Explorer le Stockage Azure
Dans cet exercice, vous allez apprendre à provisionner et configurer un compte de stockage Azure et à explorer ses services principaux : Stockage Blob, Data Lake Storage Gen2, Azure Files et Azure Tables. Vous bénéficiez d’une expérience pratique pour créer des conteneurs, charger des données, activer des espaces de noms hiérarchiques, configurer des partages de fichiers et gérer des entités de table. Ces compétences vous aideront à comprendre comment stocker, organiser et sécuriser des données non relationnelles dans Azure pour différents scénarios d’analytique et d’application.
Ce labo prend environ 15 minutes.
Conseil : Comprendre l’objectif de chaque action vous aide à concevoir ultérieurement des solutions de stockage qui équilibrent les objectifs de coût, de performances, de sécurité et d’analytique. Ces brèves notes Pourquoi attachent chaque étape à une raison réelle.
Avant de commencer
Vous avez besoin d’un abonnement Azure dans lequel vous avez un accès administratif.
Approvisionner un compte de stockage Azure
La première étape de l’utilisation du stockage Azure consiste à approvisionner un compte stockage Azure dans votre abonnement Azure.
Conseil : Un compte de stockage est la limite sécurisée et facturable pour tous les services de stockage Azure (objets blob, fichiers, files d’attente, tables). Les stratégies, la redondance, le chiffrement, la mise en réseau et le contrôle d’accès s’appliquent ici vers le bas.
-
Si ce n’est pas déjà fait, connectez-vous au portail Azure.
-
Dans la page d’accueil du portail Azure, sélectionnez + Créer une ressource en haut à gauche et recherchez
Storage account. Dans la page Compte de stockage qui en résulte, sélectionnez Créer.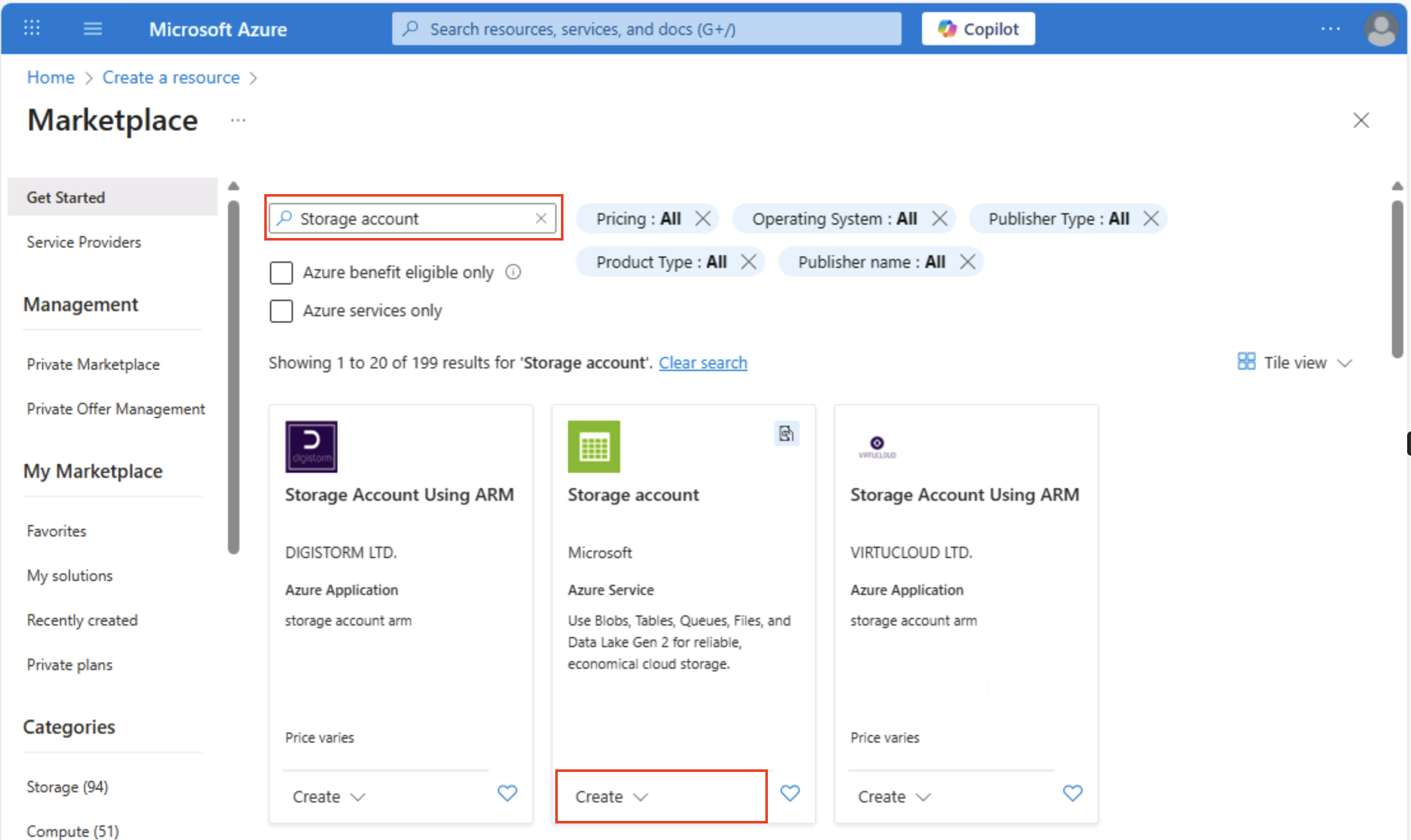
-
Saisissez les valeurs suivantes sur la page Créer un compte de stockage :
- Abonnement: Sélectionnez votre abonnement Azure.
- Groupe de ressources : créez un nouveau groupe de ressources portant le nom de votre choix.
- Nom du compte de stockage : entrez un nom unique pour votre compte de stockage en utilisant des lettres minuscules et des chiffres.
- Région : sélectionnez un emplacement disponible.
- Niveau de performance : Standard
- Redondance : stockage localement redondant (LRS)
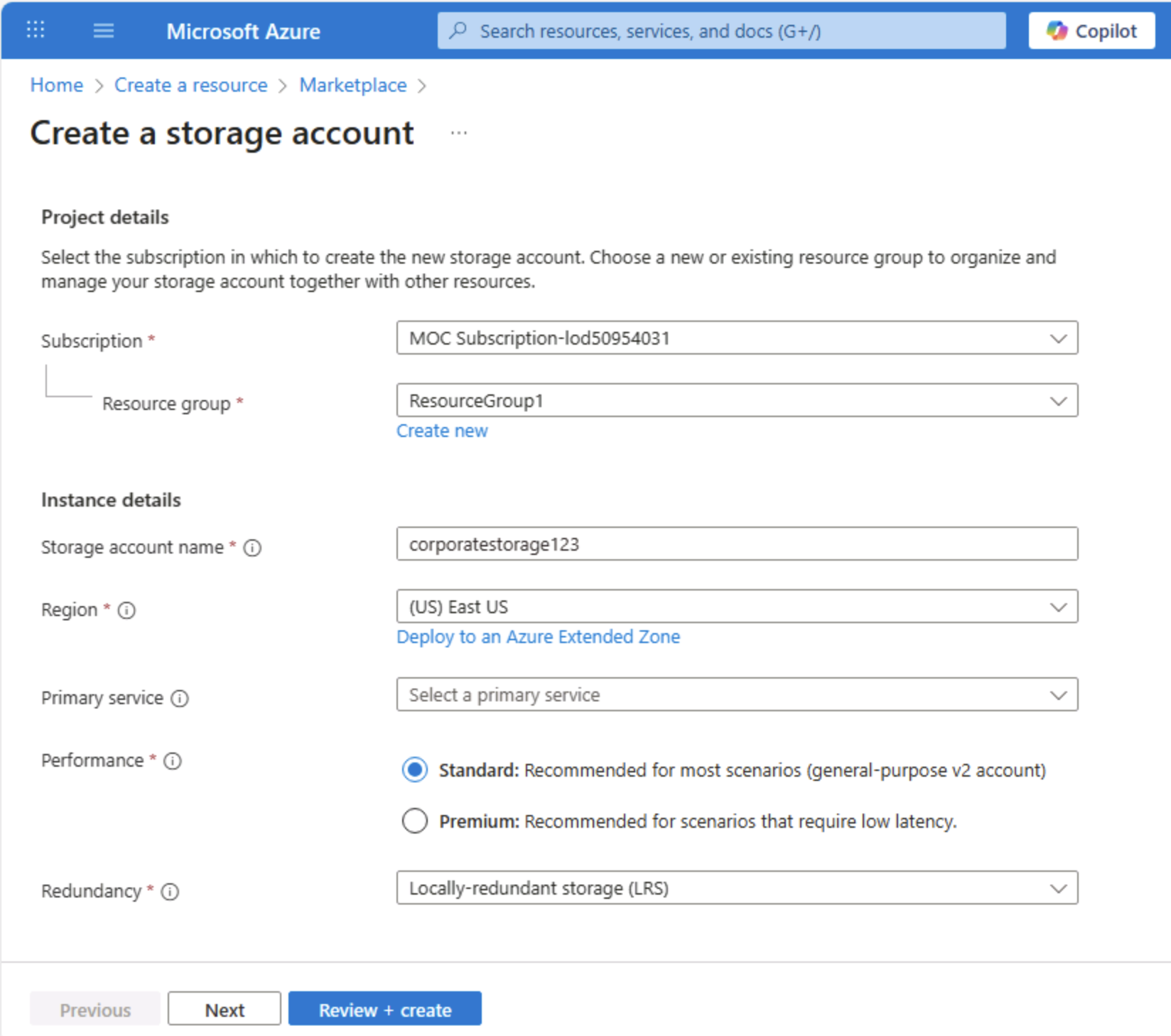
Conseil : Un nouveau groupe de ressources facilite le nettoyage. Standard + LRS est la base de référence la plus faible, adaptée à l’apprentissage. LRS conserve trois copies synchronisées dans une région, ce qui est suffisant pour les données de démonstration non critiques sans avoir à payer pour la réplication géographique.
-
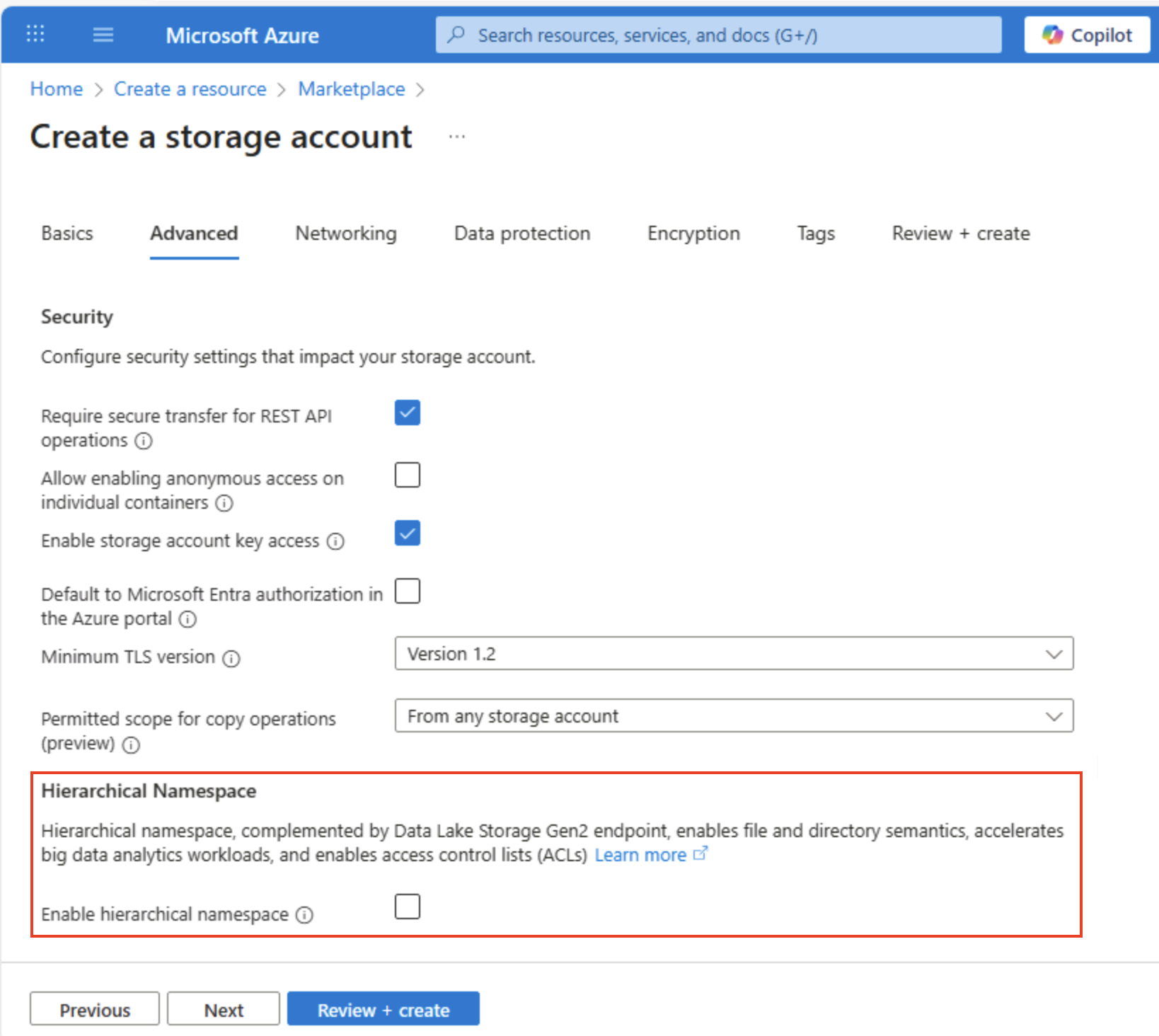
Sélectionnez Suivant : avancé > et examinez les options de configuration avancées. En particulier, notez que vous pouvez ici activer l’espace de noms hiérarchique pour prendre en charge Azure Data Lake Storage Gen2. Laissez cette option désactivée (vous l’activerez plus tard), puis sélectionnez Suivant : Réseau > pour voir les options réseau de votre compte de stockage.
-
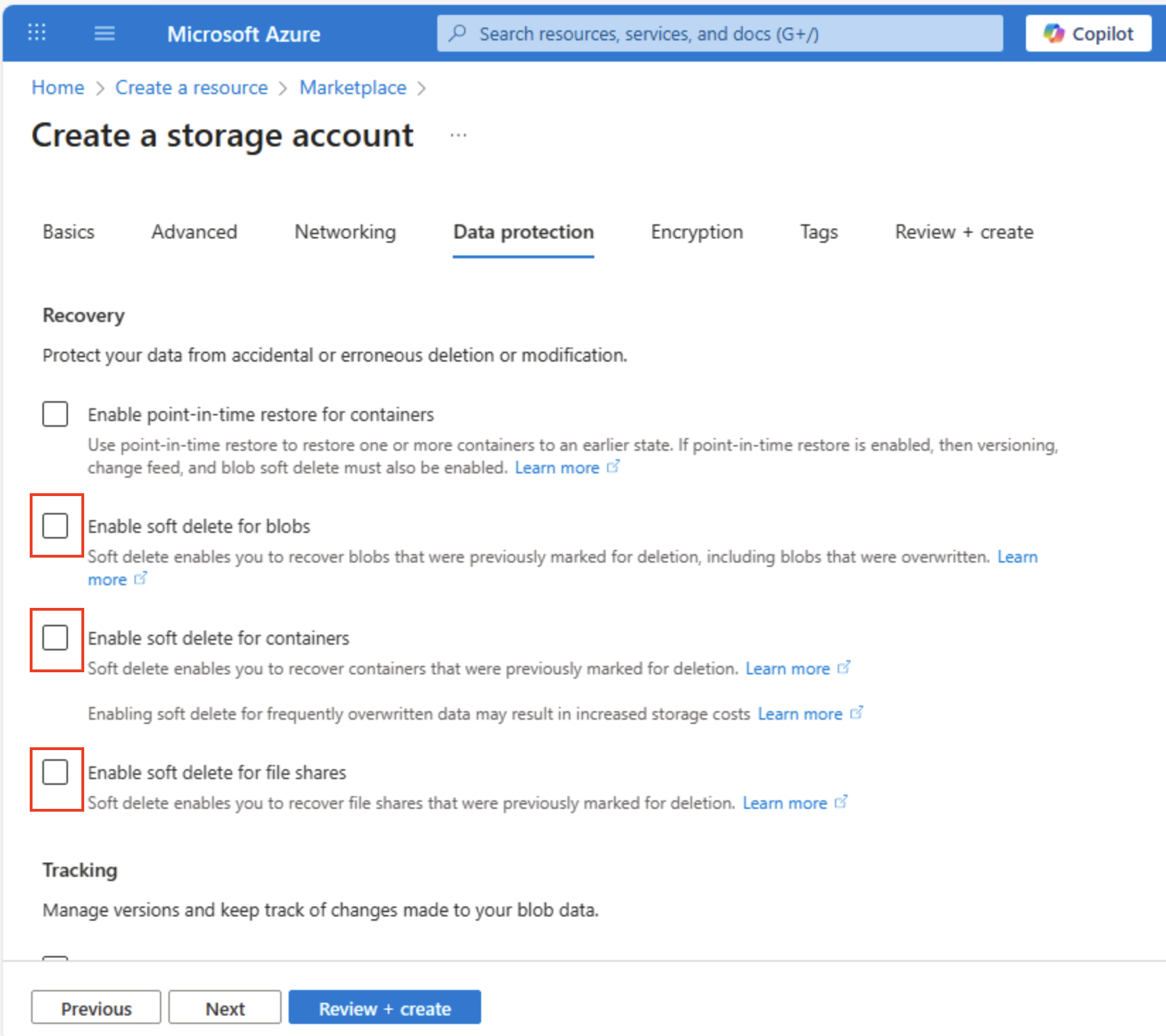
Sélectionnez Suivant : Protection des données > , puis dans la section Récupération, désélectionnez toutes les options Activer la suppression réversible… . Ces options conservent les fichiers supprimés pour la récupération suivante, mais peuvent provoquer des problèmes plus tard lorsque vous activez l’espace de noms hiérarchique.
-
Passez les pages Suivant > restantes sans modifier les paramètres par défaut, puis dans la page Vérifier, attendez que vos sélections soient validées et sélectionnez Créer pour créer votre compte Stockage Azure.
-
Attendez la fin du déploiement. Accédez ensuite à la ressource qui a été déployée.
Explorer le Stockage Blob
Maintenant que vous avez un compte de stockage Azure, vous pouvez créer un conteneur pour les données blob.
Conseil : Un conteneur regroupe des objets blob et est le premier niveau d’étendue pour le contrôle d’accès. En commençant par un stockage blob simple (sans espace de noms hiérarchique), vous découvrirez le comportement des dossiers virtuels que vous comparerez ensuite à Data Lake Gen2.
-
Téléchargez le fichier JSON product1.json à partir de
https://aka.ms/product1.jsonet enregistrez-le sur votre ordinateur (vous pouvez l’enregistrer dans n’importe quel dossier : vous le chargerez dans le Stockage Blob ultérieurement).Si le fichier JSON s’affiche dans votre navigateur, enregistrez la page en tant que product1.json.
-
Dans la page Portail Azure de votre conteneur de stockage, sur le côté gauche, dans la section stockage des données, sélectionnez Conteneurs.
-
Dans la page Conteneurs, sélectionnez + Ajouter un conteneur et ajoutez un nouveau conteneur nommé
dataet ayant un niveau d’accès Privé (aucun accès anonyme).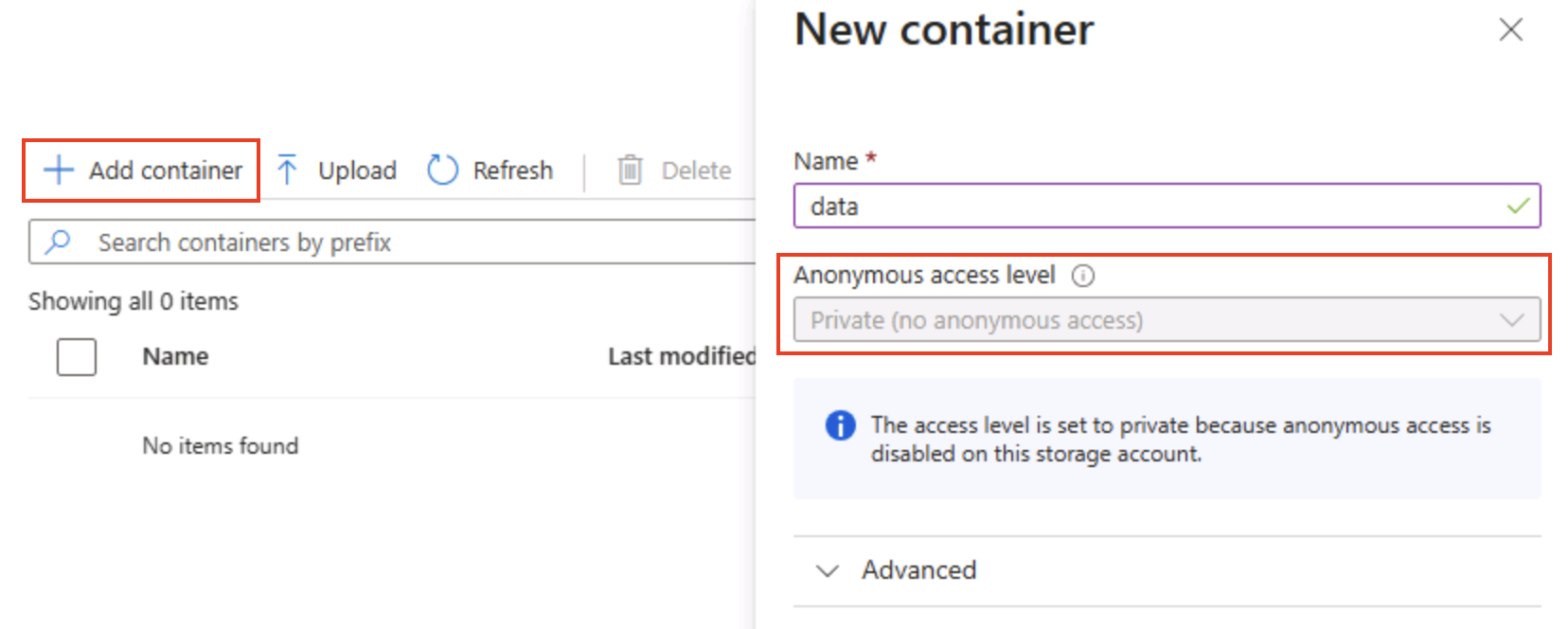
Conseil : Private conserve vos exemples de données sécurisés. L’accès public est rarement nécessaire, à l’exception du site web statique ou des scénarios de données ouverts. Le nommage
dataconserve cet exemple simple et lisible. -
Une fois le conteneur de données créé, vérifiez qu’il est répertorié dans la page Conteneurs.
-
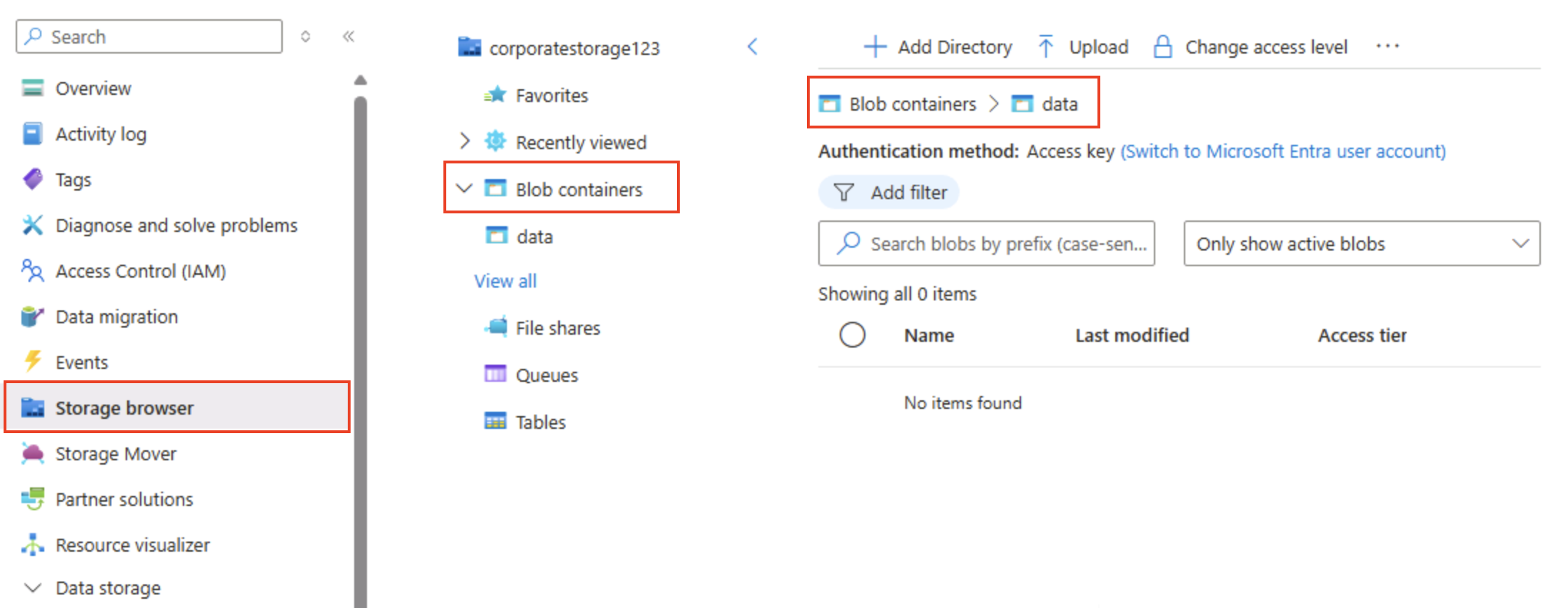
Dans le volet de gauche, dans la section supérieure, sélectionnez Navigateur de stockage. Cette page fournit une interface basée sur un navigateur que vous pouvez utiliser pour travailler avec les données de votre compte de stockage.
-
Dans la page du navigateur de stockage, sélectionnez Conteneurs de blobs et vérifiez que votre conteneur de données est répertorié.
-
Sélectionnez le conteneur de données et notez qu’il est vide.
-
Sélectionnez + Ajouter un répertoire et lisez les informations concernant les dossiers avant de créer un autre répertoire nommé
products. -
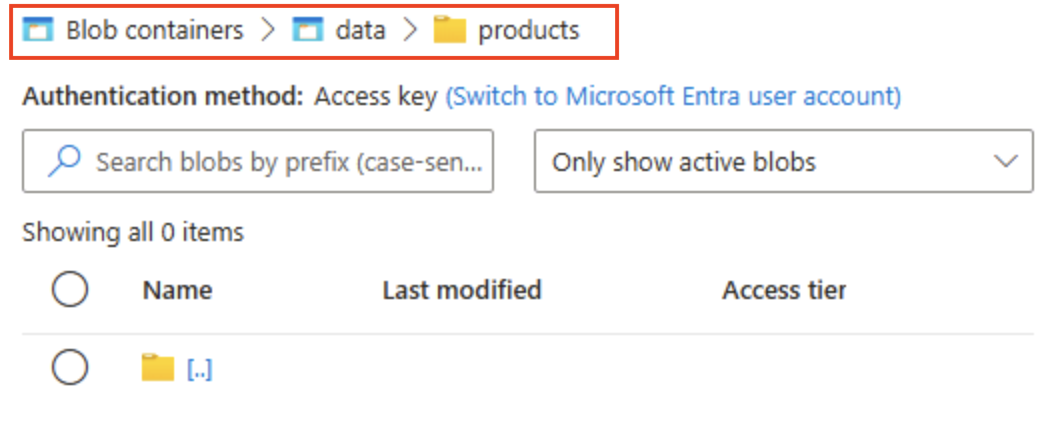
Dans le navigateur de stockage, vérifiez que la vue actuelle affiche le contenu du dossier produits que vous venez de créer. Notez que les barres de navigation en haut de la page indiquent le chemin Conteneurs d’objets blob > données > produits.
-
Dans les barres de navigation, sélectionnez les données à basculer vers le conteneur de données et notez qu’elles ne contiennent pas de dossier nommé produits.
Les dossiers dans le Stockage Blob sont virtuels et existent uniquement dans le cadre du chemin d’accès d’un Blob. Étant donné que le dossier produits ne contenait pas de blob, ce n’est pas vraiment le cas !
Conseil : L’espace de noms plat signifie que les répertoires ne sont que des préfixes de nom (produits/file.json). Cette conception permet une mise à l’échelle massive, car le service indexe les noms d’objets blob au lieu de conserver une véritable structure d’arborescence.
-
Utilisez le bouton ⤒ Charger pour ouvrir le panneau Charger un blob.
-
Dans le panneau Charger un blob, sélectionnez précédemment le fichier product1.json que vous avez enregistré sur votre ordinateur local. Ensuite, dans la section Avancé, dans la zone Charger dans un dossier, entrez
product_dataet sélectionnez le bouton Charger.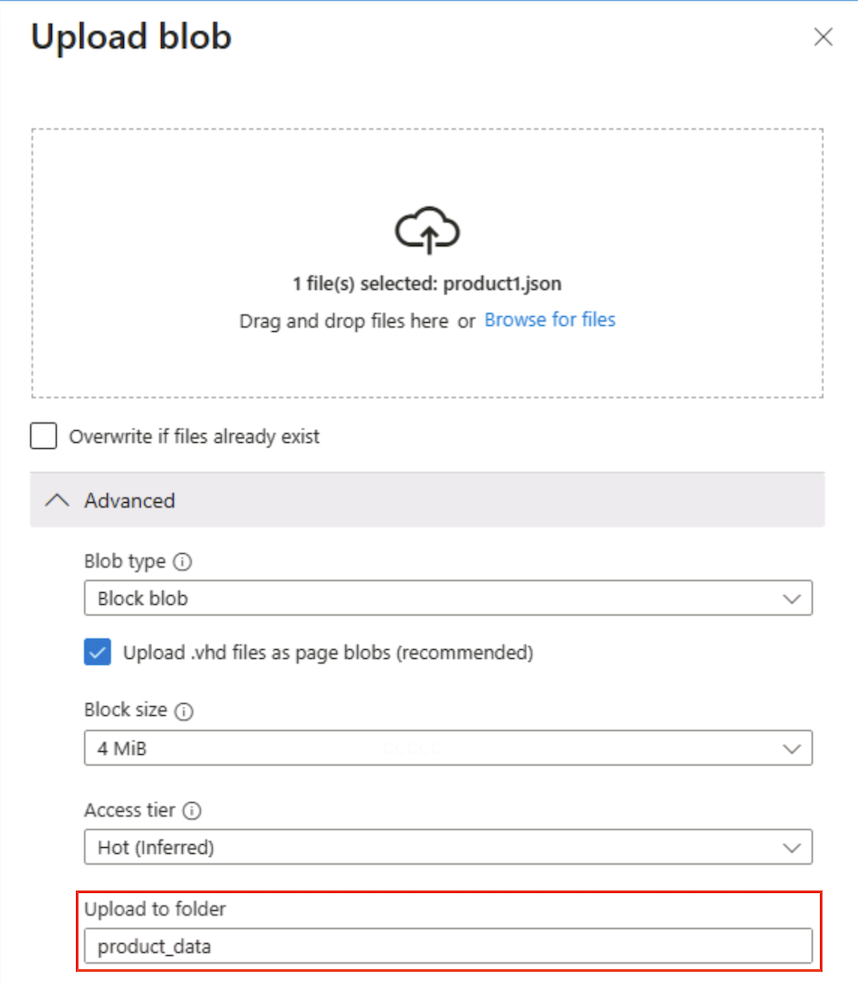
Conseil : La saisie d’un nom de dossier lors du téléchargement crée automatiquement le chemin d’accès virtuel, ce qui montre que la présence d’un blob fait apparaître le « dossier ».
-
Fermez le panneau Charger le blob s’il est toujours ouvert, puis vérifiez qu’un dossier virtuel product_data a été créé dans le conteneur de données.
-
Sélectionnez le dossier product_data et vérifiez qu’il contient le blob product1.json que vous avez chargé.
-
Sur le côté gauche, dans la section Stockage des données, sélectionnez Conteneurs.
-
Ouvrez le conteneur de données et vérifiez que le dossier product_data que vous avez créé est répertorié.
-
Sélectionnez l’icône ‧‧‧ tout à droite du dossier. Vous voyez qu’elle n’affiche aucune option. Les dossiers dans un conteneur d’objets blob d’un espace de noms plat sont virtuels et ne peuvent pas être gérés.
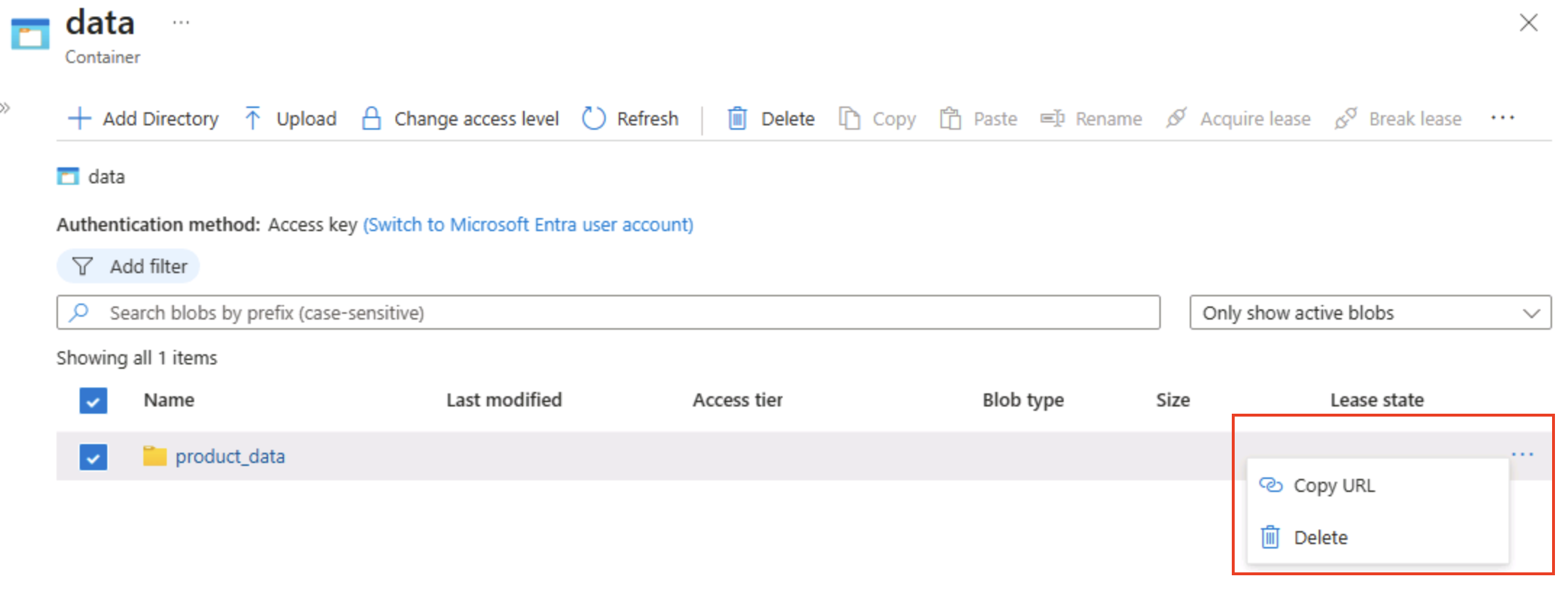
Conseil : Il n’existe aucun objet répertoire réel, il n’y a donc aucune opération de renommage/autorisation — celles-ci nécessitent un espace de noms hiérarchique.
-
Utilisez l’icône X en haut à droite de la page de données pour fermer la page et revenir à la page Conteneurs.
Explorer Azure Data Lake Storage Gen2
Le support Azure Data Lake Store Gen2 vous permet d’utiliser des dossiers hiérarchiques pour organiser et gérer l’accès aux blobs. Il vous permet également d’utiliser le Stockage Blob Azure pour héberger des systèmes de fichiers distribués pour les plateformes d’analytique Big Data courantes.
Conseil : L’activation de l’espace de noms hiérarchique fait que les dossiers se comportent comme des répertoires réels. Il vous permet également d’effectuer des actions de dossier en toute sécurité (toutes en même temps, sans erreurs) et vous donne des contrôles d’autorisation de fichier similaires à ceux dans Linux. Cela est particulièrement utile lors de l’utilisation d’outils Big Data comme Spark ou Hadoop, ou lors de la gestion de lacs de données volumineux et organisés.
-
Téléchargez le fichier JSON product2.json à partir de
https://aka.ms/product2.jsonet enregistrez-le sur votre ordinateur dans le même dossier que celui dans lequel vous avez téléchargé product1.json précédemment. Vous le téléchargerez dans le stockage Blob ultérieurement. -
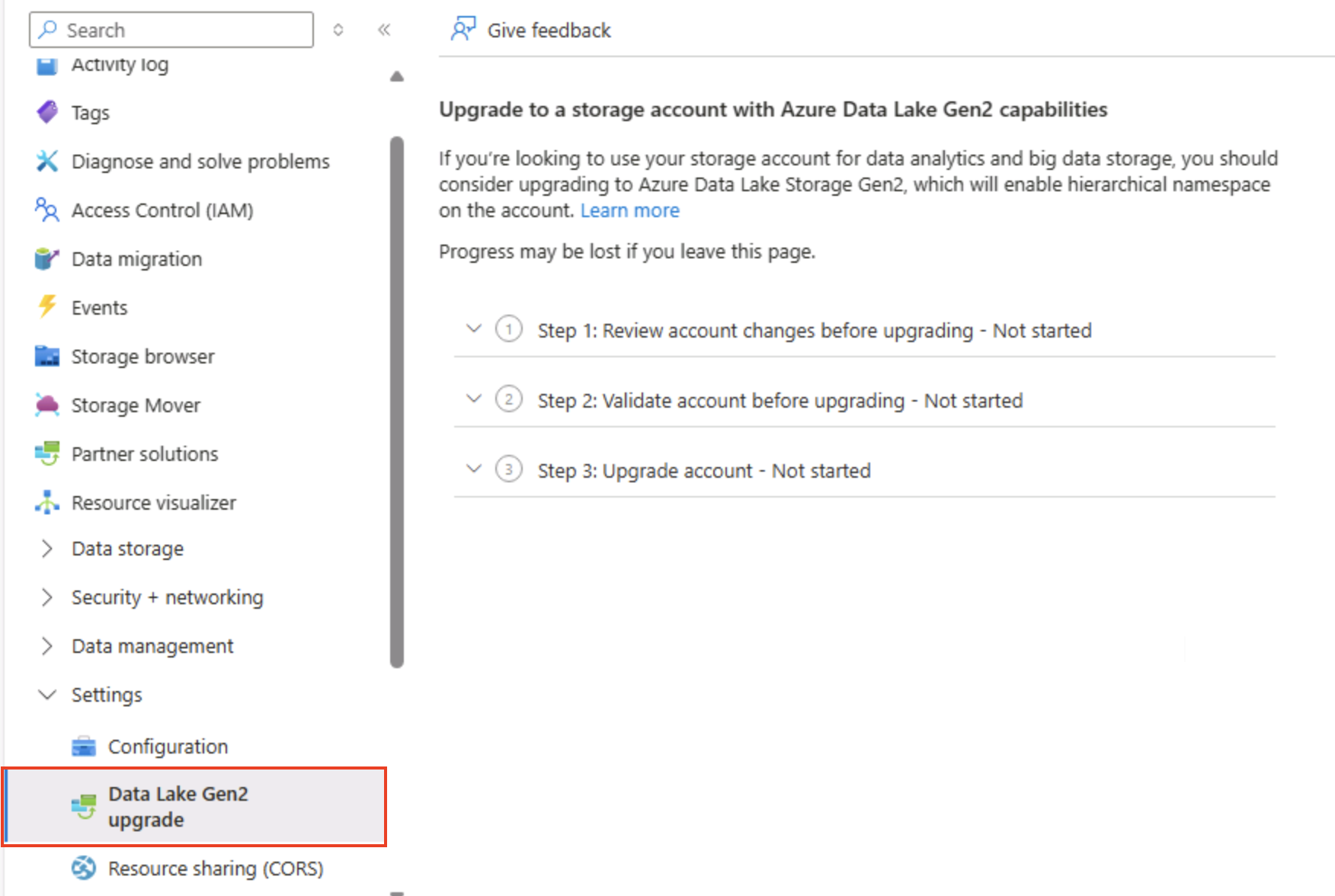
Dans la page de votre compte de stockage sur le portail Azure, sur le côté gauche, faites défiler jusqu’à la section Paramètres, puis sélectionnez Mise à niveau de Data Lake Gen2.
-
Dans la page Mise à niveau de Data Lake Gen2, développez et effectuez chaque étape pour mettre à niveau votre compte de stockage afin d’activer l’espace de noms hiérarchique et la prise en charge d’Azure Data Lake Storage Gen 2. Cette opération peut prendre un certain temps.
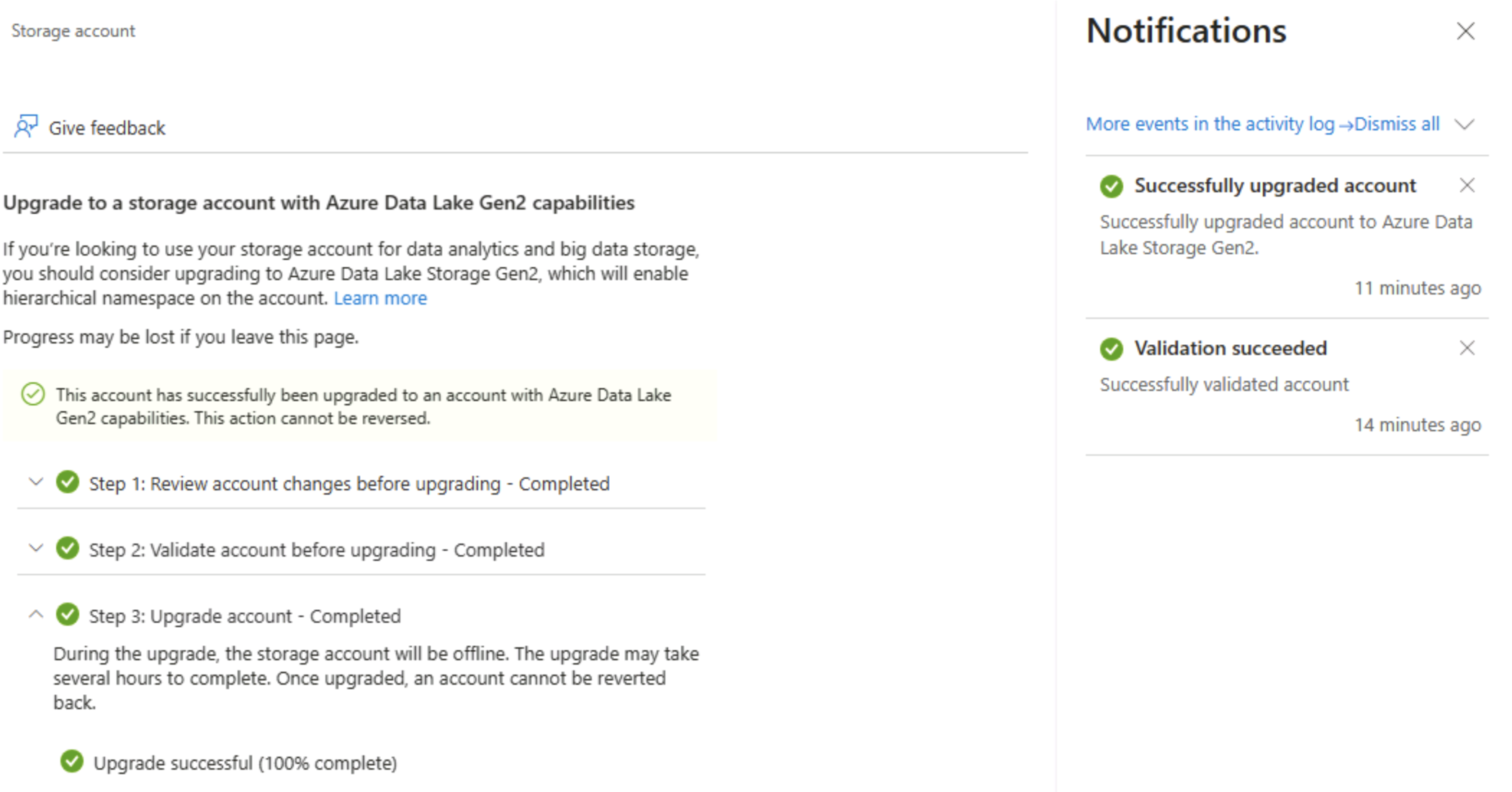
Conseil : La mise à niveau est un changement de fonctionnalité au niveau du compte : les données restent inchangées, mais la sémantique du répertoire est modifiée pour prendre en charge des opérations avancées.
-
Une fois la mise à niveau terminée, dans le volet de gauche, dans la section supérieure, sélectionnez Navigateur de stockage et revenez à la racine de votre conteneur d’objets blob data, qui contient toujours le dossier product_data.
-
Sélectionnez le dossier product_data, puis vérifiez qu’il contient toujours le fichier product1.json que vous avez téléchargé précédemment.
-
Utilisez le bouton ⤒ Charger pour ouvrir le panneau Charger un blob.
-
Dans le panneau Charger un blob, sélectionnez le fichier product2.json que vous avez enregistré sur votre ordinateur local. Ensuite, sélectionnez le bouton Charger.
-
Fermez le panneau Charger un blob s’il est toujours ouvert, puis vérifiez qu’un dossier product_data contient maintenant le fichier product2.json.
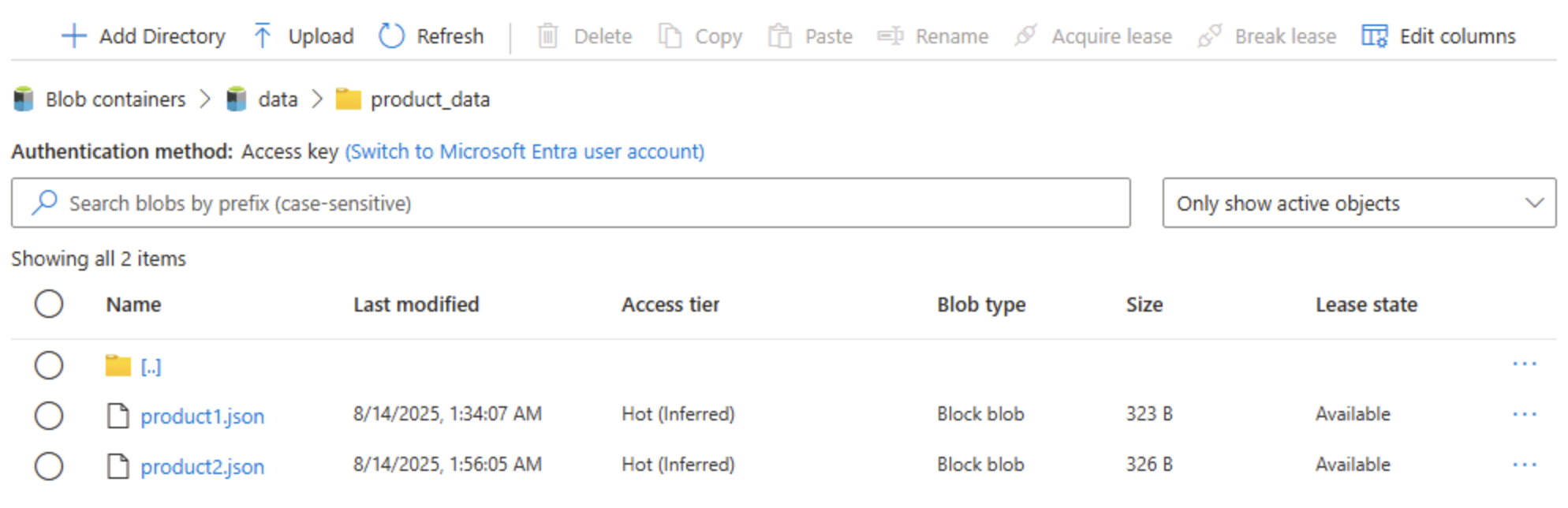
Conseil : L’ajout d’un deuxième fichier après la mise à niveau confirme la continuité sans faille : les blobs existants fonctionnent toujours, et les nouveaux bénéficient d’avantages hiérarchiques tels que les ACL (listes de contrôle d’accès) des répertoires.
-
Sur le côté gauche, dans la section Stockage des données, sélectionnez Conteneurs.
-
Ouvrez le conteneur de données et vérifiez que le dossier product_data que vous avez créé est répertorié.
-
Sélectionnez l’icône ‧‧‧ tout à droite du dossier et notez qu’avec l’espace de noms hiérarchique activé, vous pouvez effectuer des tâches de configuration au niveau du dossier, y compris renommer des dossiers et définir des autorisations.
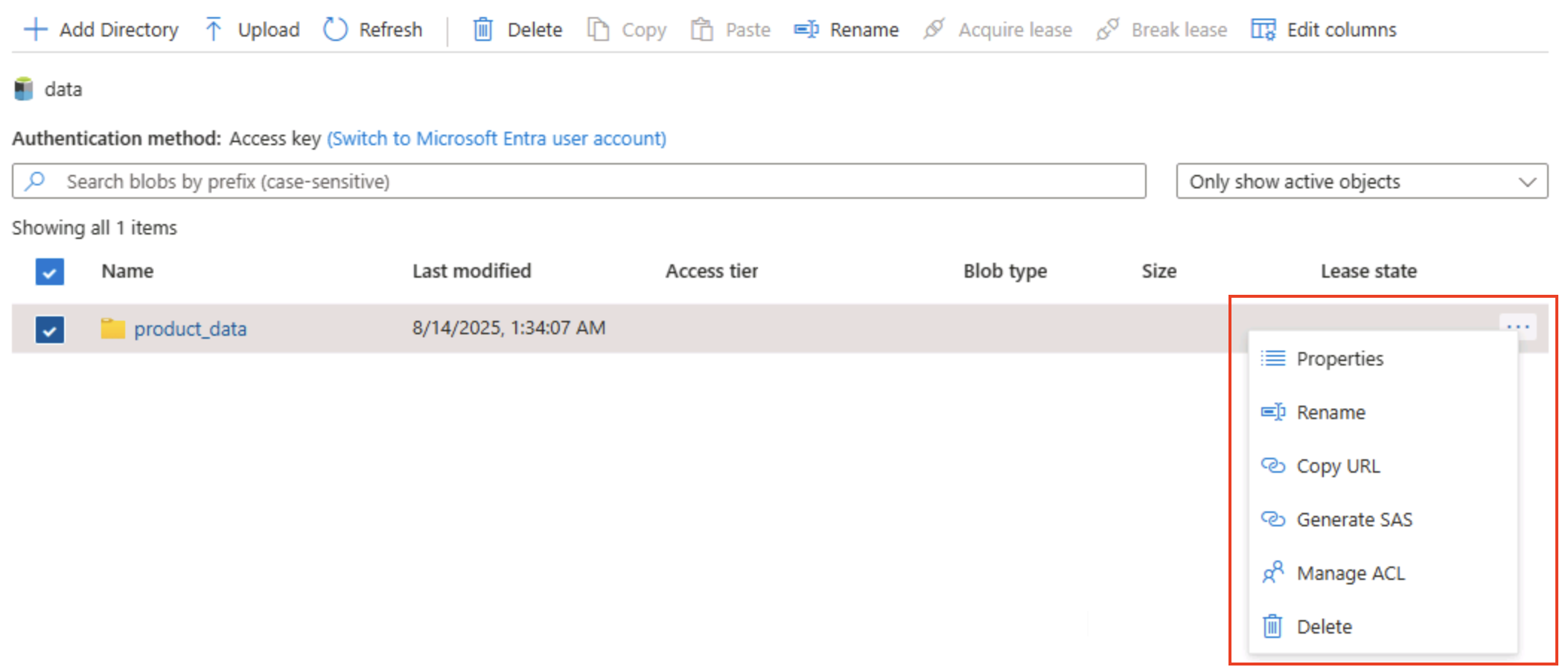
Conseil : Les dossiers réels vous permettent d’appliquer une sécurité à privilège minimal au niveau des dossiers, de renommer en toute sécurité et d’accélérer les listes récursives par rapport à l’analyse de milliers de noms de blobs préfixés.
-
Utilisez l’icône X en haut à droite de la page de données pour fermer la page et revenir à la page Conteneurs.
Explorer Azure Files
Azure Files fournit un moyen de créer des partages de fichiers basés sur le cloud.
Conseil : Azure Files offre des points de terminaison SMB/NFS pour les scénarios lift-and-shift où les applications attendent un système de fichiers traditionnel. Il complète (et non remplace) le stockage d’objets blob en prenant en charge les verrous de fichiers et les outils natifs du système d’exploitation.
-
Dans la page Portail Azure de votre conteneur de stockage, sur le côté gauche, dans la section Stockage des données, sélectionnez Partages de fichiers.

-
Dans la page Partages de fichiers, sélectionnez + Partage de fichiers et ajoutez un nouveau partage de fichiers nommé
fileset de niveau Transaction optimisée. -
Sélectionnez Suivant : Sauvegarde > et désactivez la sauvegarde. Sélectionnez ensuite Vérifier + créer.
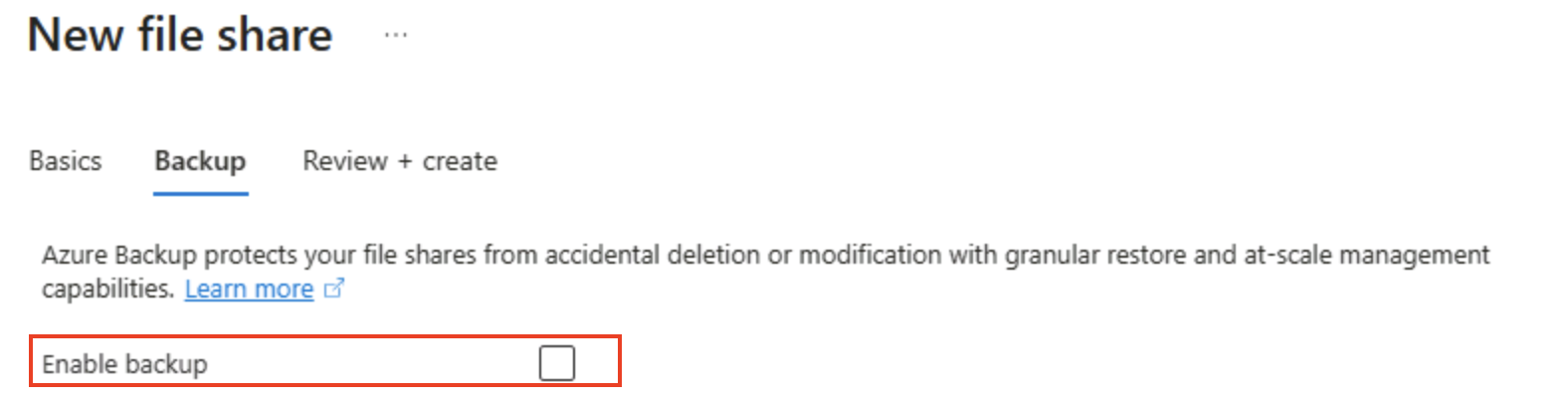
Conseil : La désactivation de la sauvegarde permet de réduire les coûts pour un environnement de laboratoire à courte durée de vie. Vous l’activerez pour assurer la résilience de la production.
-
Dans Partages de fichiers, ouvrez votre nouveau partage de fichiers.
-
En haut de la page, sélectionnez Connecter. Ensuite, dans le volet Connecter, notez qu’il existe des onglets pour les systèmes d’exploitation communs (Windows, Linux et macOS) qui contiennent des scripts que vous pouvez exécuter pour vous connecter au dossier partagé à partir d’un ordinateur client.
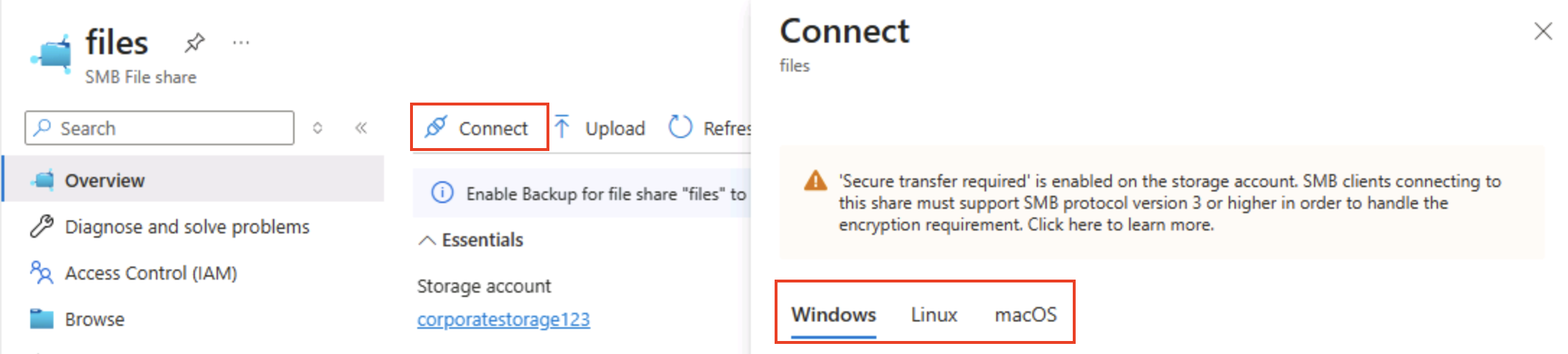
Conseil : Les scripts générés montrent exactement comment monter le partage à l’aide de commandes natives à la plateforme, illustrant les modèles d’accès hybrides à partir de machines virtuelles, de conteneurs ou de serveurs sur site.
-
Fermez le volet Connecter, puis fermez la page fichiers pour revenir à la page Partages de fichiers de votre compte de stockage Azure.
Explorer des tables Azure
Les tables Azure fournissent un magasin clé/valeur pour les applications qui doivent stocker des valeurs de données, mais n’ont pas besoin de la totalité des fonctionnalités et de la structure d’une base de données relationnelle.
Conseil : Le stockage en table offre des requêtes et des jointures riches pour un coût ultra-faible, une flexibilité sans schéma et une évolutivité horizontale, ce qui est idéal pour les journaux, les données IoT ou les profils utilisateur.
-
Dans la page Portail Azure de votre conteneur de stockage, sur le côté gauche, dans la section Stockage des données, sélectionnez Tables.
-
Dans la page Tables, sélectionnez + Table et créez une table nommée
products. -
Une fois la table produits créée, dans le volet de gauche, dans la section supérieure, sélectionnez Navigateur de stockage.
-
Dans l’Explorateur stockage, sélectionnez Tables et vérifiez que la table produits est répertoriée.
-
Sélectionnez la table produits.
-
Dans la page produit, sélectionnez + Ajouter une entité.
- Dans le panneau Ajouter une entité, entrez les valeurs de clés suivantes :
- PartitionKey : 1
- RowKey : 1
Conseil : PartitionKey regroupe les entités associées à distribuer la charge ; RowKey identifie de façon unique dans la partition. Ensemble, ils forment une clé primaire composite rapide pour les recherches.
-
Sélectionnez Ajouter une propriété, puis créez une nouvelle propriété avec les valeurs suivantes :
Nom de la propriété Type Valeur Nom String Widget Prix Double 2.99 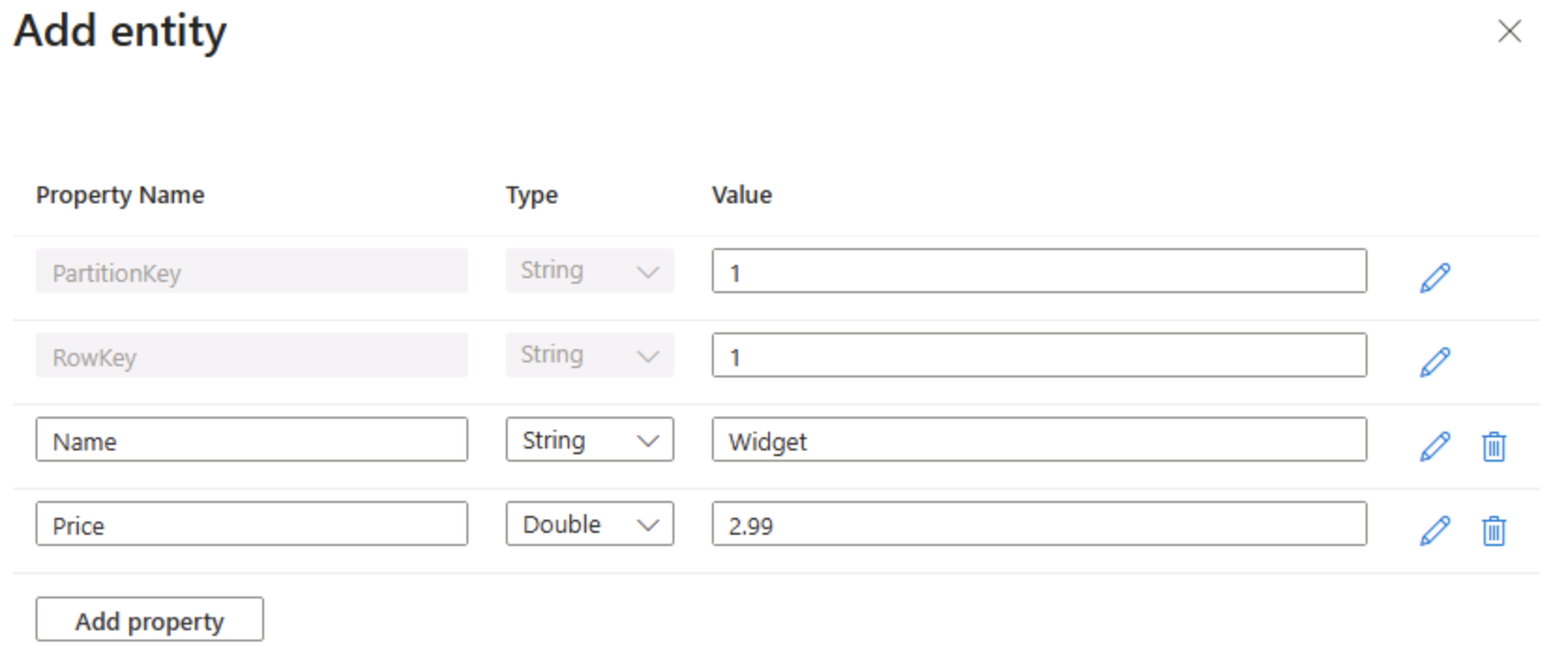
-
Sélectionnez Insérer pour insérer une ligne pour la nouvelle entité de la table.
-
Dans le navigateur de stockage, vérifiez qu’une ligne a été ajoutée à la table produits et qu’une colonne Timestamp a été créée pour indiquer à quel moment la ligne a été modifiée pour la dernière fois.
-
Ajoutez une autre entité à la table produits avec les propriétés suivantes :
Nom de la propriété Type Valeur PartitionKey String 1 RowKey String 2 Nom String Kniknak Prix Double 1.99 Abandonné Boolean true Conseil : L’ajout d’une deuxième entité avec différentes clés et une propriété booléenne supplémentaire illustre la flexibilité de schéma en écriture : les nouveaux attributs ne nécessitent pas de migration.
-
Après avoir inséré la nouvelle entité, vérifiez qu’une ligne contenant le produit abandonné est indiquée dans le tableau.
Vous avez entré manuellement les données dans la table à l’aide de l’interface de navigateur de stockage. Dans un scénario réel, les développeurs d’applications peuvent utiliser le stockage Azure API Table pour créer des applications qui lisent et écrivent des valeurs dans des tables, ce qui en fait une solution rentable et évolutive pour le stockage NoSQL.
Conseil : Si vous avez fini d’explorer le Stockage Azure, vous pouvez supprimer le groupe de ressources que vous avez créé dans cet exercice. La suppression du groupe de ressources est le moyen le plus rapide d’éviter les frais en cours en supprimant chaque ressource que vous avez créée en une seule action.