Erkunden von Datenanalysen in Azure mit Azure Synapse Analytics
In dieser Übung stellen Sie einen Azure Synapse Analytics-Arbeitsbereich in Ihrem Azure-Abonnement bereit und verwenden ihn zum Erfassen und Abfragen von Daten.
Dieses Lab dauert ungefähr 30 Minuten.
Vorbereitung
Sie benötigen ein Azure-Abonnement, in dem Sie Administratorzugriff besitzen.
Bereitstellen eines Azure Synapse Analytics-Arbeitsbereichs
Damit Sie Azure Synapse Analytics verwenden können, müssen Sie eine Azure Synapse Analytics-Arbeitsbereichsressource in Ihrem Azure-Abonnement bereitstellen.
-
Öffnen Sie das Azure-Portal unter https://portal.azure.com, und melden Sie sich mit den Anmeldeinformationen für Ihr Azure-Abonnement an.
Tipp: Stellen Sie sicher, dass Sie sich im Verzeichnis mit Ihrem Abonnement befinden. Dies wird oben rechts unter Ihrer Benutzer-ID angegeben. Falls nicht, klicken Sie auf das Benutzersymbol, und wechseln Sie das Verzeichnis.
- Verwenden Sie das Symbol + Ressource erstellen auf der Startseite des Azure-Portals, um eine neue Ressource zu erstellen.
- Suchen Sie nach
Azure Synapse Analyticsund erstellen Sie eine neue Azure Synapse Analytics-Ressource mit den folgenden Einstellungen:- Abonnement: Geben Sie Ihr Azure-Abonnement an.
- Ressourcengruppe: Erstellen Sie eine neue Ressourcengruppe mit einem geeigneten Namen wie „synapse-rg“.
- Verwaltete Ressourcengruppe: Geben Sie einen geeigneten Namen ein, z. B. „synapse-managed-rg“.
- Arbeitsbereichsname: *Geben Sie einen eindeutigen Arbeitsbereichsnamen ein, z. B. „synapse-ws-
“* . - Region:Wählen Sie eine der folgenden Regionen aus:
- Australien (Osten)
- USA (Mitte)
- USA (Ost) 2
- Nordeuropa
- USA Süd Mitte
- Asien, Südosten
- Vereinigtes Königreich, Süden
- Europa, Westen
- USA (Westen)
- USA, Westen 2
- Data Lake Storage Gen 2 auswählen: Aus Abonnement
- Kontoname: *Erstellen Sie ein neues Konto mit einem eindeutigen Namen, z. B. „datalake
“.* - Dateisystemname: *Erstellen Sie ein neues Dateisystem mit einem eindeutigen Namen, z. B. „fs
“.*
- Kontoname: *Erstellen Sie ein neues Konto mit einem eindeutigen Namen, z. B. „datalake
Hinweis: Ein Synapse Analytics-Arbeitsbereich erfordert zwei Ressourcengruppen in Ihrem Azure-Abonnement: eine für Ressourcen, die Sie explizit erstellen, und eine andere für verwaltete Ressourcen, die vom Dienst verwendet werden. Außerdem ist ein Data Lake-Speicherkonto erforderlich, in dem Daten, Skripts und andere Artefakte gespeichert werden.
- Abonnement: Geben Sie Ihr Azure-Abonnement an.
- Wenn Sie diese Details eingegeben haben, klicken Sie auf Überprüfen + Erstellen und dann auf Erstellen, um den Arbeitsbereich zu erstellen.
- Warten Sie, bis der Arbeitsbereich erstellt wurde. Dies kann etwa fünf Minuten dauern.
- Wenn die Bereitstellung abgeschlossen ist, wechseln Sie zur erstellten Ressourcengruppe, und überprüfen Sie, ob sie Ihren Synapse Analytics-Arbeitsbereich und ein Data Lake-Speicherkonto enthält.
- Wählen Sie Ihren Synapse-Arbeitsbereich aus, und klicken Sie auf der Seite Übersicht der Karte Synapse Studio öffnen auf die Option Öffnen, um Synapse Studio auf einer neuen Browserregisterkarte zu öffnen. Synapse Studio ist eine webbasierte Schnittstelle, die Sie zum Arbeiten mit Ihrem Synapse Analytics-Arbeitsbereich verwenden können.
-
Verwenden Sie auf der linken Seite von Synapse Studio das Symbol ››, um das Menü zu erweitern. Dadurch werden die verschiedenen Seiten in Synapse Studio angezeigt, die Sie zum Verwalten von Ressourcen und zum Ausführen von Datenanalyseaufgaben verwenden, wie im Folgenden gezeigt:
Erfassen von Daten
Eine der wichtigsten Aufgaben, die Sie mit Azure Synapse Analytics ausführen können, ist das Definieren von Pipelines, die Daten aus einer Vielzahl von Quellen zur Analyse in Ihren Arbeitsbereich übertragen (und bei Bedarf transformieren).
- Wählen Sie in Synapse Studio auf der Startseite die Option Erfassen aus, um das Tool Daten kopieren zu öffnen.
- Stellen Sie im Tool „Daten kopieren “im Schritt Eigenschaften sicher, dass die Optionen Integrierte Kopieraufgabe und Jetzt einmal ausführen ausgewählt sind, und klicken Sie auf Weiter >.
- Wählen Sie im Schritt Quelle im Teilschritt Dataset die folgenden Einstellungen aus:
- Quelltyp: Alle
- Verbindung: Erstellen Sie eine neue Verbindung, und wählen Sie im Bereich Neue Verbindung auf der Registerkarte Generisches Protokoll die Option HTTP aus. Erstellen Sie dann mithilfe der folgenden Einstellungen eine Verbindung zu einer Datendatei:
- Name:
AdventureWorks Products - Beschreibung:
Product list via HTTP - Verbindung über Integration Runtime herstellen: AutoResolveIntegrationRuntime
- Basis-URL:
https://raw.githubusercontent.com/MicrosoftLearning/DP-900T00A-Azure-Data-Fundamentals/master/Azure-Synapse/products.csv - Überprüfung des Serverzertifikats: Aktivieren
- Authentifizierungstyp: Anonym
- Name:
- Stellen Sie nach dem Erstellen der Verbindung sicher, dass im Teilschritt Quelle/Dataset die folgenden Einstellungen ausgewählt sind, und klicken Sie dann auf Weiter >:
- Relative URL: Nicht ausfüllen
- Anforderungsmethode: GET
- Zusätzliche Kopfzeilen: Nicht ausfüllen
- Binärkopie: Nichtausgewählt
- Anforderungstimeout: Nicht ausfüllen
- Maximal zulässige Anzahl paralleler Verbindungen: Nicht ausfüllen
- Wählen Sie im Schritt Quelle im Teilschritt Konfiguration die Option Vorschaudaten aus, um eine Vorschau der von Ihrer Pipeline erfassten Produktdaten anzuzeigen, und schließen Sie dann die Vorschau.
- Stellen Sie nach dem Anzeigen der Datenvorschau sicher, dass im Teilschritt Quelle/Konfiguration die folgenden Einstellungen ausgewählt sind, und klicken Sie dann auf Weiter >:
- Dateiformat: DelimitedText
- Spaltentrennzeichen: Komma (,)
- Zeilen-Trennzeichen: Zeilenvorschub (\n)
- Erste Zeile ist Überschrift: Ausgewählt
- Komprimierungstyp: Keiner
- Wählen Sie im Schritt Ziel im Teilschritt Dataset die folgenden Einstellungen aus:
- Zieltyp: Azure Data Lake Storage Gen 2
- Verbindung: Wählen Sie die vorhandene Verbindung mit Ihrem Data Lake-Speicher aus (diese wurde bei der Erstellung des Arbeitsbereichs für Sie erstellt).
- Stellen Sie nach Auswahl der Verbindung sicher, dass im Schritt Ziel/Dataset die folgenden Einstellungen ausgewählt sind, und klicken Sie dann auf Weiter > :
- Ordnerpfad: Navigieren Sie zum Ihrem Dateisystemordner.
- Dateiname: products.csv
- Kopierverhalten: Keins
- Maximal zulässige Anzahl paralleler Verbindungen: Nicht ausfüllen
- Blockgröße (MB): Nicht ausfüllen
- Stellen Sie im Schritt Ziel im Teilschritt Konfiguration sicher, dass die folgenden Eigenschaften ausgewählt sind. Klicken Sie anschließend auf Weiter >.
- Dateiformat: DelimitedText
- Spaltentrennzeichen: Komma (,)
- Zeilen-Trennzeichen: Zeilenvorschub (\n)
- Header zu Datei hinzufügen: Ausgewählt
- Komprimierungstyp: Keiner
- Maximale Zeilenanzahl pro Datei: Nicht ausfüllen
- Dateinamenpräfix: Nicht ausfüllen
- Konfigurieren Sie im Schritt Einstellungen die folgenden Einstellungen, und klicken Sie dann auf Weiter >.
- Aufgabenname: Kopieren von Produkten
- Aufgabenbeschreibung: Kopieren von Produktdaten
- Fehlertoleranz: Nicht ausfüllen
- Protokollierung aktivieren: Nicht ausgewählt
- Staging aktivieren: Nicht ausgewählt
- Lesen Sie im Schritt Überprüfen und fertig stellen im Teilschritt Überprüfen die Zusammenfassung, und klicken Sie dann auf Weiter >.
- Warten Sie im Teilschritt Bereitstellung, bis die Pipeline bereitgestellt wurde, und klicken Sie dann auf Fertig stellen.
- Wählen Sie in Synapse Studio die Seite Überwachen aus, und warten Sie, bis auf der Registerkarte Pipelineausführung die Pipeline Produkte kopieren mit dem Status Erfolgreich ausgeführt wurde. (Über die Schaltfläche ↻ Aktualisieren auf der Seite „Pipelineausführung“ können Sie den Status aktualisieren.)
-
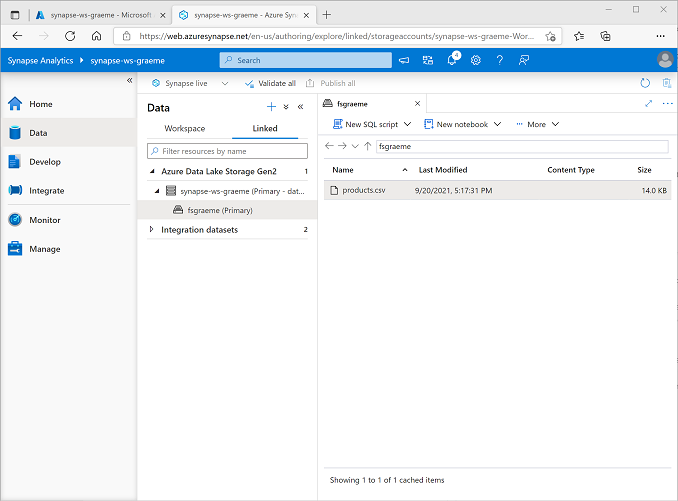
Wählen Sie auf der Seite Daten die Registerkarte Verknüpft aus, und erweitern Sie die Hierarchie Azure Data Lake Storage Gen 2, bis der Dateispeicher für Ihren Synapse-Arbeitsbereich angezeigt wird. Wählen Sie dann den Dateispeicher aus, um zu überprüfen, ob eine Datei mit dem Namen products.csv an diesen Speicherort kopiert wurde, wie hier gezeigt:
Verwenden eines SQL-Pools zum Analysieren von Daten
Nachdem Sie nun einige Daten in Ihrem Arbeitsbereich erfasst haben, können Sie Synapse Analytics verwenden, um die Daten abzufragen und zu analysieren. Eine der gängigsten Methoden zum Abfragen von Daten ist die Verwendung von SQL. In Synapse Analytics können Sie zum Ausführen von SQL-Code einen SQL-Pool verwenden.
- Klicken Sie in Synapse Studio mit der rechten Maustaste auf die products.csv-Datei im Dateispeicher Ihres Synapse-Arbeitsbereichs, zeigen Sie auf Neues SQL-Skript, und wählen Sie Die ersten 100 Zeilen auswählen aus.
-
Überprüfen Sie im geöffneten Bereich SQL-Skript 1 den generierten SQL Code, der in etwa wie der folgende lauten sollte:
-- This is auto-generated code SELECT TOP 100 * FROM OPENROWSET( BULK 'https://datalakexx.dfs.core.windows.net/fsxx/products.csv', FORMAT = 'CSV', PARSER_VERSION='2.0' ) AS [result]Dieser Code öffnet ein Rowset aus der importierten Textdatei und ruft die ersten 100 Datenzeilen ab.
- Vergewissern Sie sich, dass in der Liste Verbinden mit die Option Integriert ausgewählt ist. Dies entspricht dem integrierten SQL-Pool, der mit Ihrem Arbeitsbereich erstellt wurde.
-
Verwenden Sie die Symbolleistenschaltfläche ▷ Ausführen, um den SQL-Code auszuführen, und überprüfen Sie die Ergebnisse, die in etwa wie folgt aussehen sollten:
C1 c2 c3 c4 ProductID ProductName Kategorie ListPrice 771 Mountain-100 Silver, 38 Mountainbikes 3399.9900 772 Mountain-100 Silver, 42 Mountainbikes 3399.9900 … … … … -
Beachten Sie, dass die Ergebnisse aus vier Spalten mit den Namen C1, C2, C3 und C4 bestehen und dass die erste Zeile in den Ergebnissen die Namen der Datenfelder enthält. Um dieses Problem zu beheben, fügen Sie der OPENROWSET-Funktion wie hier gezeigt einen Parameter HEADER_ROW = TRUE hinzu (ersetzen Sie dabei datalakexx und fsxx durch die Namen Ihres Data Lake-Speicherkontos und -Dateisystems), und führen Sie dann die Abfrage erneut aus:
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://datalakexx.dfs.core.windows.net/fsxx/products.csv', FORMAT = 'CSV', PARSER_VERSION='2.0', HEADER_ROW = TRUE ) AS [result]Die Ergebnisse sehen nun wie folgt aus:
ProductID ProductName Kategorie ListPrice 771 Mountain-100 Silver, 38 Mountainbikes 3399.9900 772 Mountain-100 Silver, 42 Mountainbikes 3399.9900 … … … … -
Ändern Sie die Abfrage wie folgt (ersetzen Sie datalakexx und fsxx durch die Namen Ihres Data Lake-Speicherkontos und Dateisystems):
SELECT Category, COUNT(*) AS ProductCount FROM OPENROWSET( BULK 'https://datalakexx.dfs.core.windows.net/fsxx/products.csv', FORMAT = 'CSV', PARSER_VERSION='2.0', HEADER_ROW = TRUE ) AS [result] GROUP BY Category; -
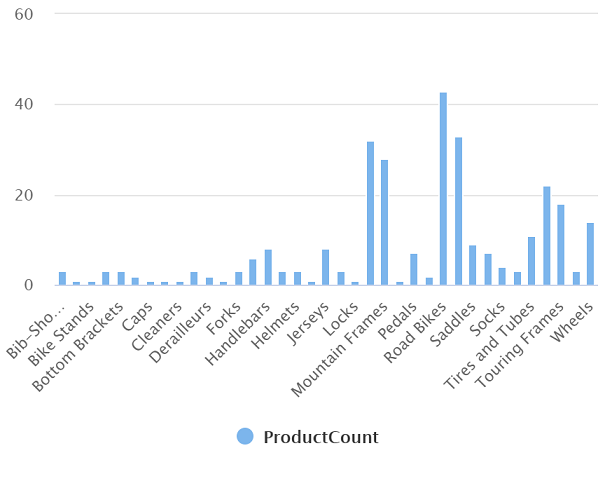
Führen Sie die geänderte Abfrage aus, die ein Resultset zurückgeben sollte, das die folgende Produktanzahl in den jeweiligen Kategorien enthält:
Kategorie ProductCount Trägershorts 3 Fahrradträger 1 … … -
Ändern Sie im Bereich Eigenschaften für SQL-Skript 1 den Namen in
Count Products by Category. Klicken Sie dann auf der Symbolleiste auf Veröffentlichen, um das Skript zu speichern. -
Schließen Sie den Skriptbereich Produkte nach Kategorie zählen.
-
Wählen Sie in Synapse Studio die Seite Entwickeln aus. Wie Sie sehen, ist hier Ihr veröffentlichtes SQL-Skript Produkte nach Kategorie zählen gespeichert.
-
Wählen Sie das SQL-Skript Produkte nach Kategorie zählen aus, um es erneut zu öffnen. Vergewissern Sie sicher, dass das Skript mit dem integrierten SQL-Pool verbunden ist, und führen Sie es aus, um die Produktanzahl abzurufen.
- Wählen Sie im Ergebnisbereich die Diagrammansicht aus, und nehmen Sie folgende Einstellungen für das Diagramm vor:
- Diagrammtyp: Spalte
- Kategoriespalte: Kategorie
- Legendenspalten (Reihen): ProductCount
- Legendenposition: Unten zentriert
- Legendenbeschriftung (Reihen): Nicht ausfüllen
- Mindestwert für Legende (Reihe): Nicht ausfüllen
- Höchstwert für Legende (Reihen): Nicht ausfüllen
- Kategoriebezeichnung: Nicht ausfüllen
Das resultierende Diagramm sollte in etwa wie folgt aussehen:
Verwenden eines Spark-Pools zum Analysieren von Daten
Während SQL eine gängige Sprache zum Abfragen strukturierter Datasets ist, finden viele Datenanalysten Sprachen wie Python nützlich, um Daten zu untersuchen und für die Analyse vorzubereiten. In Azure Synapse Analytics können Sie Python-Code (und anderen Code) in einem Spark-Pool ausführen, der eine auf Apache Spark basierende verteilte Datenverarbeitungsengine verwendet.
- Wählen Sie in Synapse Studio die Seite Verwalten aus.
- Wählen Sie die Registerkarte Apache Spark-Pools aus, und verwenden Sie dann das Symbol + Neu, um einen neuen Spark-Pool mit den folgenden Einstellungen zu erstellen:
- Name des Apache Spark-Pools: Spark
- Knotengrößenfamilie: Arbeitsspeicheroptimiert
- Knotengröße: Klein (4 virtuelle Kerne/32 GB)
- Autoskalierung: Aktiviert
- Anzahl der Knoten: 3—-3
- Überprüfen und erstellen Sie den Spark-Pool, und warten Sie, bis er bereitgestellt ist (dies kann einige Minuten dauern).
- Wenn der Spark-Pool bereitgestellt wurde, navigieren Sie in Synapse Studio auf der Seite Daten zum Dateisystem für Ihren Synapse-Arbeitsbereich. Klicken Sie dann mit der rechten Maustaste auf die Datei ** products.csv, zeigen Sie auf **Neues Notebook, und wählen Sie In DataFrame laden aus.
- Wählen Sie im daraufhin angezeigten Bereich Notebook 1 in der Liste Anfügen an den Spark-Pool aus, den Sie zuvor erstellt haben, und stellen Sie sicher, dass die Sprache auf PySpark (Python) festgelegt ist.
-
Überprüfen Sie den Code in der ersten (und einzigen) Zelle des Notebooks, die wie folgt aussehen sollte:
%%pyspark df = spark.read.load('abfss://fsxx@datalakexx.dfs.core.windows.net/products.csv', format='csv' ## If header exists uncomment line below ##, header=True ) display(df.limit(10)) -
Wählen Sie ▷ Ausführen links neben der Codezelle aus, um diese auszuführen, und warten Sie auf die Ergebnisse. Wenn Sie eine Zelle zum ersten Mal in einem Notebook ausführen, wird der Spark-Pool gestartet. Es kann also etwa eine Minute dauern, bis Ergebnisse zurückgegeben werden.
Hinweis: Wenn ein Fehler auftritt, weil der Python-Kernel noch nicht verfügbar ist, führen Sie die Zelle erneut aus.
-
Letztlich sollten die Ergebnisse unterhalb der Zelle angezeigt werden und in etwa wie folgt aussehen:
c0 c1 c2 c3 ProductID ProductName Kategorie ListPrice 771 Mountain-100 Silver, 38 Mountainbikes 3399.9900 772 Mountain-100 Silver, 42 Mountainbikes 3399.9900 … … … … -
Aufheben der Auskommentierung der Zeile ,header=True (da die products.csv-Datei die Spaltenüberschriften in der ersten Zeile enthält), sodass Ihr Code wie folgt aussieht:
%%pyspark df = spark.read.load('abfss://fsxx@datalakexx.dfs.core.windows.net/products.csv', format='csv' ## If header exists uncomment line below , header=True ) display(df.limit(10)) -
Führen Sie die Zelle erneut aus, und überprüfen Sie, ob die Ergebnisse wie folgt aussehen:
ProductID ProductName Kategorie ListPrice 771 Mountain-100 Silver, 38 Mountainbikes 3399.9900 772 Mountain-100 Silver, 42 Mountainbikes 3399.9900 … … … … Beachten Sie, dass das erneute Ausführen der Zelle weniger Zeit in Anspruch nimmt, da der Spark-Pool bereits gestartet wurde.
- Verwenden Sie unter den Ergebnissen das Symbol + Code, um dem Notebook eine neue Codezelle hinzuzufügen.
-
Fügen Sie in der neuen leeren Codezelle den folgenden Code hinzu:
df_counts = df.groupBy(df.Category).count() display(df_counts) -
Führen Sie die neue Codezelle aus, indem Sie links davon auf ▷ Ausführen klicken, und überprüfen Sie die Ergebnisse, die in etwa wie folgt aussehen sollten:
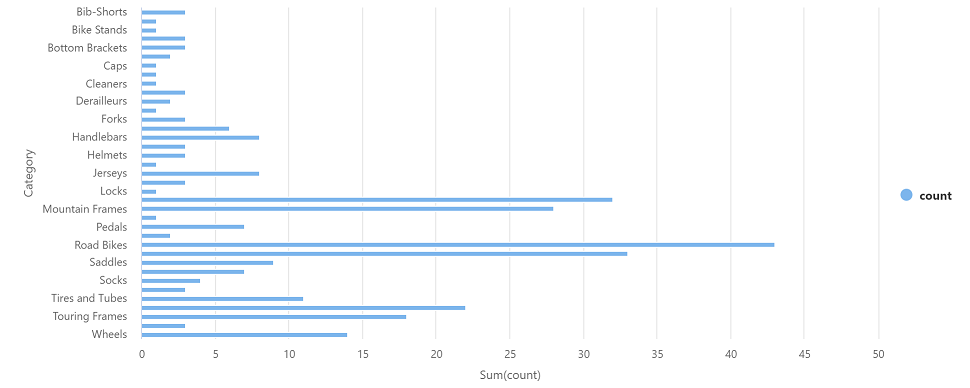
Category count Headsets 3 Räder 14 … … -
Wählen Sie in der Ergebnisausgabe für die Zelle die Diagrammansicht aus. Das resultierende Diagramm sollte in etwa wie folgt aussehen:
- Schließen Sie den Bereich Notebook 1, und verwerfen Sie Ihre Änderungen.
Löschen von Azure-Ressourcen
Wenn Sie sich mit Azure Synapse Analytics vertraut gemacht haben, sollten Sie die erstellten Ressourcen löschen, um unnötige Azure-Kosten zu vermeiden.
- Schließen Sie die Registerkarte mit Synapse Studio, und kehren Sie zum Azure-Portal zurück.
- Wählen Sie auf der Startseite des Azure-Portals die Option Ressource erstellen aus.
- Wählen Sie die Ressourcengruppe für Ihren Synapse Analytics-Arbeitsbereich (nicht die verwaltete Ressourcengruppe) aus, und überprüfen Sie, ob sie den Synapse-Arbeitsbereich, das Speicherkonto und den Spark-Pool für Ihren Arbeitsbereich enthält.
- Wählen Sie oben auf der Seite Übersicht für Ihre Ressourcengruppe die Option Ressourcengruppe löschen aus.
-
Geben Sie den Namen der Ressourcengruppe ein, um zu bestätigen, dass Sie sie löschen möchten, und wählen Sie Löschen aus.
Nach ein paar Minuten werden Ihr Azure Synapse-Arbeitsbereich und der ihm zugeordnete verwaltete Arbeitsbereich gelöscht.