Explorar a análise de dados no Azure com o Azure Synapse Analytics
Neste exercício, você vai provisionar um workspace do Azure Synapse Analytics em sua assinatura do Azure e usá-lo para ingerir e consultar dados.
Este laboratório levará aproximadamente 30 minutos para ser concluído.
Antes de começar
É necessário ter uma assinatura do Azure com acesso de nível administrativo.
Provisionar um workspace do Azure Synapse Analytics
Para usar o Azure Synapse Analytics, você precisa provisionar um recurso de workspace do Azure Synapse Analytics em sua assinatura do Azure.
-
Abra o portal do Azure em https://portal.azure.com e entre usando as credenciais associadas a sua assinatura do Azure.
Dica: verifique se você está trabalhando no diretório que contém a sua assinatura (indicado no canto superior direito embaixo da sua ID de usuário). Caso contrário, selecione o ícone de usuário e o troque o diretório.
- Na portal do Azure, na Página Inicial, use o ícone + Criar um recurso para criar um recurso.
- Pesquise por
Azure Synapse Analyticse crie um recurso do Azure Synapse Analytics com as seguintes configurações:- Assinatura: sua assinatura do Azure
- Grupo de recursos: Criar um grupo de recursos com um nome apropriado, como “synapse-rg”
- Grupo de recursos gerenciado: Insira um nome apropriado, por exemplo, “synapse-managed-rg”.
- Nome do workspace: *insira um nome de workspace exclusivo, por exemplo, “synapse-ws-
"* . - Região: selecione uma das seguintes regiões:
- Leste da Austrália
- Centro dos EUA
- Leste dos EUA 2
- Norte da Europa
- Centro-Sul dos Estados Unidos
- Sudeste da Ásia
- Sul do Reino Unido
- Europa Ocidental
- Oeste dos EUA
- WestUS 2
- Selecione o Data Lake Storage Gen 2: Da assinatura
- Nome da conta: *Crie conta com um nome exclusivo, por exemplo, “datalake
"*. - Nome do sistema de arquivos: *Crie um sistema de arquivos com um nome exclusivo, por exemplo “fs
"*.
- Nome da conta: *Crie conta com um nome exclusivo, por exemplo, “datalake
Observação: um workspace do Synapse Analytics requer dois grupos de recursos na assinatura do Azure: um para recursos criados explicitamente e outro para recursos gerenciados que são usados pelo serviço. Ele também requer uma conta de armazenamento de Data Lake para armazenar dados, scripts e outros artefatos.
- Assinatura: sua assinatura do Azure
- Depois de inserir esses detalhes, selecione Revisar + criar e selecione Criar para criar o workspace.
- Aguarde a criação do workspace, isso levará cerca de cinco minutos.
- Quando a implantação for concluída, vá para o grupo de recursos que foi criado e observe que ele contém o workspace do Synapse Analytics e uma conta de armazenamento Data Lake.
- Selecione o seu workspace do Synapse e a página de Visão Geral dele, no cartão do Open Synapse Studio, selecione Abrir para abrir o Synapse Studio em uma nova guia do navegador. O Synapse Studio é uma interface baseada na Web que pode ser usada para trabalhar com o seu workspace do Synapse Analytics.
-
No lado esquerdo do Synapse Studio, use o ícone ›› para expandir o menu, isso revela as diferentes páginas no Synapse Studio que você usará para gerenciar recursos e executar tarefas de análise de dados, como mostrado aqui:
Ingestão de dados
Uma das principais tarefas que você pode executar com o Azure Synapse Analytics é definir pipelines que transferem (e, se necessário, transformam) dados de uma ampla gama de fontes no seu workspace para análise.
- No Synapse Studio, na Página Inicial, selecione Ingerir para abrir a ferramenta Copiar Dados.
- Na ferramenta Copiar Dados, na etapa Propriedades, verifique se Tarefa de cópia interna e Executar agora estão selecionados e clique em Avançar >.
- Na etapa de Origem, na subetapa de Conjunto de dados, selecione as seguintes configurações:
- Tipo de fonte: Todas
- Conexão: crie uma conexão e, no painel Nova conexão exibido, na guia Protocolo genérico, selecione HTTP. Então crie uma conexão com um arquivo de dados usando as seguintes configurações:
- Nome:
AdventureWorks Products - Descrição:
Product list via HTTP - Conectar por meio de runtime de integração: AutoResolveIntegrationRuntime
- URL Base:
https://raw.githubusercontent.com/MicrosoftLearning/DP-900T00A-Azure-Data-Fundamentals/master/Azure-Synapse/products.csv - Validação de Certificado do Servidor: Habilitar
- Tipo de autenticação: Anônimo
- Nome:
- Depois de criar a conexão, na subetapa de Origem/Conjunto de Dados, verifique se as seguintes configurações estão selecionadas e selecione Avançar >:
- URL Relativa: Deixar em branco
- Método de solicitação: GET
- Cabeçalhos adicionais: Deixar em branco
- Cópia binária: Desmarcada
- Tempo limite de solicitação: Deixar em branco
- Máximo de conexões simultâneas: Deixar em branco
- Na etapa Origem, na subetapa Configuração, selecione Visualizar dados para ver uma prévia dos dados do produto que seu pipeline ingerirá e, em seguida, feche a prévia.
- Depois de visualizar os dados, na etapa de Origem/Configuração, verifique se as seguintes configurações estão selecionadas e selecione Avançar >:
- Formato de arquivo: DelimitedText
- Delimitador de colunas: Vírgula (,)
- Delimitador de linha: Alimentação de linha (\n)
- Primeira linha como cabeçalho: Selecionada
- Tipo de compactação: Nenhum
- Na etapa Destino, na subetapa Conjunto de dados, selecione as seguintes configurações:
- Tipo de destino: Azure Data Lake Storage Gen 2
- Conexão: selecione a conexão existente com o data lake store (gerado para você no momento da criação do workspace).
- Depois de selecionar a conexão, na etapa Destino/conjunto de dados, verifique se as seguintes configurações estão selecionadas e, em seguida, clique em Avançar > :
- Caminho da pasta: Navegue para a pasta do seu sistema de arquivos
- Nome do arquivo: products.csv
- Comportamento da cópia: Nenhum
- Máximo de conexões simultâneas: Deixar em branco
- Tamanho do bloco (MB): Deixar em branco
- Na etapa Destino, na subetapa Configuração, verifique se as propriedades a seguir estão selecionadas. Em seguida, selecione Avançar >:
- Formato de arquivo: DelimitedText
- Delimitador de colunas: Vírgula (,)
- Delimitador de linha: Alimentação de linha (\n)
- Adicionar cabeçalho ao arquivo: Selecionado
- Tipo de compactação: Nenhum
- Máximo de linhas por arquivo: Deixar em branco
- Prefixo do nome do arquivo: Deixar em branco
- Na etapa Configurações, insira estas configurações e clique em Avançar >:
- Nome da tarefa: Copiar produtos
- Descrição da tarefa Copiar dados dos produtos
- Tolerância a falhas: Deixar em branco
- Habilitar registro em log: Desmarcado
- Habilitar processo de preparo: Desmarcado
- Na etapa Revisar e concluir, na subetapa Revisar, leia o resumo e clique em Avançar >.
- Na subetapa Implantação, aguarde a implantação do pipeline e clique em Concluir.
- No Synapse Studio, selecione a página Monitorar e, na guia Execuções de pipeline, aguarde até que o pipeline Copiar produtos seja concluído com um status de Sucesso (é possível usar o botão ↻ Atualizar na página Execuções de pipeline para atualizar o status).
-
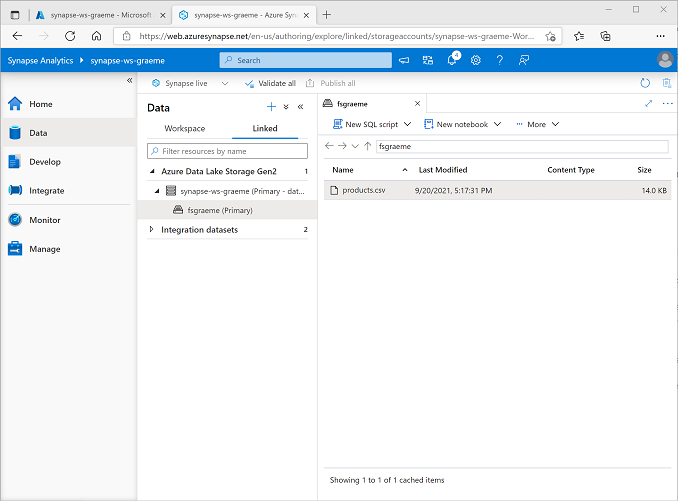
Na página Dados, selecione a guia Vinculado e expanda a hierarquia do Azure Data Lake Storage Gen 2 até ver o armazenamento de arquivos do workspace do Synapse. Em seguida, selecione o armazenamento de arquivos para verificar se um arquivo chamado products.csv foi copiado para esse local, como mostrado aqui:
Usar um pool de SQL para analisar os dados
Agora que você já ingeriu alguns dados no seu workspace, use o Synapse Analytics para consultá-los e analisá-los. Uma das maneiras mais comuns de consultar dados é usar o SQL e, no Synapse Analytics, você pode usar um pool de SQL para executar o código de SQL.
- No Synapse Studio, clique com o botão direito do mouse no arquivo products.csv no armazenamento de arquivos do seu workspace do Synapse, aponte para Novo script de SQL e escolha Selecionar as 100 linhas superiores.
-
No painel Script SQL 1 que será aberto, revise o código de SQL que foi gerado, que deve ser semelhante a este:
-- This is auto-generated code SELECT TOP 100 * FROM OPENROWSET( BULK 'https://datalakexx.dfs.core.windows.net/fsxx/products.csv', FORMAT = 'CSV', PARSER_VERSION='2.0' ) AS [result]Esse código abre um conjunto de linhas do arquivo de texto que você importou e recupera as primeiras 100 linhas de dados.
- Na lista Conectar-se a, verifique se Interno está selecionado — isso representa o Pool de SQL interno que foi criado com o seu workspace.
-
Na barra de ferramentas, use o botão ▷ Executar para executar o código SQL e examine os resultados, que devem ser semelhantes a este:
C1 c2 c3 c4 ProductID ProductName Categoria ListPrice 771 Mountain-100 Silver, 38 Mountain Bikes 3399.9900 772 Mountain-100 Silver, 42 Mountain Bikes 3399.9900 … … … … -
Observe que os resultados consistem em quatro colunas chamadas C1, C2, C3 e C4; e que a primeira linha nos resultados contém os nomes dos campos de dados. Para corrigir esse problema, adicione um parâmetro HEADER_ROW = TRUE à função OPENROWSET conforme mostrado aqui (substituindo datalakexx e fsxx pelos nomes da sua conta de armazenamento do data lake e do sistema de arquivos) e execute novamente a consulta:
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://datalakexx.dfs.core.windows.net/fsxx/products.csv', FORMAT = 'CSV', PARSER_VERSION='2.0', HEADER_ROW = TRUE ) AS [result]Agora, os resultados terão a seguinte aparência:
ProductID ProductName Categoria ListPrice 771 Mountain-100 Silver, 38 Mountain Bikes 3399.9900 772 Mountain-100 Silver, 42 Mountain Bikes 3399.9900 … … … … -
Modifique a consulta da seguinte maneira (substituindo datalakexx e fsxx pelos nomes da conta de armazenamento do data lake e do sistema de arquivos):
SELECT Category, COUNT(*) AS ProductCount FROM OPENROWSET( BULK 'https://datalakexx.dfs.core.windows.net/fsxx/products.csv', FORMAT = 'CSV', PARSER_VERSION='2.0', HEADER_ROW = TRUE ) AS [result] GROUP BY Category; -
Execute a consulta modificada, que retornará um conjunto de resultados contendo o número de produtos em cada categoria, desta forma:
Categoria ProductCount Bib Shorts 3 Porta-bicicletas 1 … … -
No painel Propriedades do Script SQL 1, altere o Nome para
Count Products by Category. Em seguida, na barra de ferramentas, selecione Publicar para salvar o script. -
Feche o painel do script Contar Produtos por Categoria.
-
No Synapse Studio, selecione a página Desenvolver e observe que seu script SQL Contar Produtos por Categoria publicado foi salvo nela.
-
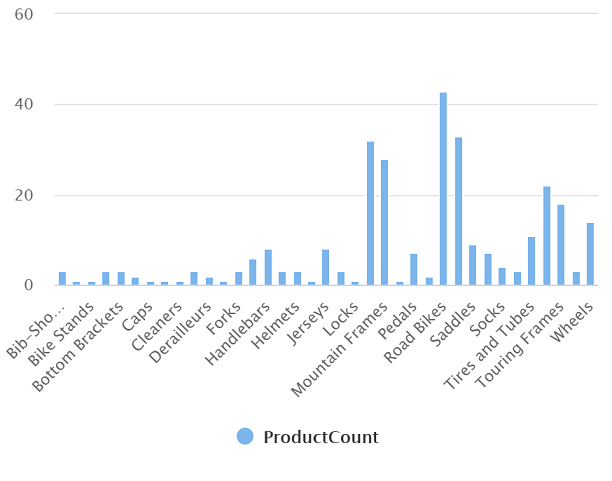
Selecione o script SQL Contar Produtos por Categoria para abri-lo novamente. Em seguida, verifique se o script está conectado ao pool de SQL Interno e execute-o para recuperar as contagens de produtos.
- No painel de Resultados, selecione o modo de exibição de Gráfico e selecione as seguintes configurações para o gráfico:
- Tipo de gráfico: Coluna
- Coluna de categoria: Categoria
- Colunas de legenda (série): ProductCount
- Posição da legenda: Inferior central
- Rótulo de legenda (série): Deixar em branco
- Valor mínimo da legenda (série): Deixar em branco
- Máximo da legenda (série): Deixar em branco
- Rótulo da categoria: Deixar em branco
O gráfico resultante deve ser semelhante a este:
Usar um pool do Spark para analisar os dados
Embora a linguagem SQL seja comum para a consulta de conjuntos de dados estruturados, muitos analistas de data consideram linguagens como Python úteis para explorar e preparar dados para análise. No Azure Synapse Analytics, você pode executar o código Python (e outros) em um pool do Spark; que usa um mecanismo de processamento de dados distribuído com base em Apache Spark.
- No Synapse Studio, selecione a página Gerenciar.
- Selecione a guia pools do Apache Spark e use o ícone + Novo para criar um pool do Spark com as seguintes configurações:
- Nome do pool do Apache Spark: spark
- Família do tamanho do nó: Otimizado para memória
- Tamanho do nó: Pequeno (4 vCores / 32 GB)
- Dimensionamento automático: Habilitado
- Número de nós 3—-3
- Revise e crie o pool do Spark e aguarde até que ele seja implantado (o que pode levar alguns minutos).
- Quando o pool do Spark tiver sido implantado, no Synapse Studio, na página de Dados, navegue até o sistema de arquivos do seu workspace do Synapse. Em seguida, clique com o botão direito do mouse em products.csv, aponte para Novo notebook e selecione Carregar no DataFrame.
- No painel Notebook 1 que será exibido, na lista Anexar a, selecione o pool do Spark spark como criado anteriormente e verifique se a Linguagem está configurada como PySpark (Python).
-
Examine o código na primeira (e única) célula no notebook, que terá esta aparência:
%%pyspark df = spark.read.load('abfss://fsxx@datalakexx.dfs.core.windows.net/products.csv', format='csv' ## If header exists uncomment line below ##, header=True ) display(df.limit(10)) -
Selecione ▷ Executar à esquerda da célula de código para executá-la e aguarde os resultados. Da primeira vez que você executar uma célula em um notebook, o pool do Spark será iniciado. Portanto, qualquer resultado poderá levar cerca de um minuto para ser retornado.
Observação: se ocorrer um erro porque o kernel do Python ainda não está disponível, execute a célula novamente.
-
Eventualmente, os resultados deverão aparecer abaixo da célula e ser semelhantes a este:
c0 c1 c2 c3 ProductID ProductName Categoria ListPrice 771 Mountain-100 Silver, 38 Mountain Bikes 3399.9900 772 Mountain-100 Silver, 42 Mountain Bikes 3399.9900 … … … … -
Descompacte a linha header=True (porque o arquivo products.csv tem os títulos de coluna na primeira linha), para que seu código tenha esta aparência:
%%pyspark df = spark.read.load('abfss://fsxx@datalakexx.dfs.core.windows.net/products.csv', format='csv' ## If header exists uncomment line below , header=True ) display(df.limit(10)) -
Execute novamente a célula e verifique se o resultado terá esta aparência:
ProductID ProductName Categoria ListPrice 771 Mountain-100 Silver, 38 Mountain Bikes 3399.9900 772 Mountain-100 Silver, 42 Mountain Bikes 3399.9900 … … … … Observe que executar a célula novamente leva menos tempo, porque o pool do Spark já foi iniciado.
- Nos resultados, use o ícone + Código para adicionar uma nova célula de código ao notebook.
-
Na nova célula de código vazia, adicione o seguinte código:
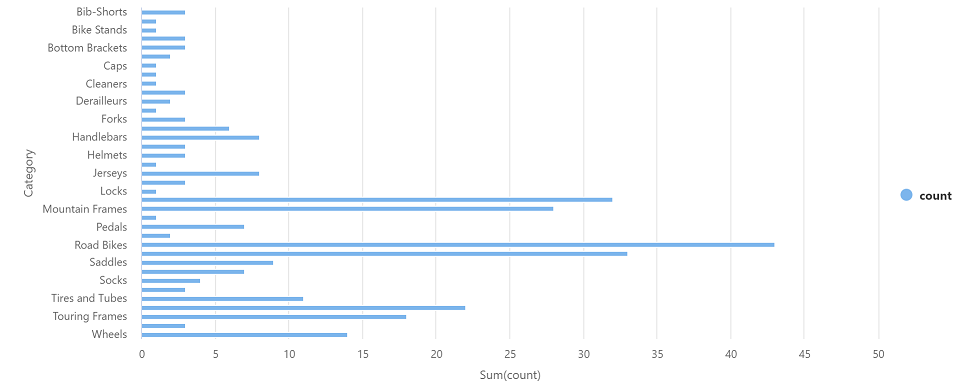
df_counts = df.groupBy(df.Category).count() display(df_counts) -
Selecione ▷ Executar à esquerda para executar a nova célula de código e revisar os resultados, que devem ser semelhantes ao seguinte:
Categoria count Fones de ouvido 3 Wheels 14 … … -
Na saída dos resultados da célula, selecione o modo de exibição de Gráfico. O gráfico resultante deve ser semelhante a este:
- Feche o painel Notebook 1 e descarte as alterações.
Excluir recursos do Azure
Se você terminou de explorar Azure Synapse Analytics, exclua os recursos que criou para evitar custos desnecessários do Azure.
- Feche a guia do navegador do Synapse Studio e retorne ao portal do Azure.
- No portal do Azure, na Página Inicial, selecione Grupos de recursos.
- Selecione o grupo de recursos para o workspace do Synapse Analytics (não o grupo de recursos gerenciado) e verifique se ele contém o workspace do Synapse, a conta de armazenamento e o pool do Spark para seu workspace.
- Na parte superior da página de Visão Geral do grupo de recursos, selecione Excluir o grupo de recursos.
-
Digite o nome do grupo de recursos para confirmar que deseja excluí-lo e selecione Excluir.
Após alguns minutos, seu workspace do Azure Synapse e o workspace gerenciado associado a ele serão excluídos.