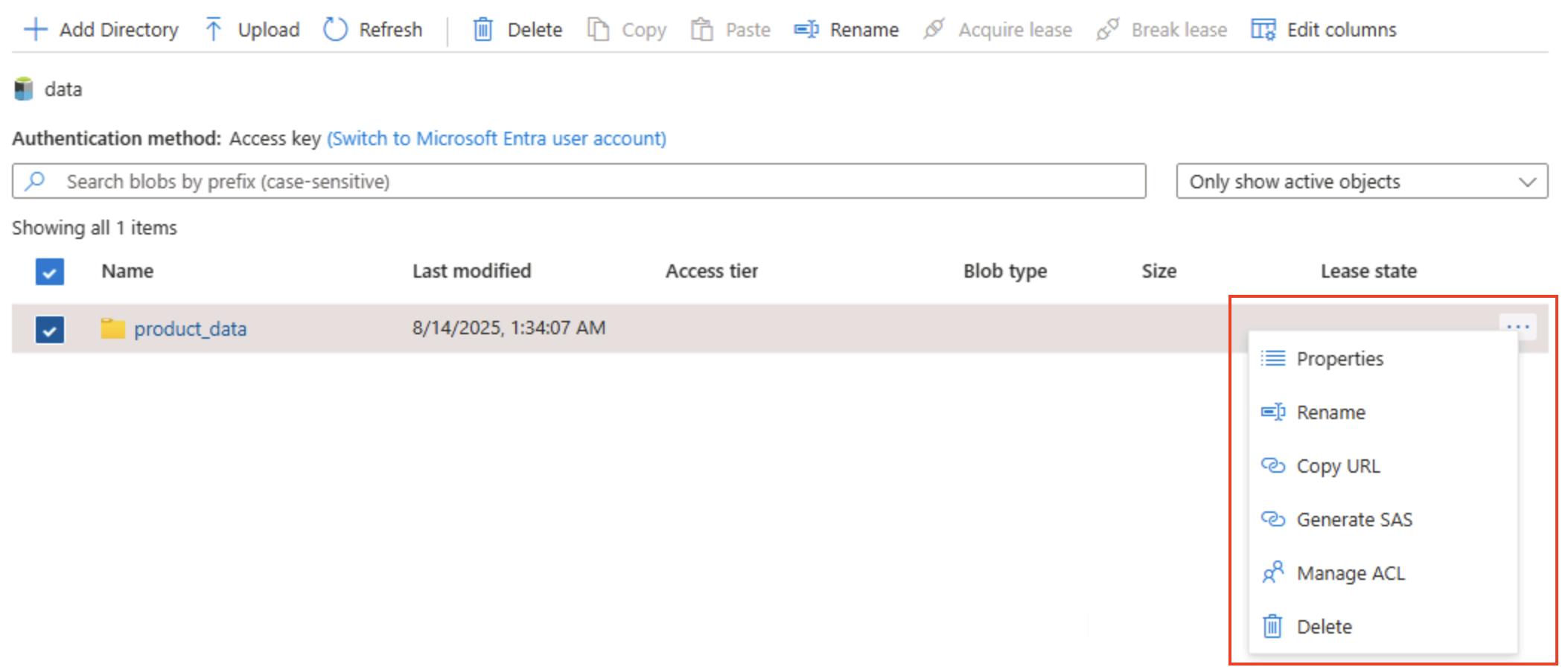
Совет. Реальные папки позволяют применять минимальные привилегии безопасности при детализации папок, переименовывать безопасно и быстро рекурсивные списки и сканировать тысячи префиксированных имен больших двоичных объектов.
-
Используйте значок X в правом верхнем углу страницы data, чтобы закрыть страницу и вернуться на страницу Контейнеры.
Обзор Файлов Azure
Служба Файлов Azure предоставляет способ создания облачных файловых ресурсов.
Совет. Файлы Azure предлагает конечные точки SMB/NFS для сценариев лифта и смены, в которых приложения ожидают традиционную файловую систему. Он дополняет (не заменяет) хранилище BLOB-объектов, поддерживая блокировки файлов и средства на основе ОС.
-
На странице контейнера хранилища на портале Azure слева в разделе Хранилище данных выберите Контейнеры.

-
На странице общих папок выберите &65291; ** Общая папка и добавление новой общей папки с именем
filesс помощью оптимизированного для транзакций **уровня. -
Нажмите кнопку “Далее”: > резервного копирования и отключите резервное копирование. Щелкните Просмотр и создание.
Совет. Отключение резервного копирования экономит затраты на кратковременную лабораторной среде. Это позволит обеспечить устойчивость рабочей среды.
-
В общих файловых ресурсах откройте общую папку.
-
В верхней части страницы выберите Подключение. Затем в области Подключение обратите внимание на наличие вкладок для общих операционных систем (Windows, Linux и macOS), содержащих скрипты, которые можно выполнять для подключения к общей папке с клиентского компьютера.
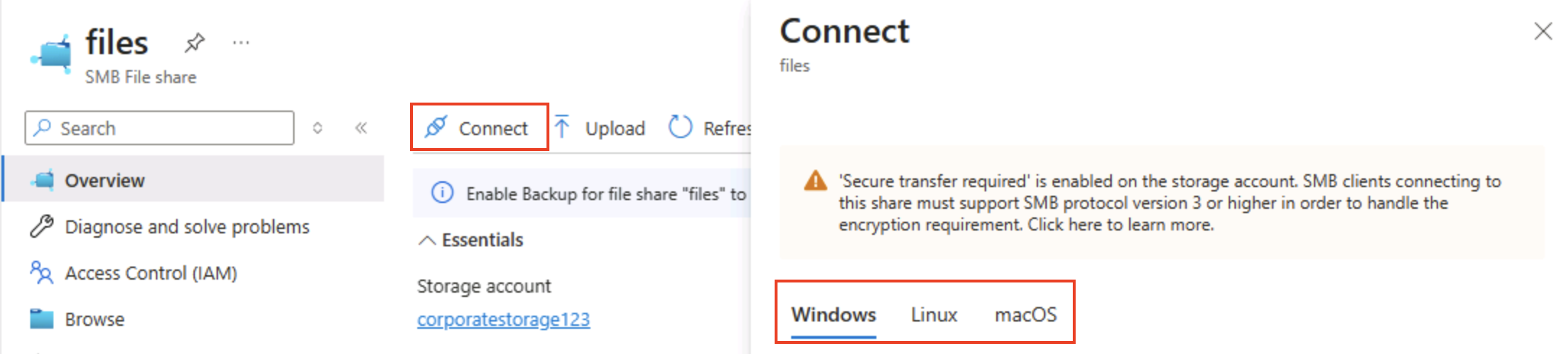
Совет. Созданные скрипты показывают, как подключить общую папку с помощью собственных команд платформы, иллюстрируя шаблоны гибридного доступа с виртуальных машин, контейнеров или локальных серверов.
-
Закройте панель Подключение, а затем закройте страницу files, чтобы вернуться на страницу Общих файловых ресурсов для вашей учетной записи хранения Azure.
Знакомство с Таблицами Azure
Таблицы Azure предоставляют хранилище “ключ/значение” для приложений, которые должны хранить значения данных, но не нуждаются в полной функциональности и структуре реляционной базы данных.
Совет. Хранилище таблиц торгует богатыми запросами и соединениями для ультра-низкой стоимости, гибкости без схемы и горизонтального масштабирования — идеально подходит для журналов, данных Интернета вещей или профилей пользователей.
-
На странице контейнера хранилища на портале Azure слева в разделе Хранилище данных выберите Таблицы.
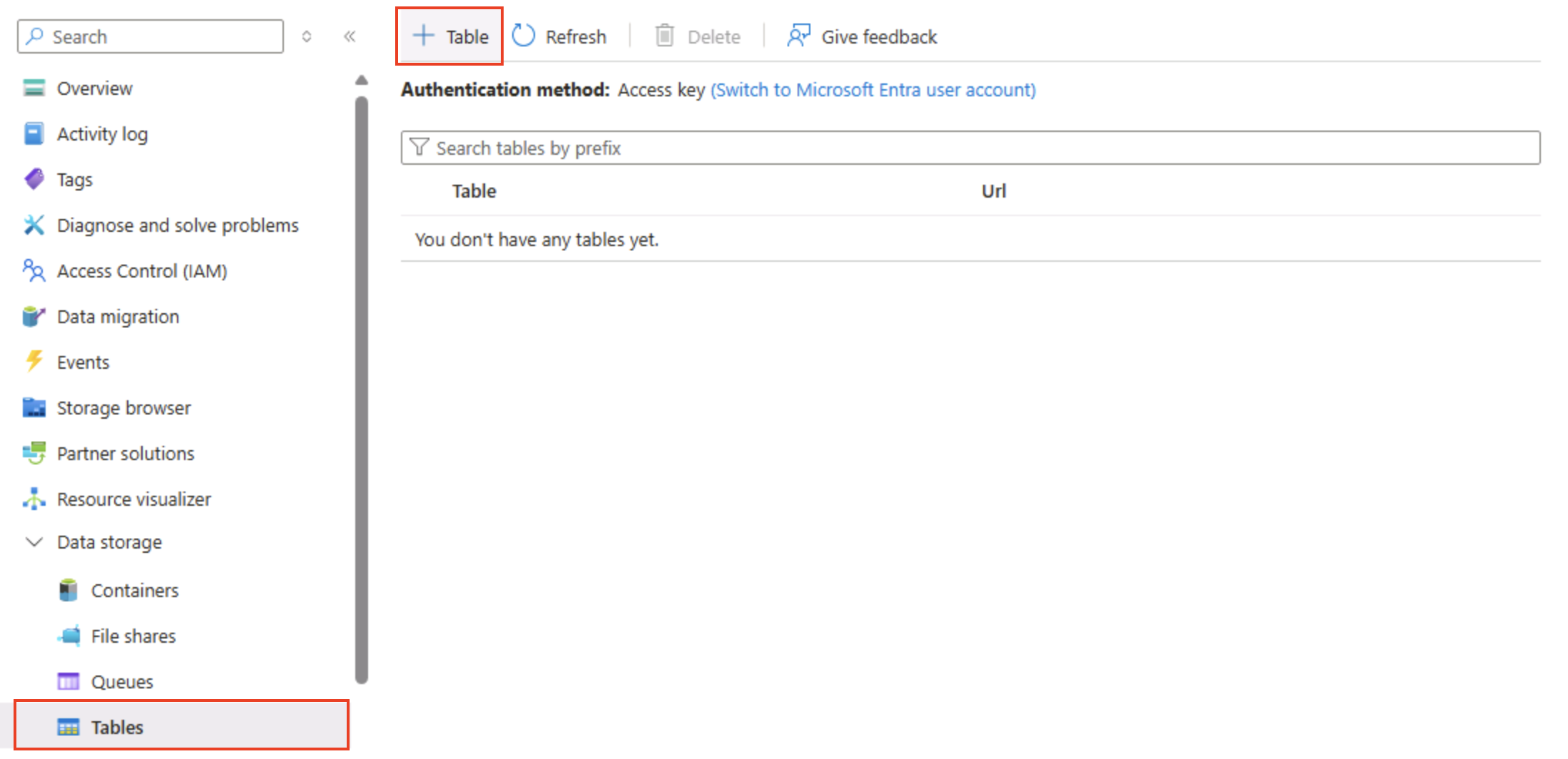
-
На странице “Таблицы” выберите + Таблица и создание новой таблицы с именем
products. -
После создания таблицы products в верхней части области слева выберите Обозреватель хранилища.
-
В обозревателе хранилища выберите Таблицы и убедитесь, что таблица products указана в списке.
-
Выберите таблицу products.
-
На странице products выберите + Добавление сущности.
- На панели Добавить сущность введите следующие значения ключей:
- PartitionKey: 1
- RowKey: 1
Совет. Секционирование групп, связанных с сущностями для распределения нагрузки; RowKey однозначно идентифицирует в разделе. Вместе они образуют быстрый составной первичный ключ для поиска.
-
Выберите “ Добавить свойство” и создайте два новых правильных значения со следующими значениями:
Имя свойства Тип значение Имя. Строка Мини-приложение Цена, Двойной 2,99 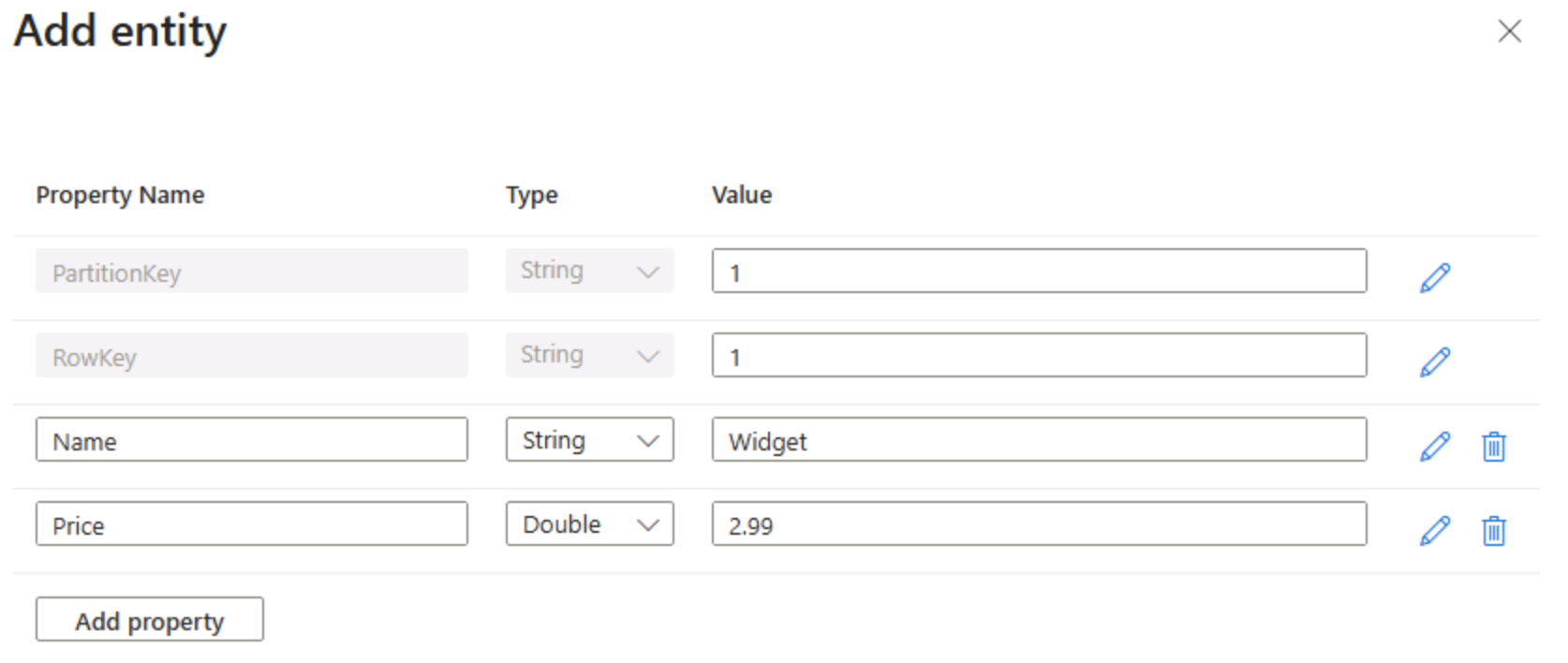
-
Нажмите кнопку Вставить, чтобы вставить строку для новой сущности в таблицу.
-
В обозревателе хранилища убедитесь, что строка была добавлена в таблицу Products и что был создан столбец timestamp для указания времени последнего изменения строки.
-
Добавьте еще одну сущность в таблицу Products со следующими свойствами:
Имя свойства Тип значение PartitionKey Строка 1 RowKey Строка 2 Имя. Строка Kniknak Цена, Двойной 1,99 Выведено из использования Логический true Совет. Добавление второй сущности с разными ключами и дополнительным логическим свойством демонстрирует гибкость записи схемы — новые атрибуты не требуют миграции.
-
После вставки новой сущности убедитесь, что в таблице показана строка, содержащая неподдерживаемый продукт.
Вы вручную указали данные в таблице с помощью интерфейса браузера хранилища. В реальной ситуации разработчики приложений могут использовать API службы хранилища таблиц Azure для создания приложений, считывающих и записывающих значения в таблицы, что делает его экономичным и масштабируемым решением для хранилища NoSQL.
Совет. Если вы закончили изучение служба хранилища Azure, вы можете удалить группу ресурсов, созданную в этом упражнении. Удаление группы ресурсов является самым быстрым способом, чтобы избежать текущих расходов, удалив каждый ресурс, созданный в одном действии.