Explorer l’analytique de données dans Microsoft Fabric
Dans cet exercice, vous allez explorer l’ingestion et l’analytique de données dans un Lakehouse Microsoft Fabric.
En suivant ce labo, vous allez :
- Comprendre les concepts de Microsoft Fabric Lakehouse : Découvrez comment créer des espaces de travail et des lakehouses, qui sont essentiels pour organiser et gérer vos ressources de données dans Fabric.
- Ingérer les données à l’aide de pipelines : Utilisez un pipeline guidé pour importer des données externes dans le lakehouse, ce qui le rend prêt pour les requêtes sans codage manuel.
- Explorez et interrogez des données avec SQL : Analysez les données ingérées à l’aide de requêtes SQL bien connues, en obtenant des informations directement dans Fabric.
- Gérer les ressources : Découvrez les meilleures pratiques pour nettoyer les ressources afin d’éviter des frais inutiles.
Arrière-plan sur le jeu de données NYC Taxi :
Le jeu de données « NYC Taxi – Green » contient des enregistrements détaillés des trajets en taxi à New York, notamment les heures de ramassage et de dépose, les emplacements, les distances parcourues, les tarifs et le nombre de passagers. Il est largement utilisé dans l’analytique des données et l’apprentissage automatique pour explorer la mobilité urbaine, faire de la prévision de la demande et la détection d’anomalie. Dans cette activité, vous allez utiliser ce jeu de données réel pour pratiquer l’ingestion et l’analyse des données dans Microsoft Fabric.
Ce labo prend environ 25 minutes.
Remarque : Vous aurez besoin d’une licence Microsoft Fabric pour effectuer cet exercice. Pour plus d’informations sur l’activation d’une licence d’essai Fabric gratuite, consultez Bien démarrer avec Fabric. Vous aurez besoin pour cela d’un compte scolaire ou professionnel Microsoft. Si vous n’en avez pas, vous pouvez vous inscrire à un essai de Microsoft Office 365 E3 ou supérieur.
La première fois que vous utilisez une fonctionnalité de Microsoft Fabric, des invites avec des conseils peuvent apparaître. Ignorez-les.
Créer un espace de travail
Avant d’utiliser des données dans Fabric, créez un espace de travail avec l’essai gratuit de Fabric activé.
Conseil : un espace de travail est votre conteneur pour toutes les ressources (lakehouses, pipelines, bloc-notes, rapports). L’activation de la capacité Fabric permet à ces éléments de s’exécuter.
-
Accédez à la page d’accueil de Microsoft Fabric sur
https://app.fabric.microsoft.com/home?experience=fabricdans un navigateur et connectez-vous avec vos informations d’identification Fabric. -
Dans la barre de menus à gauche, sélectionnez Espaces de travail (l’icône ressemble à 🗇).

-
Créez un nouvel espace de travail avec le nom de votre choix et sélectionnez un mode de licence dans la section Avancé qui comprend la capacité Fabric (Essai, Premium ou Fabric).
Conseil : la sélection d’une capacité incluant Fabric fournit à l’espace de travail les moteurs nécessaires aux tâches d’ingénierie des données. L’utilisation d’un espace de travail dédié permet d’isoler les ressources de votre activité et de faciliter leur nettoyage.
-
Lorsque votre nouvel espace de travail s’ouvre, il doit être vide.
Créer un lakehouse
Maintenant que vous disposez d’un espace de travail, il est temps de créer un lakehouse pour vos fichiers de données.
Conseil : Un lakehouse rassemble des fichiers et des tables sur OneLake. Vous pouvez stocker des fichiers bruts et créer aussi des tables Delta managées que vous pouvez interroger avec SQL.
-
Sélectionnez Créer dans la barre de menus de gauche. Dans la page Nouveau, sous la section Engineering données, sélectionnez Lakehouse. Donnez-lui un nom unique de votre choix.
Note : si l’option Créer n’est pas épinglée à la barre latérale, vous devez d’abord sélectionner l’option avec des points de suspension (…).

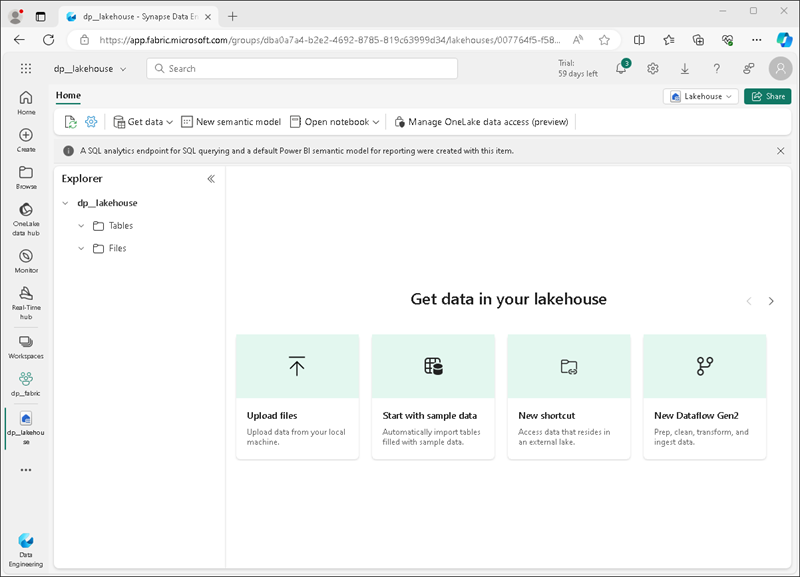
Au bout d’une minute environ, un nouveau lakehouse est créé :
-
Affichez le nouveau lakehouse et notez que le volet Explorateur de lakehouse à gauche vous permet de parcourir les tables et les fichiers présents dans le lakehouse :
- Le dossier Tables contient des tables que vous pouvez interroger à l’aide de la sémantique SQL. Les tables d’un lakehouse Microsoft Fabric sont basées sur le format de fichier Delta Lake open source, qui est couramment utilisé dans Apache Spark.
- Le dossier Fichiers contient des fichiers de données du stockage OneLake pour le lakehouse qui ne sont pas associés à des tables delta managées. Vous pouvez également créer des raccourcis dans ce dossier pour référencer des données qui sont stockées en externe.
Actuellement, il n’y a pas de tables ou de fichiers dans le lakehouse.
Conseil : utilisez les fichiers pour les données brutes ou provisoires, et les tables pour les jeux de données organisés et prêts pour les requêtes. Les tables sont prises en charge par Delta Lake, ce qui leur permet de prendre en charge des mises à jour fiables et des requêtes efficaces.
Ingérer des données
Un moyen simple d’ingérer des données consiste à utiliser une activité Copier des données dans un pipeline afin d’extraire les données d’une source et de les copier dans un fichier dans le lakehouse.
Conseil : les pipelines offrent un moyen guidé et reproductible d’importer des données dans le lakehouse. Ils sont plus faciles à utiliser que le codage à partir de zéro et peuvent être programmés ultérieurement si nécessaire.
-
Dans la page Accueil de votre lakehouse, dans le menu Obtenir des données, sélectionnez Nouveau pipeline de données, puis créez un pipeline de données nommé Ingérer des données.

-
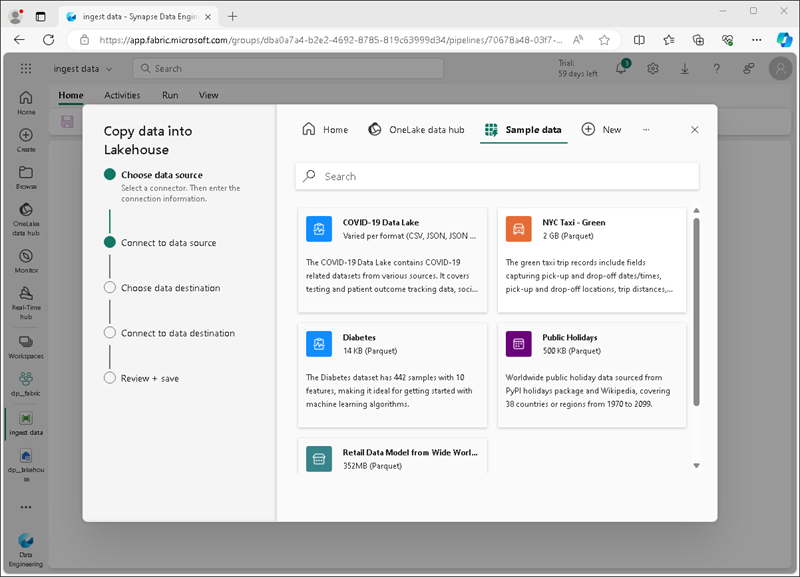
Dans l’Assistant Copier des données, dans la page Choisir une source de données, sélectionnez Exemples de données, puis sélectionnez l’exemple de jeu de donnés NYC Taxi - Green.

-
Sur la page Se connecter à la source de données, affichez les tables de la source de données. Vous devriez voir une table contient des informations sur les trajets en taxi à New York. Sélectionnez ensuite Suivant pour accéder à la page Se connecter à la destination des données.
- Dans la page Se connecter à la destination des données, définissez les options de destination de données suivantes, puis sélectionnez Suivant :
- Dossier racine : Tables
- Paramètres de chargement : Charger dans la nouvelle table
- Nom de la table de destination : taxi_rides (vous devrez peut-être attendre que l’aperçu des mappages de colonnes s’affiche pour pouvoir le modifier)
- Mappages de colonnes : Laisser les mappages par défaut tels qu’ils sont
- Activer la partition : Non sélectionné

Pourquoi ces choix ?
Nous commençons par Tables en tant que racine afin que les données soient directement intégrées dans une table Delta gérée, que vous pouvez interroger immédiatement. Nous le chargeons dans une nouvelle table afin que cette activité reste autonome et que rien de ce qui existe ne soit remplacé. Nous conserverons les mappages de colonnes par défaut, car les données d’exemple correspondent déjà à la structure attendue. Aucun mappage personnalisé n’est nécessaire. Le partitionnement est désactivée afin de simplifier les choses pour ce petit jeu de données. Bien que le partitionnement soit utile pour les données à grande échelle, il n’est pas nécessaire ici.
-
Dans la page Vérifier + enregistrer, vérifiez que l’option Démarrer immédiatement le transfert de données est sélectionnée, puis sélectionnez Enregistrer + exécuter.
Conseil : Le démarrage immédiat vous permet de voir le pipeline en action et de confirmer que les données arrivent sans étapes supplémentaires.
Un nouveau pipeline contenant une activité Copier des données est créé, comme illustré ici :
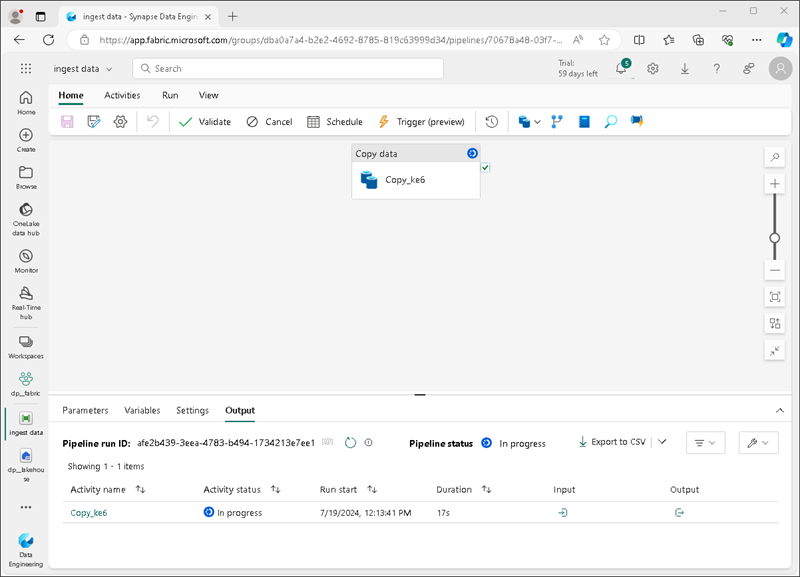
Lorsque le pipeline commence à s’exécuter, vous pouvez superviser son statut dans le volet Sortie sous le concepteur de pipeline. Cliquez sur l’icône ↻ (Actualiser) pour actualiser le statut et patientez jusqu’à ce que l’actualisation aboutisse (ce qui peut prendre 10 minutes ou plus). Ce jeu de données particulier contient plus de 75 millions de lignes, stockant environ 2,5 Go de données.
-
Dans la barre de menus du hub à gauche, sélectionnez votre lakehouse.

-
Sur la page Accueil, dans le volet Explorateur Lakehouse, dans le menu … du nœud Tables, sélectionnez Actualiser, puis développez Tables pour vérifier que la table taxi_rides a été créée.

Remarque : si la nouvelle table est répertoriée comme non identifiée, utilisez l’option de menu Actualiser associée pour actualiser la vue.
Conseil : la vue Explorateur est mise en cache. L’actualisation force le système à récupérer les dernières métadonnées de la table afin que votre nouvelle table s’affiche correctement.
-
Sélectionnez la table taxi_rides pour afficher son contenu.

Interroger des données dans un lakehouse
Maintenant que vous avez ingéré des données dans une table dans le lakehouse, vous pouvez utiliser SQL pour les interroger.
Conseil : les tables lakehouse sont conviviales pour SQL. Vous pouvez analyser les données immédiatement sans les transférer vers un autre système.
-
En haut à droite de la page Lakehouse, basculez de la vue Lakehouse vers le point de terminaison d’analytique SQL de votre lakehouse.

Conseil : le point de terminaison d’analytique SQL est optimisé pour exécuter des requêtes SQL sur vos tables lakehouse et s’intègre aux outils de requête bien connus.
-
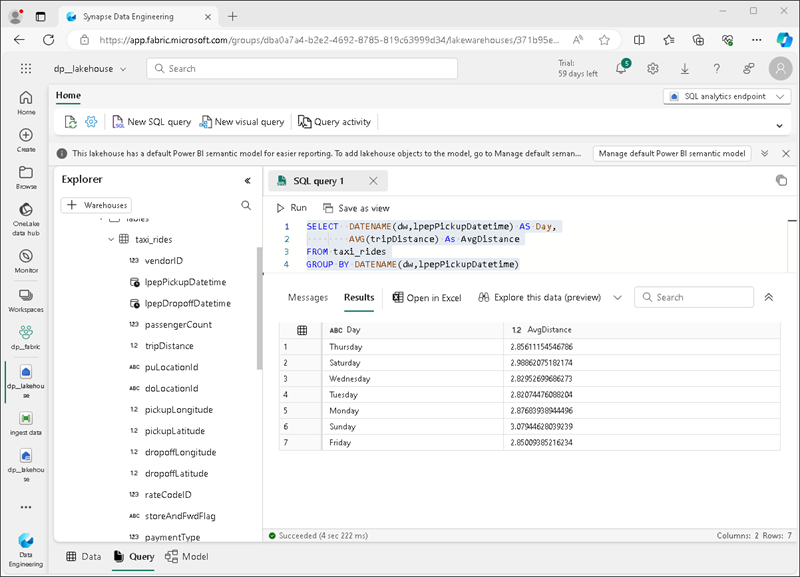
Dans la barre d’outils, sélectionnez Nouvelle requête SQL. Entrez ensuite le code SQL suivant dans l’éditeur de requête :
SELECT DATENAME(dw,lpepPickupDatetime) AS Day, AVG(tripDistance) As AvgDistance FROM taxi_rides GROUP BY DATENAME(dw,lpepPickupDatetime) -
Sélectionnez le bouton ▷ Exécuter pour exécuter la requête et passer en revue les résultats, qui doivent inclure la distance moyenne de trajet pour chaque jour de la semaine.
Conseil : cette requête regroupe les trajets par nom de jour et calcule la distance moyenne, illustrant ainsi un exemple simple d’agrégation sur lequel vous pouvez vous appuyer.
Nettoyer les ressources
Si vous avez terminé d’explorer Microsoft Fabric, vous pouvez supprimer l’espace de travail que vous avez créé pour cet exercice.
Conseil : en supprimant l’espace de travail, vous effacez tous les éléments créés dans l’activité et évitez ainsi des frais permanents.
-
Dans la barre de gauche, sélectionnez l’icône de votre espace de travail pour afficher tous les éléments qu’il contient.
-
Dans la barre d’outils, sélectionnez Paramètres de l’espaces de travail.
-
Dans la section Général, sélectionnez Supprimer cet espace de travail.