Erkunden von Azure Storage
In dieser Übung erfahren Sie, wie Sie ein Azure Storage-Konto bereitstellen und konfigurieren, und lernen dessen wichtigsten Dienste kennen: Blob Storage, Data Lake Storage Gen2, Azure Files und Azure Tables. Lernen Sie, wie Sie Container erstellen, Daten hochladen, hierarchische Namespaces aktivieren, Dateifreigaben einrichten und Tabellenentitäten verwalten. Diese Fähigkeiten helfen Ihnen zu verstehen, wie sie nicht relationale Daten in Azure für verschiedene Analyse- und Anwendungsszenarien speichern, organisieren und sichern.
Dieses Lab dauert ungefähr 15 Minuten.
Tipp: Wenn Sie den Zweck jeder Aktion verstehen, können Sie später Speicherlösungen entwerfen, die Kosten, Leistung, Sicherheit und Analyseziele ausgleichen. Diese kurzen Warum-Hinweise verknüpfen jeden Schritt mit einem praktischen Grund.
Vor der Installation
Sie benötigen ein Azure-Abonnement, in dem Sie Administratorzugriff besitzen.
Bereitstellen eines Azure Storage-Kontos
Der erste Schritt bei der Verwendung von Azure Storage ist die Bereitstellung eines Azure Storage-Kontos in Ihrem Azure-Abonnement.
Tipp: Ein Speicherkonto ist die sichere, abrechnende Grenze für alle Azure Storage-Dienste (Blobs, Dateien, Warteschlangen, Tabellen). Richtlinien, Redundanz, Verschlüsselung, Netzwerk und Zugriffssteuerung gelten ab hier für alle darunterliegenden Ebenen.
-
Melden Sie sich beim Azure-Portal an, falls Sie dies noch nicht getan haben.
-
Wählen Sie auf der Startseite des Azure-Portals in der oberen linken Ecke die Option + Ressource erstellen und suchen Sie nach
Storage account. Wählen Sie dann auf der resultierenden Seite Speicherkonto die Option Erstellen aus.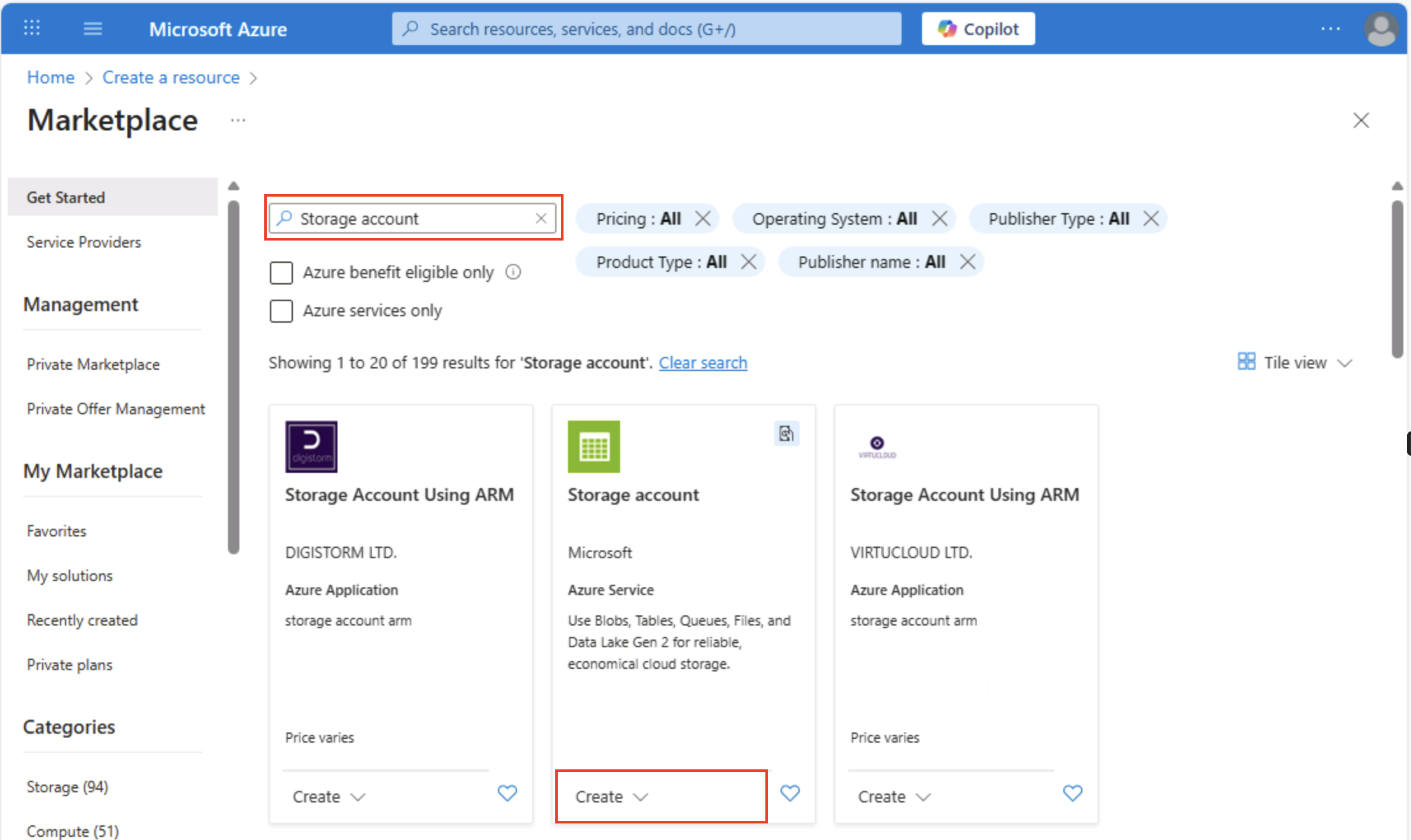
-
Geben Sie auf der Seite Erstellen eines Speicherkontos die folgenden Werte ein:
- Abonnement: Wählen Sie Ihr Azure-Abonnement.
- Ressourcengruppe: Erstellen Sie eine neue Ressourcengruppe mit einem Namen Ihrer Wahl.
- Speicherkontoname: Geben Sie einen eindeutigen Namen für Ihr Speicherkonto mit Kleinbuchstaben und Zahlen ein.
- Region: Wählen Sie einen beliebigen verfügbaren Standort aus.
- Leistung: Standard
- Redundanz: Lokal redundanter Speicher (LRS)
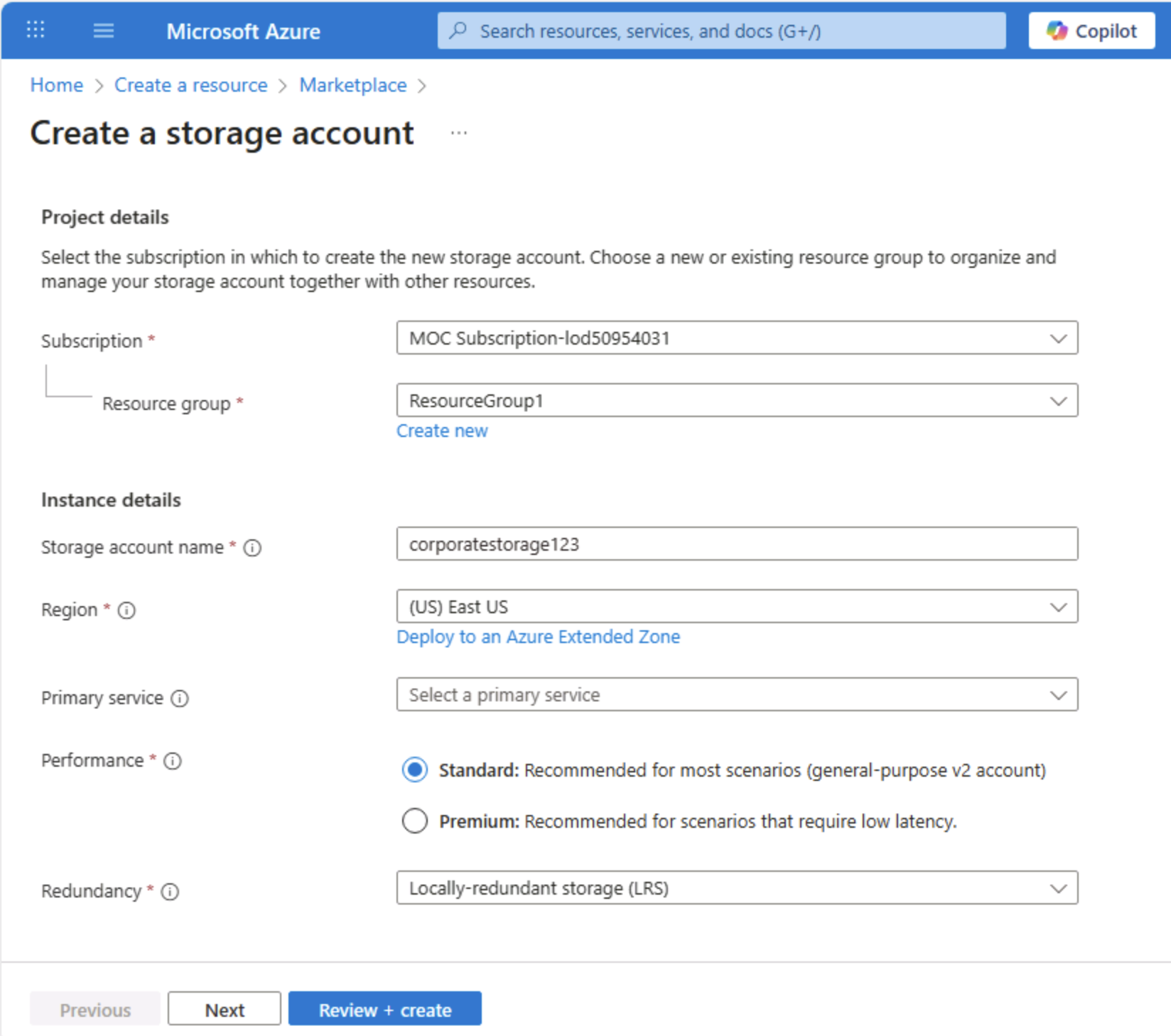
Tipp: Eine neue Ressourcengruppe erleichtert die Bereinigung. Standard und LRS ist der Basisplan der niedrigsten Kosten, der für Lernen gut geeignet ist. LRS hält drei synchrone Kopien in einer Region, die für nicht kritische Demodaten geeignet sind, ohne für die Georeplikation zu bezahlen.
-
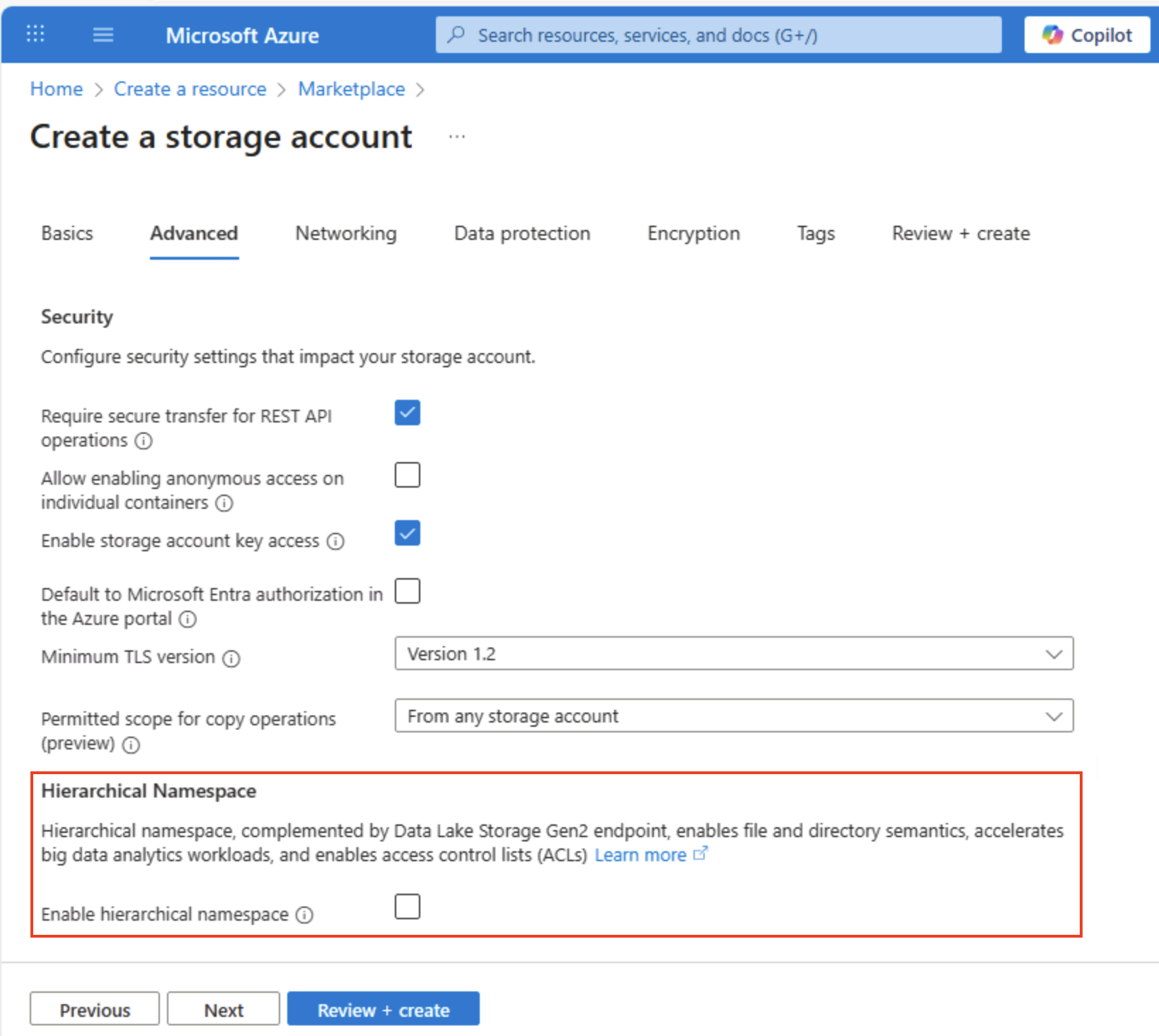
Wählen Sie Weiter: Erweitert > aus, und zeigen Sie die Optionen der erweiterten Konfiguration an. Beachten Sie insbesondere, dass Sie hier den hierarchischen Namespace aktivieren können, um Azure Data Lake Storage Gen2 zu unterstützen. Lassen Sie diese Option deaktiviert (Sie aktivieren sie später), und wählen Sie dann Weiter: Netzwerk > aus, um die Netzwerkoptionen für Ihr Speicherkonto anzuzeigen.
-
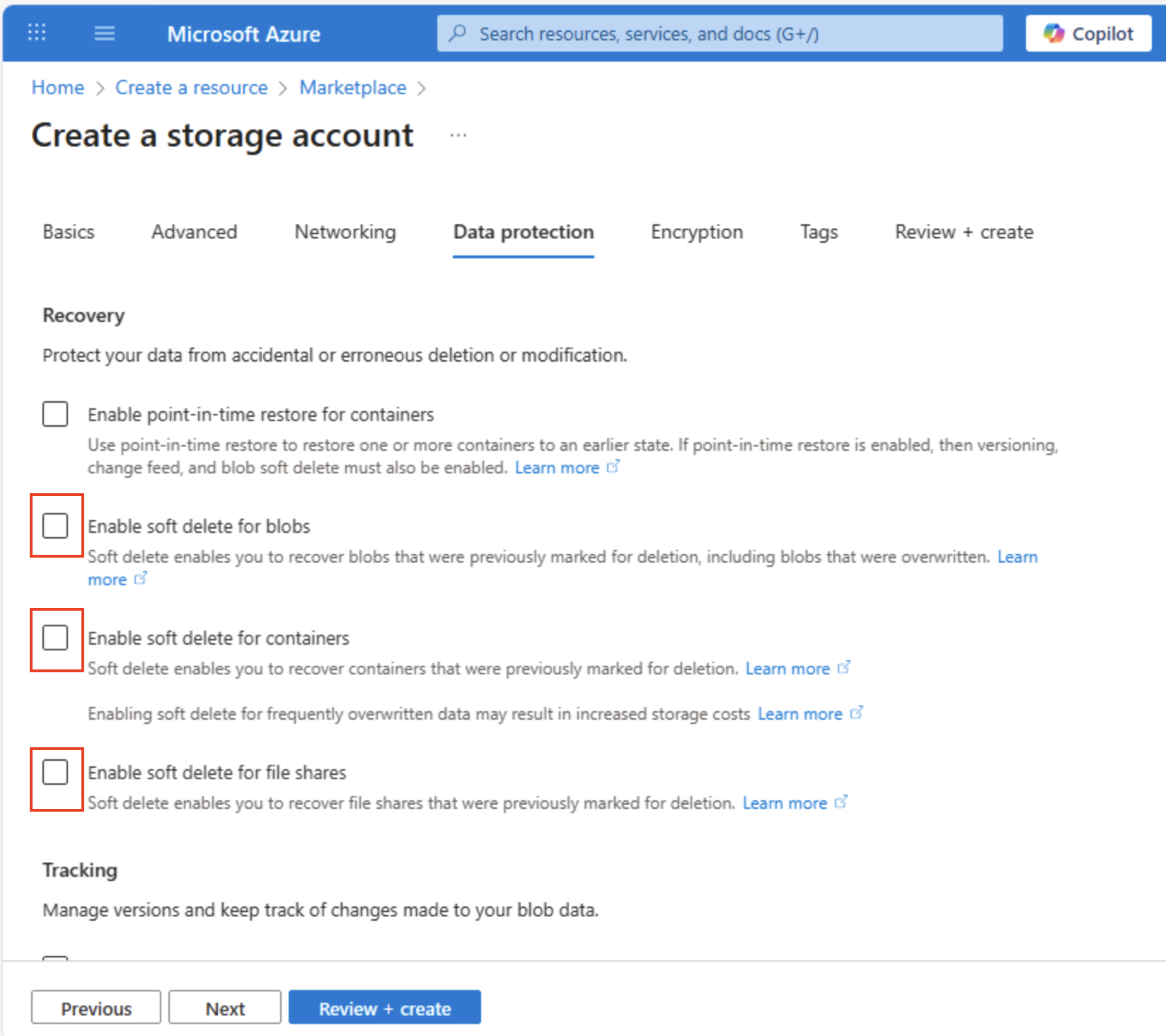
Wählen Sie Weiter: Datenschutz > aus, und deaktivieren Sie dann im Abschnitt Wiederherstellung alle Optionen unter Vorläufiges Löschen aktivieren. Diese Optionen behalten gelöschte Dateien für die nachfolgende Wiederherstellung bei, können aber später Probleme verursachen, wenn Sie den hierarchischen Namespace aktivieren.
-
Fahren Sie mit den verbleibenden Seiten Weiter > fort, ohne die Standardeinstellungen zu ändern. Warten Sie dann auf der Seite Überprüfen, bis Ihre Auswahl überprüft wurde, und wählen Sie Erstellen aus, um Ihr Azure Storage-Konto zu erstellen.
-
Warten Sie, bis die Bereitstellung abgeschlossen ist. Wechseln Sie dann zu der Ressource, die bereitgestellt wurde.
Erkunden von Blobspeicher
Nachdem Sie nun über ein Azure Storage-Konto verfügen, können Sie einen Container für Blobdaten erstellen.
Tipp: Ein Container gruppiert Blobs und ist die erste Bereichsebene für die Zugriffssteuerung. Wenn Sie mit einfachem Blobspeicher starten (ohne hierarchischen Namespace), sehen Sie ein virtuelles Ordnerverhalten, das Sie später mit Data Lake Gen2 vergleichen können.
-
Laden Sie die JSON-Datei product1.json von
https://aka.ms/product1.jsonherunter, und speichern Sie sie auf Ihrem Computer (Sie können sie in einem beliebigen Ordner speichern. Später laden Sie sie in Blobspeicher hoch).Wenn die JSON-Datei in Ihrem Browser angezeigt wird, speichern Sie die Seite als product1.json.
-
Wählen Sie auf der Azure-Portalseite für Ihren Speichercontainer auf der linken Seite im Abschnitt Datenspeicher die Option Container aus.
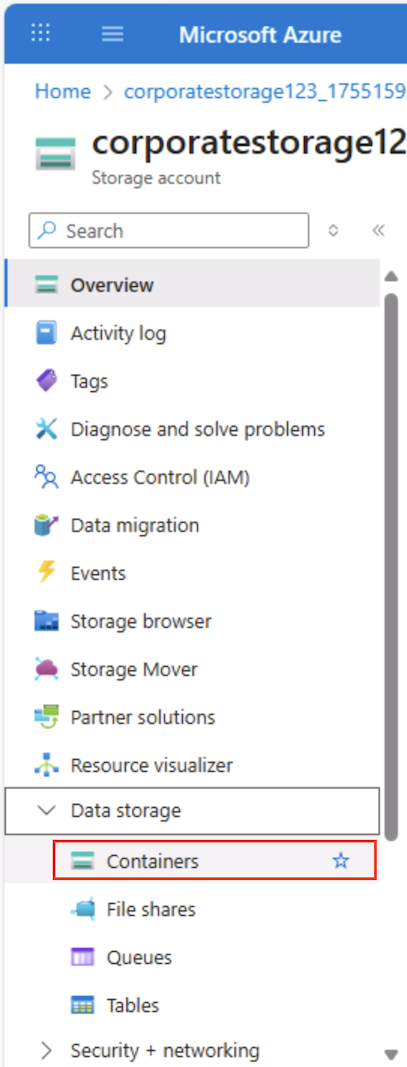
-
Wählen Sie auf der Seite Container die Option + Container hinzufügen aus und fügen Sie einen neuen Container mit dem Namen
dataund der anonymen Zugriffsebene Privat (kein anonymer Zugriff) hinzu.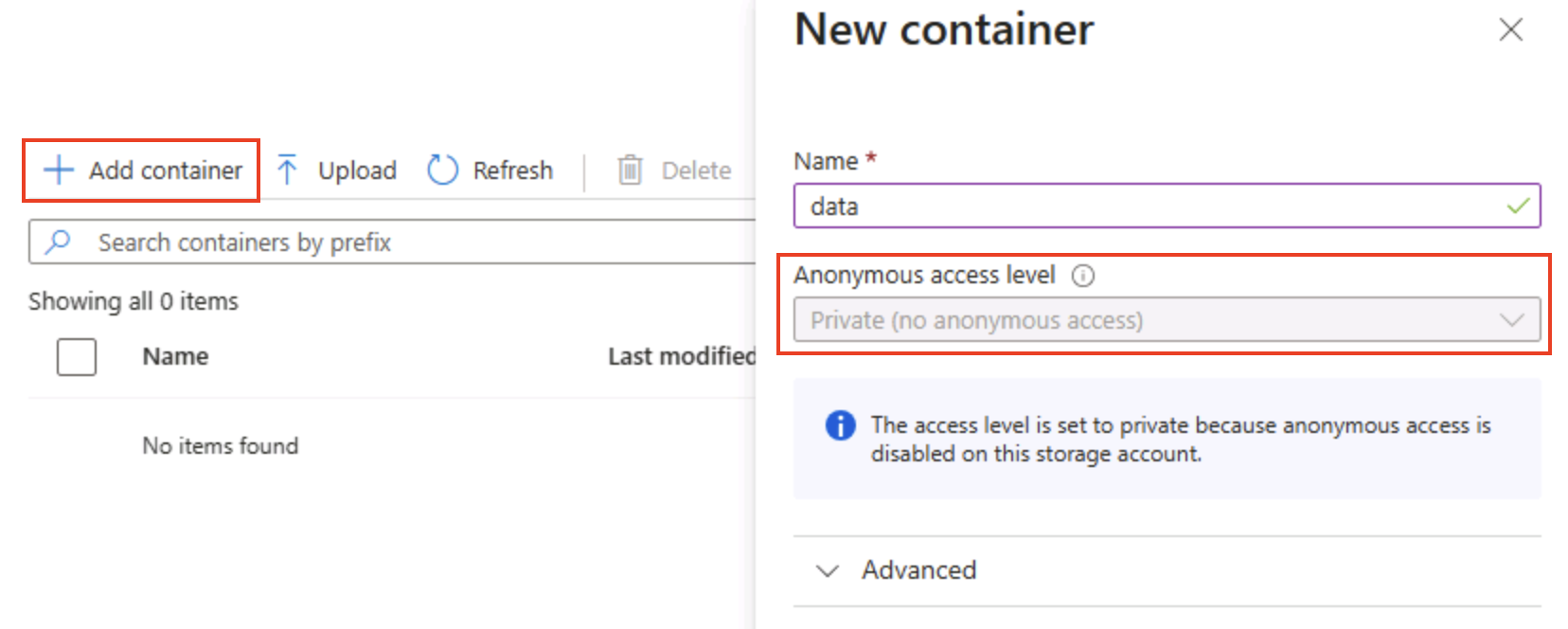
Tipp: Bei privatem Zugriff bleiben Ihre Beispieldaten sicher. Der öffentliche Zugriff ist nur selten erforderlich, außer bei statischen Website- oder offenen Datenszenarien. Wenn Sie dem Beispiel den Namen
datageben, bleibt es einfach und lesbar. -
Wenn der Container data erstellt wurde, überprüfen Sie, ob er auf der Seite Container aufgeführt ist.
-
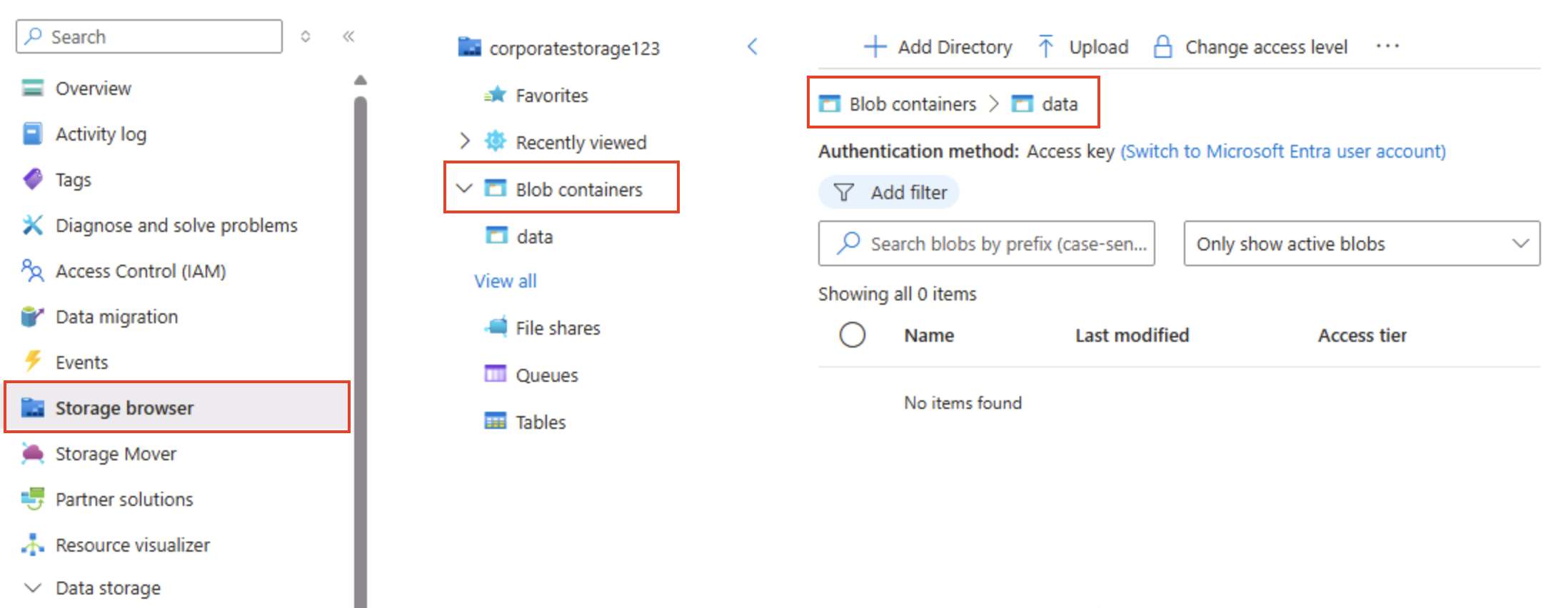
Wählen Sie im Bereich auf der linken Seite im oberen Abschnitt Speicherbrowser aus. Diese Seite enthält eine browserbasierte Benutzeroberfläche, mit der Sie mit den Daten in Ihrem Speicherkonto arbeiten können.
-
Wählen Sie auf der Seite des Speicherbrowsers Blobcontainer aus, und überprüfen Sie, ob Ihr Container data aufgeführt ist.
-
Wählen Sie den Container data aus, und beachten Sie, dass er leer ist.
-
Wählen Sie + Verzeichnis hinzufügen und lesen Sie die Informationen zu Ordnern, bevor Sie einen neuen Ordner mit dem Namen
productserstellen. -
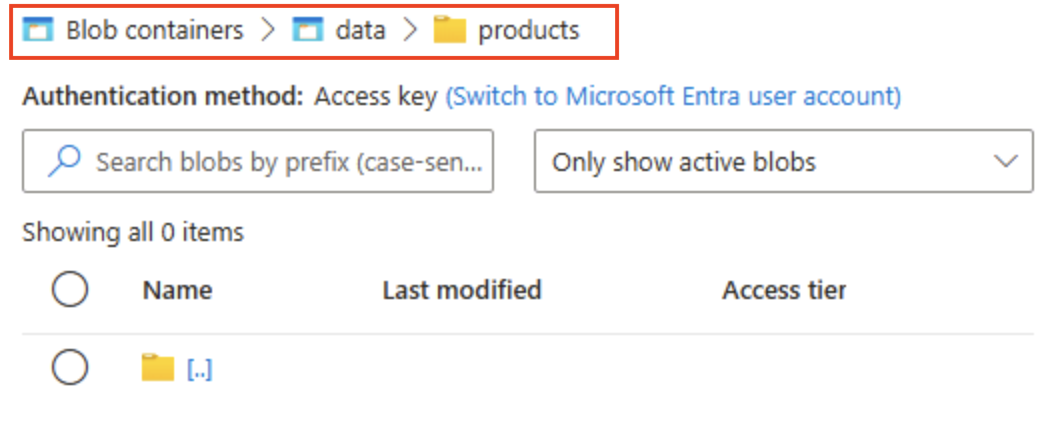
Überprüfen Sie im Speicherbrowser, ob in der aktuellen Ansicht der Inhalt des soeben erstellten Ordners products angezeigt wird. Beachten Sie, dass die „Breadcrumbs“ oben auf der Seite den Pfad Blobcontainer > data > products widerspiegeln.
-
Wählen Sie in den Breadcrumbs Daten aus, um zum Container data zu wechseln, und beachten Sie, dass er keinen Ordner namens products enthält.
Ordner im Blobspeicher sind virtuell und nur als Teil des Pfads eines Blobs vorhanden. Da der Ordner products keine Blobs enthielt, ist er nicht wirklich vorhanden!
Tipp: Der flache Namespace bedeutet, dass Verzeichnisse nur Namenspräfixe (Produkte/file.json) sind. Dieses Design ermöglicht eine massive Skalierung, da der Dienst Blobnamen indiziert, anstatt eine echte Baumstruktur beizubehalten.
-
Verwenden Sie die Schaltfläche ⤒ Hochladen, um den Bereich Blob hochladen zu öffnen.
-
Wählen Sie im Bereich Blob hochladen die Datei product1.json aus, die Sie zuvor auf Ihrem lokalen Computer gespeichert haben. Geben Sie anschließend im Abschnitt Erweitert im Feld In Ordner hochladen den Wert
product_dataein und wählen Sie die Schaltfläche Hochladen.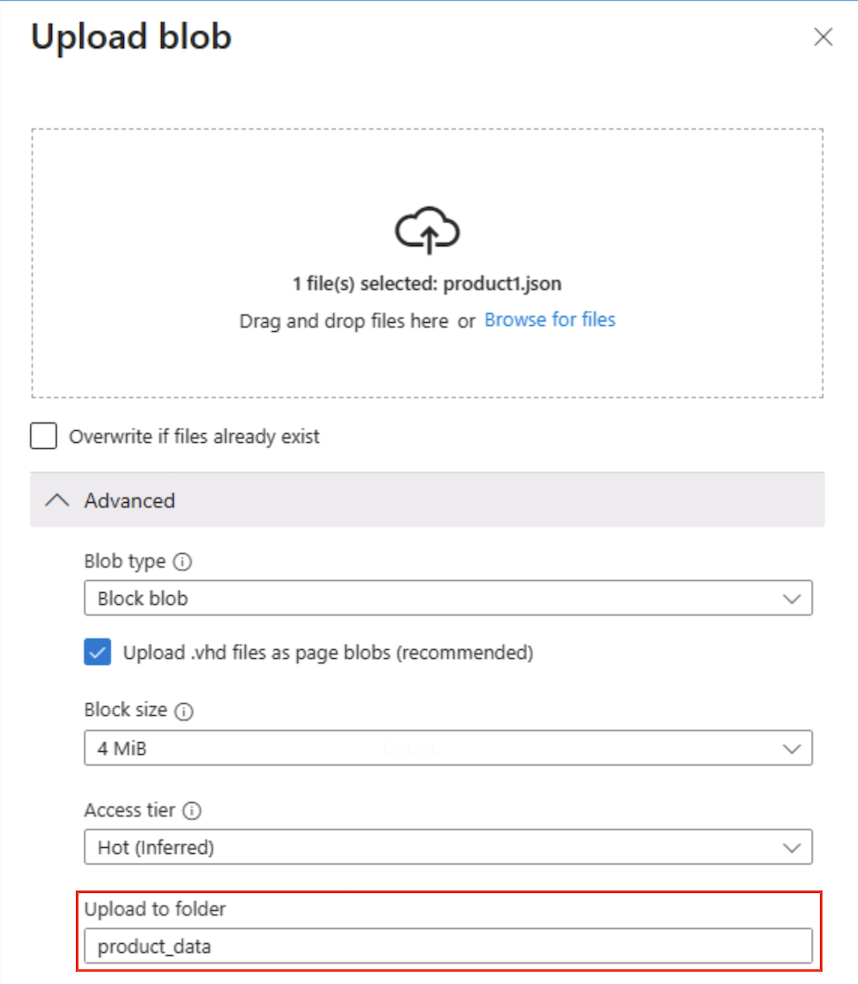
Tipp: Durch das Angeben eines Ordnernamens beim Hochladen wird automatisch der virtuelle Pfad erstellt. Dies zeigt, dass durch das Vorhandensein eines Blobs der „Ordner“ angezeigt wird.
-
Schließen Sie den Bereich Blob hochladen, wenn er noch geöffnet ist, und überprüfen Sie, ob ein virtueller Ordner product_data im Container data erstellt wurde.
-
Wählen Sie den Ordner product_data aus, und vergewissern Sie sich, dass er das hochgeladene Blob product1.json enthält.
-
Wählen Sie auf der linken Seite im Abschnitt Datenspeicher die Option Container aus.
-
Öffnen Sie den Container data, und überprüfen Sie, ob der Ordner product_data aufgeführt ist, den Sie erstellt haben.
-
Wählen Sie das Symbol ‧‧‧ am rechten Ende des Ordners aus, und beachten Sie, dass keine Optionen angezeigt werden. Ordner in einem flachen Namespaceblobcontainer sind virtuell und können nicht verwaltet werden.
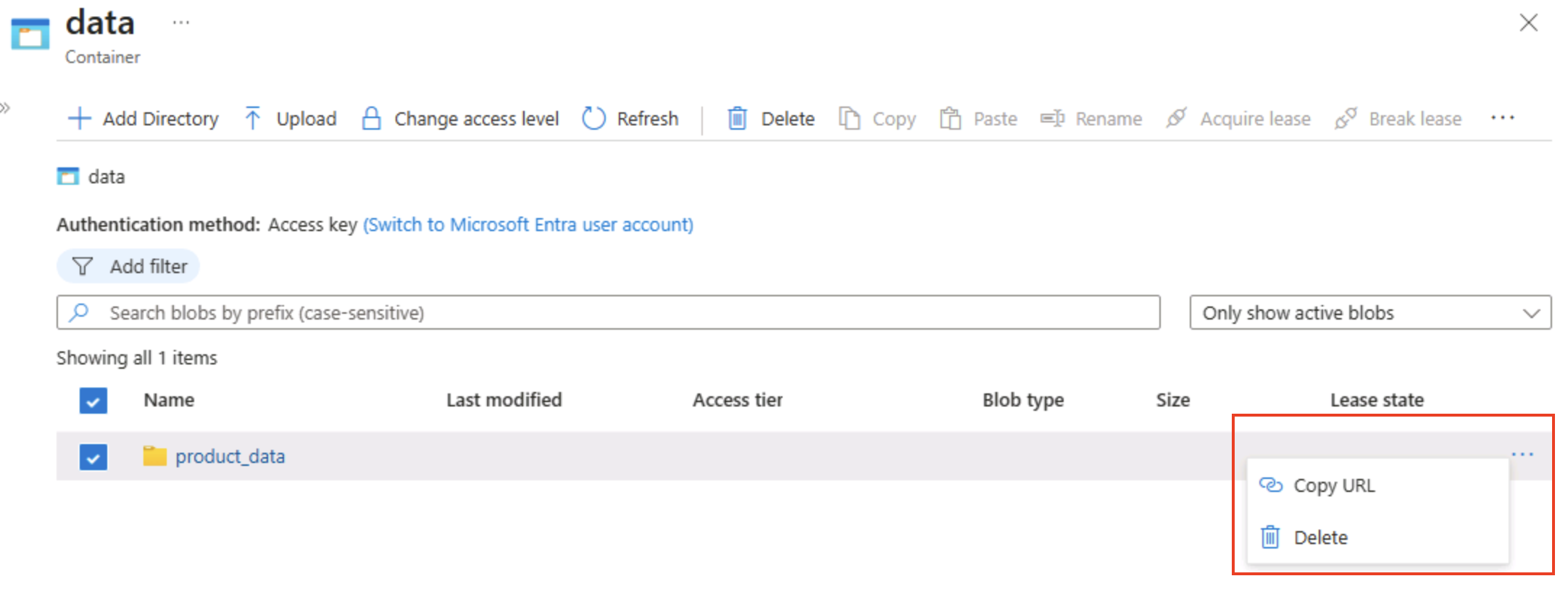
Tipp: Es ist kein echtes Verzeichnisobjekt vorhanden, daher gibt es keine Umbenennungs-/Berechtigungsvorgänge – diese erfordern einen hierarchischen Namespace.
-
Verwenden Sie das Symbol X oben rechts auf der Seite data, um die Seite zu schließen und zur Seite Container zurückzukehren.
Erkunden von Azure Data Lake Storage Gen2
Mit der Azure Data Lake Store Gen2-Unterstützung können Sie hierarchische Ordner verwenden, um den Zugriff auf Blobs zu organisieren und zu verwalten. Außerdem können Sie mit Azure Blob Storage verteilte Dateisysteme für gängige Big Data-Analyseplattformen hosten.
Tipp: Wenn Sie den hierarchischen Namespace aktivieren, verhalten sich Ordner wie echte Verzeichnisse. Außerdem können Sie Ordneraktionen sicher (alle gleichzeitig, ohne Fehler) ausführen und Steuerelemente für Dateiberechtigungen wie in Linux verwenden. Dies ist besonders beim Arbeiten mit Big Data-Tools wie Spark oder Hadoop hilfreich oder beim Verwalten großer, organisierter Data Lakes.
-
Laden Sie die JSON-Datei product2.json von
https://aka.ms/product2.jsonherunter und speichern Sie sie auf Ihrem Computer in demselben Ordner, in dem Sie zuvor product1.json heruntergeladen haben. Sie laden sie später in Blob Storage hoch. -
Scrollen Sie im Azure-Portal auf der Seite Ihres Speicherkontos links nach unten zum Abschnitt Einstellungen, und wählen Sie Data Lake Gen2-Upgrade aus.
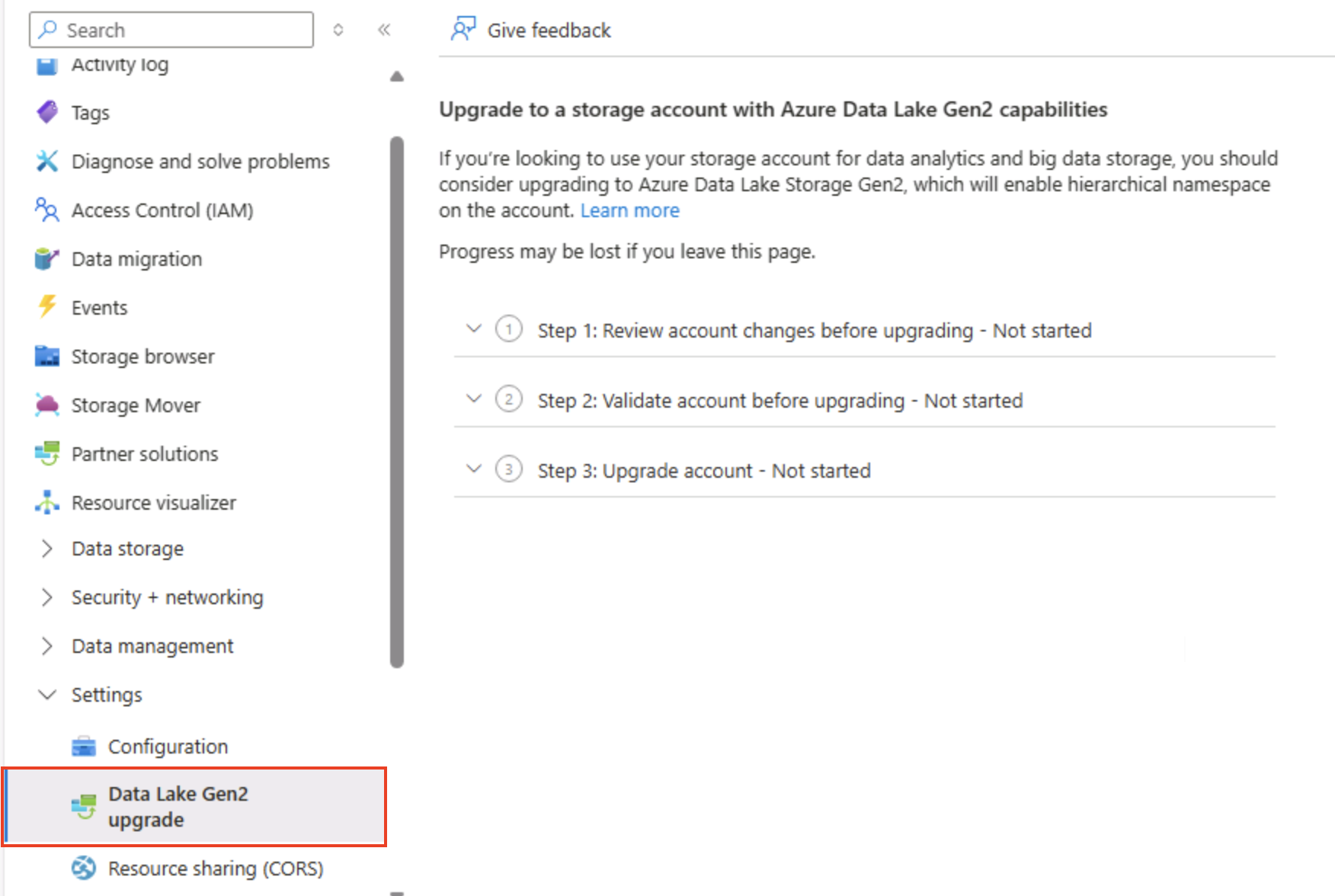
-
Erweitern Sie die einzelnen Schritte auf der Seite Data Lake Gen2-Upgrade, und führen Sie sie aus, um ein Upgrade Ihres Speicherkontos durchzuführen. So aktivieren Sie den hierarchischen Namespace und unterstützen Azure Data Lake Storage Gen 2. Dieser Vorgang kann einige Zeit dauern.
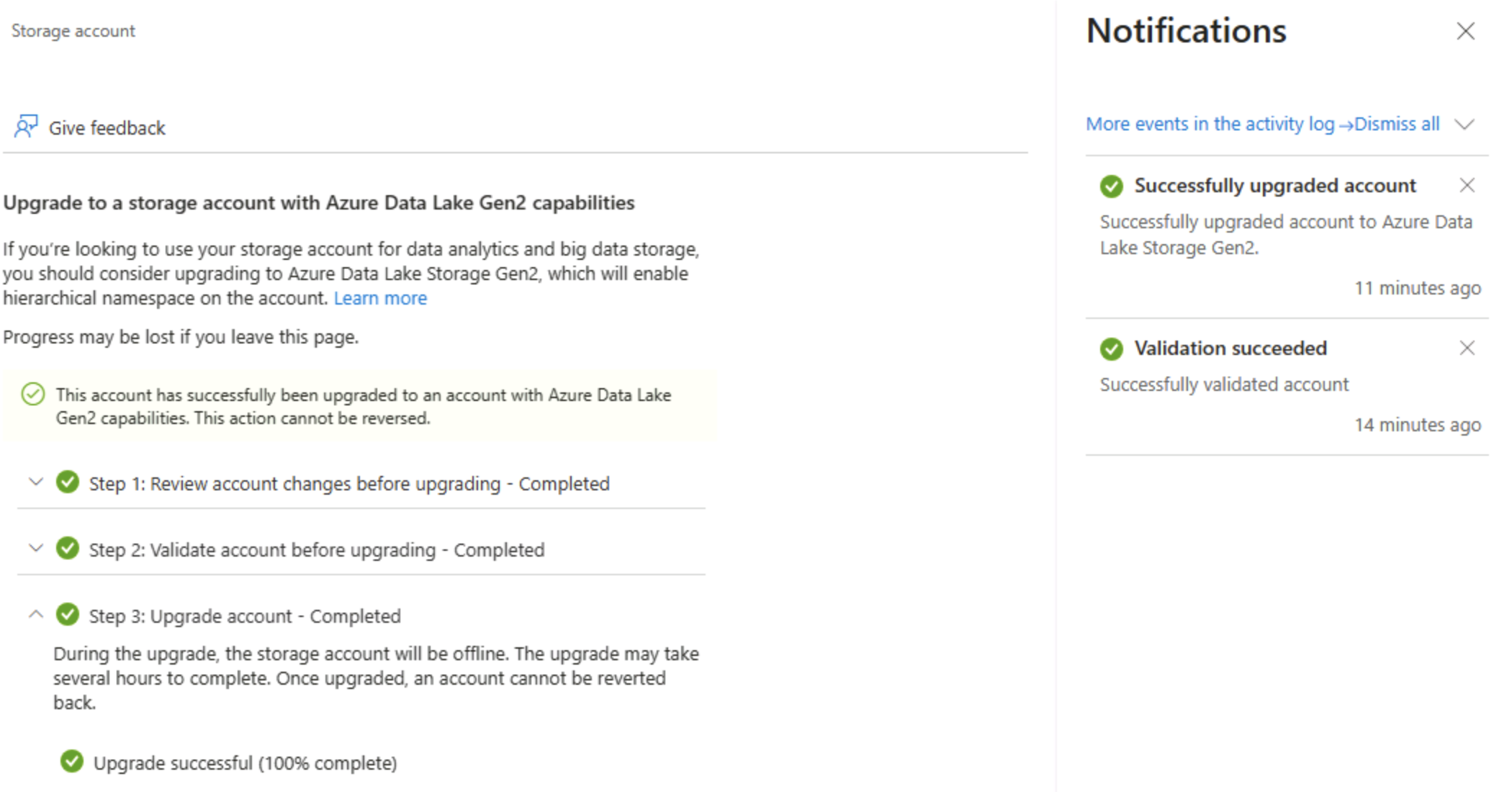
Tipp: Das Upgrade ist ein Funktionswechsel auf Kontoebene – Daten bleiben bestehen, doch die Verzeichnissemantik wird geändert, um erweiterte Vorgänge zu unterstützen.
-
Wenn das Upgrade abgeschlossen ist, wählen Sie im Bereich auf der linken Seite im oberen Abschnitt Speicherbrowser aus, und navigieren Sie zurück zum Stamm Ihres Blobcontainers data, der weiterhin den Ordner product_data enthält.
-
Wählen Sie den Ordner product_data aus, und vergewissern Sie sich, dass er noch die Datei product1.json enthält, die Sie zuvor hochgeladen haben.
-
Verwenden Sie die Schaltfläche ⤒ Hochladen, um den Bereich Blob hochladen zu öffnen.
-
Wählen Sie im Bereich Blob hochladen die Datei product2.json aus, die Sie auf Ihrem lokalen Computer gespeichert haben. Wählen Sie dann die Schaltfläche Hochladen aus.
-
Schließen Sie den Bereich Blob hochladen, wenn er noch geöffnet ist, und überprüfen Sie, ob ein Ordner product_data jetzt die Datei product2.json enthält.
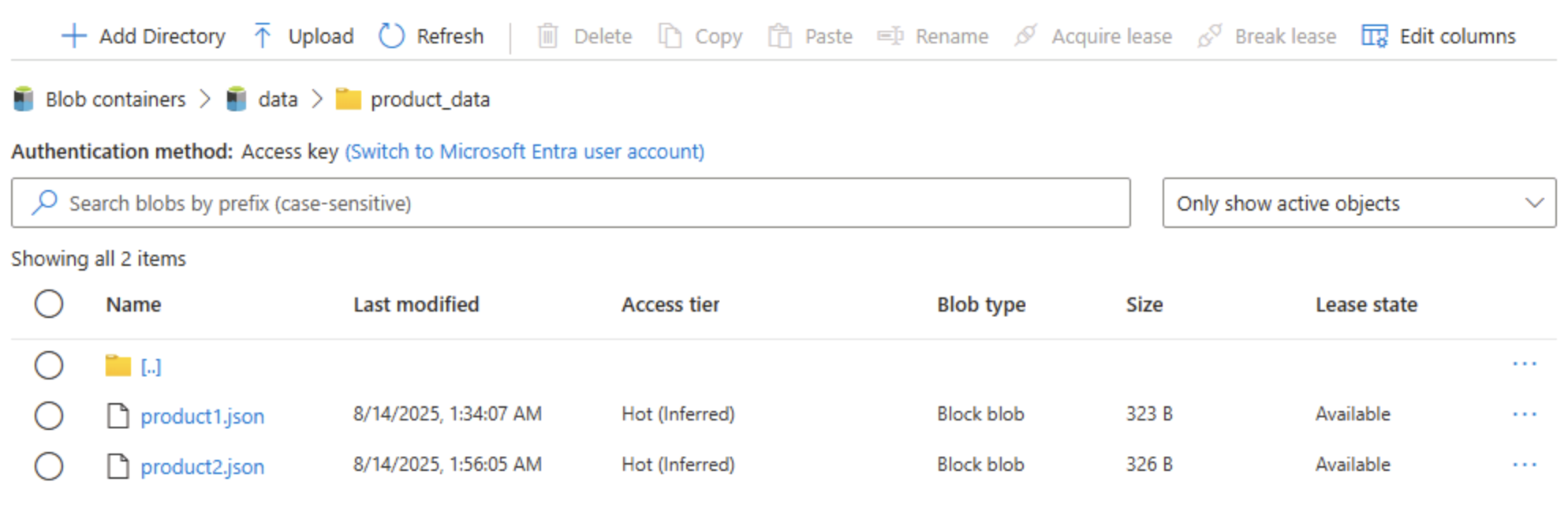
Tipp: Das Hinzufügen einer zweiten Datei nach dem Upgrade bestätigt die nahtlose Kontinuität: Vorhandene Blobs funktionieren weiterhin, und neue profitieren von hierarchischen Vorteilen wie Verzeichnis-ACLs (Zugriffssteuerungslisten).
-
Wählen Sie auf der linken Seite im Abschnitt Datenspeicher die Option Container aus.
-
Öffnen Sie den Container data, und überprüfen Sie, ob der Ordner product_data aufgeführt ist, den Sie erstellt haben.
-
Wählen Sie das Symbol ‧‧‧ am rechten Ende des Ordners aus, und beachten Sie, dass Sie Konfigurationsaufgaben wie das Umbenennen von Ordnern und das Festlegen von Berechtigungen auf Ordnerebene ausführen können, wenn der hierarchische Namespace aktiviert ist.
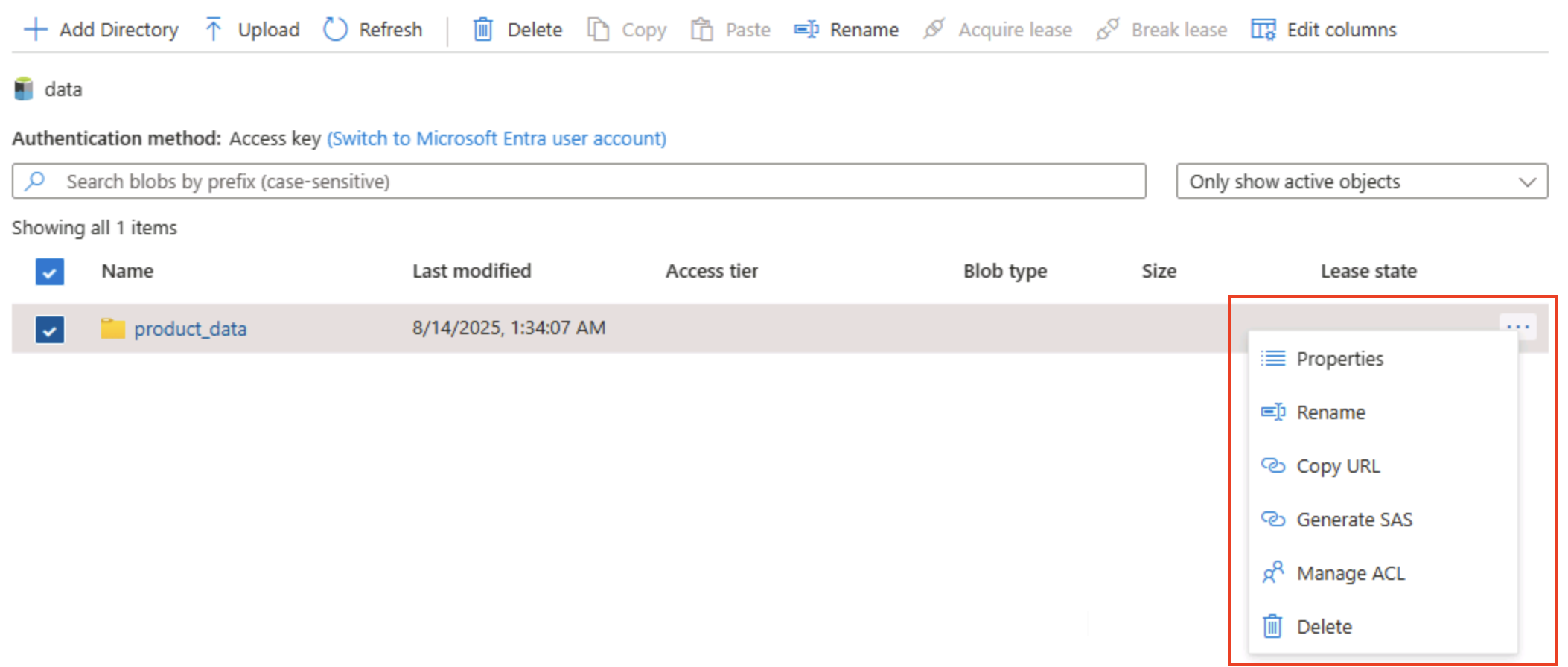
Tipp: Echte Ordner ermöglichen es, Sicherheitsrichtlinien nach dem Least-Privilege-Prinzip auf Ordnerebene anzuwenden. Sie sorgen für sicheres Umbenennen und beschleunigen rekursive Auflistungen im Vergleich zum Scannen von Tausenden von Blobnamen mit Präfixen.
-
Verwenden Sie das Symbol X oben rechts auf der Seite data, um die Seite zu schließen und zur Seite Container zurückzukehren.
Erkunden von Azure Files
Azure Files bietet eine Möglichkeit, cloudbasierte Dateifreigaben zu erstellen.
Tipp: Azure Files bietet SMB/NFS-Endpunkte für Lift-and-Shift-Szenarien, in denen Apps ein herkömmliches Dateisystem erwarten. Es ergänzt (nicht ersetzt) Blobspeicher, indem Dateisperren und betriebssystemeigene Tools unterstützt werden.
-
Wählen Sie auf der Azure-Portalseite für Ihren Speichercontainer auf der linken Seite im Abschnitt Datenspeicher die Option Dateifreigaben aus.

-
Wählen Sie auf der Seite „Dateifreigaben“ die Option + Dateifreigabe aus und fügen Sie eine neue Dateifreigabe mit dem Namen
filesunter Verwendung der Stufe Transaktionsoptimiert hinzu. -
Wählen Sie Weiter: Backup > und deaktivieren Sie das Backup. Wählen Sie dann Überprüfen + erstellen aus.
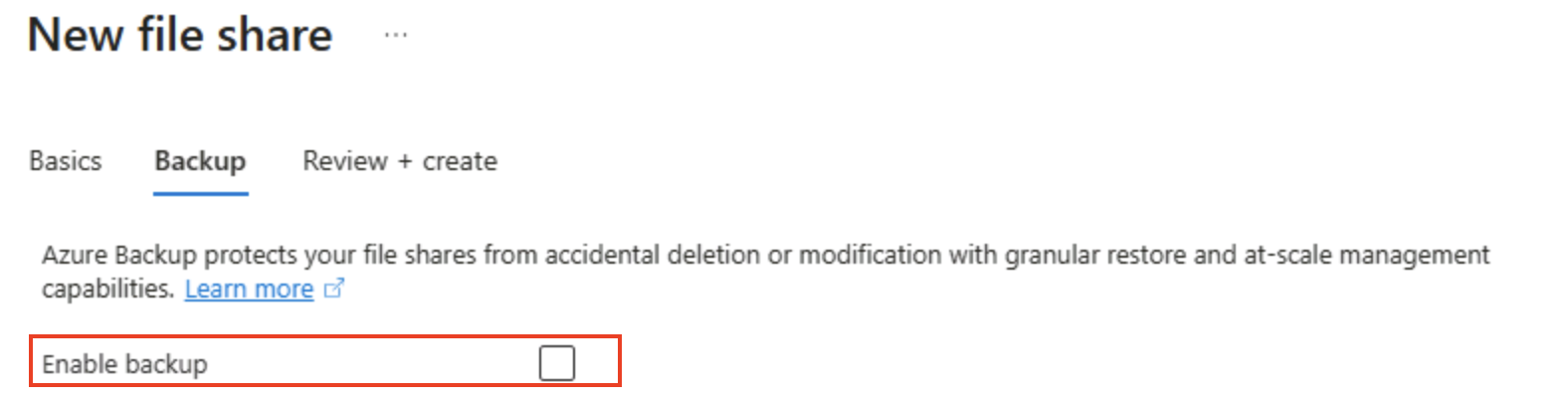
Tipp: Durch das Deaktivieren der Sicherung bleiben die Kosten für kurz genutzte Übungsumgebung gering. Sie würden diese Option für die Ausfallsicherheit in der Produktionsumgebung aktivieren.
-
Öffnen Sie ihre neue Freigabe files in den Dateifreigaben.
-
Wählen Sie oben auf der Seite Verbinden aus. Beachten Sie dann, dass der Bereich Verbinden Registerkarten für gängige Betriebssysteme (Windows, Linux und macOS) enthält, die Skripts enthalten, die Sie ausführen können, um von einem Clientcomputer aus eine Verbindung mit dem freigegebenen Ordner herzustellen.
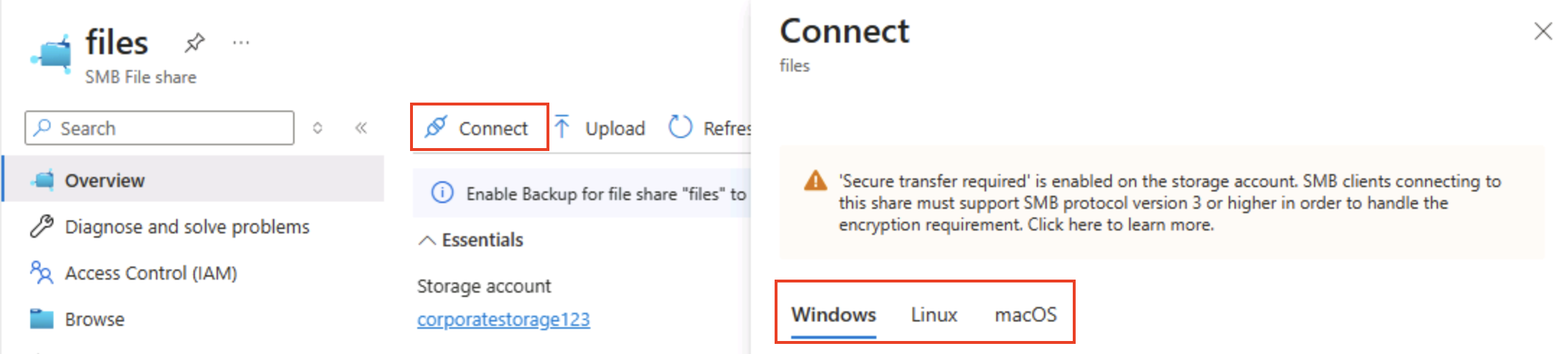
Tipp: Die generierten Skripts zeigen genau, wie Sie die Freigabe mithilfe von plattformeigenen Befehlen einbinden und veranschaulichen so Hybridzugriffsmuster von virtuellen Computern, Containern oder lokalen Servern.
-
Schließen Sie den Bereich Verbinden und dann die Seite files, um zur Seite Dateifreigaben für Ihr Azure-Speicherkonto zurückzukehren.
Erkunden von Azure Tables
Azure Tables bietet einen Schlüssel-Wert-Speicher für Anwendungen, die Datenwerte speichern müssen, aber nicht die vollständige Funktionalität und Struktur einer relationalen Datenbank benötigen.
Tipp: Bei Tabellenspeichern handelt es sich um umfangreiche Abfragen und Verknüpfungen zu extrem niedrigen Kosten, für schemalose Flexibilität und für horizontale Skalierung – ideal für Protokolle, IoT-Daten oder Benutzerprofile.
-
Wählen Sie auf der Azure-Portalseite für Ihren Speichercontainer auf der linken Seite im Abschnitt Datenspeicher die Option Tabellen aus.
-
Wählen Sie auf der Seite Tabellen die Option + Tabelle und erstellen Sie eine neue Tabelle mit dem Namen
products. -
Nachdem die Tabelle products erstellt wurde, wählen Sie im Bereich auf der linken Seite im oberen Abschnitt Speicherbrowser aus.
-
Wählen Sie im Speicher-Explorer Tabellen aus, und überprüfen Sie, ob die Tabelle products aufgeführt ist.
-
Wählen Sie die Tabelle products aus.
-
Wählen Sie auf der Seite product die Option + Entität hinzufügen aus.
- Geben Sie im Bereich Entität hinzufügen die folgenden Schlüsselwerte ein:
- PartitionKey: 1
- RowKey: 1
Tipp: PartitionKey gruppiert verwandte Entitäten zum Verteilen der Last; RowKey identifiziert eindeutig innerhalb der Partition. Zusammen bilden sie einen schnellen zusammengesetzten Primärschlüssel für Nachschlagevorgänge.
-
Wählen Sie Eigenschaft hinzufügen aus, und erstellen Sie zwei neue Eigenschaften mit den folgenden Werten:
Eigenschaftenname type Wert Name String Widget Preis Double 2,99 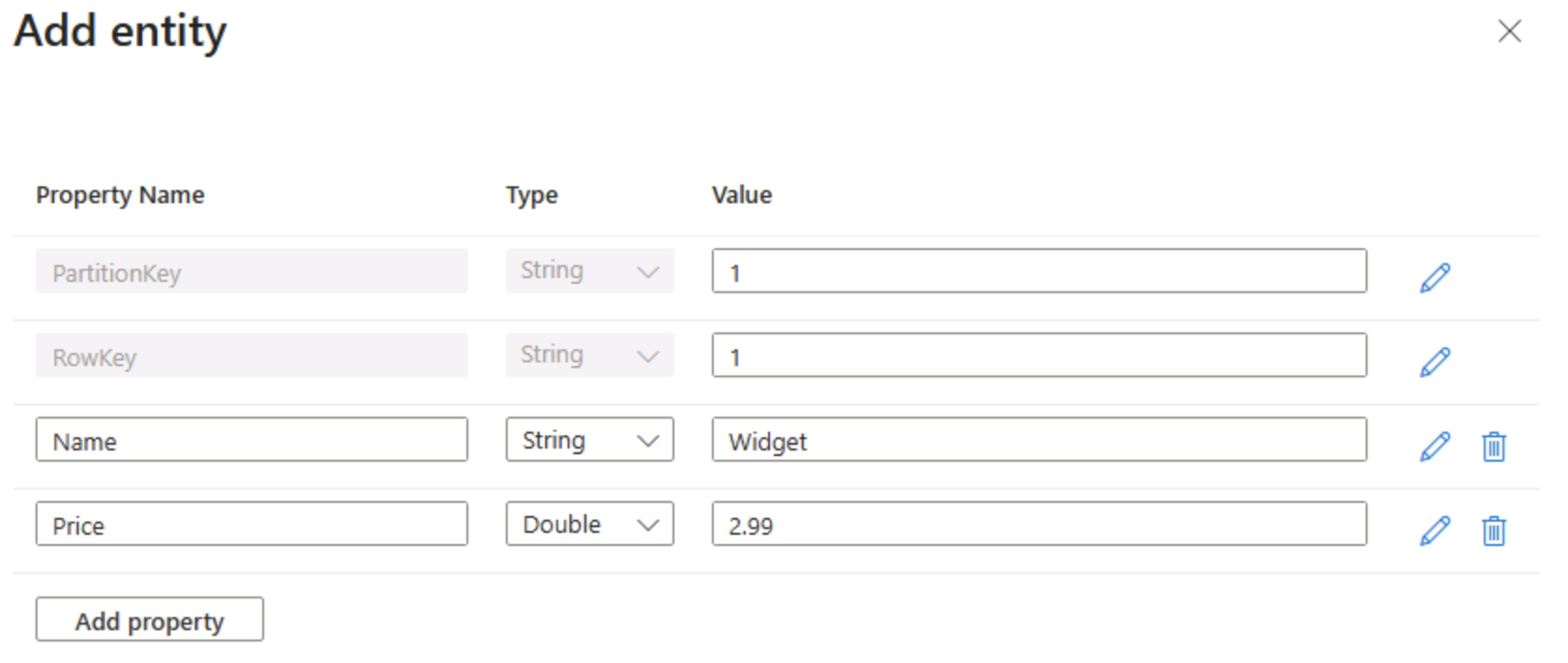
-
Wählen Sie Einfügen aus, um eine Zeile für die neue Entität in die Tabelle einzufügen.
-
Überprüfen Sie im Speicherbrowser, ob der Tabelle products eine Zeile hinzugefügt wurde, und ob eine Spalte Zeitstempel erstellt wurde, um anzugeben, wann die Zeile zuletzt geändert wurde.
-
Fügen Sie der Tabelle products eine weitere Entität mit den folgenden Eigenschaften hinzu:
Eigenschaftenname type Wert PartitionKey String 1 RowKey String 2 Name String Kniknak Preis Double 1.99 Eingestellt Boolean true Tipp: Das Hinzufügen einer zweiten Entität mit unterschiedlichen Schlüsseln und eine zusätzliche boolesche Eigenschaft veranschaulicht die Flexibilität beim Schreiben von Schemas – neue Attribute erfordern keine Migration.
-
Überprüfen Sie nach dem Einfügen der neuen Entität, ob eine Zeile mit dem eingestellten Produkt in der Tabelle angezeigt wird.
Sie haben über die Benutzeroberfläche des Speicherbrowsers manuell Daten in die Tabelle eingegeben. In einem realen Szenario können Anwendungsentwickler die Azure Storage-Tabellen-API verwenden, um Anwendungen zu erstellen, die Werte aus Tabellen lesen und dort hineinschreiben, sodass sie kostengünstige und skalierbare Lösung für NoSQL-Speicher sind.
Tipp: Wenn Sie die Erkundung von Azure Storage abgeschlossen haben, können Sie die in dieser Übung erstellte Ressourcengruppe löschen. Das Löschen der Ressourcengruppe ist die einfachste Möglichkeit, fortlaufende Gebühren zu vermeiden. Entfernen Sie dazu jede Ressource, die Sie in einer Aktion erstellt haben.