Azure Machine Learning デザイナーを使用してクラスタリングを調べる
注 このラボを完了するには、管理者アクセス権が与えられている Azure サブスクリプションが必要です。
Azure Machine Learning ワークスペースを作成する
-
Microsoft 資格情報を使用して、Azure portal にサインインします。
- [リソースの作成] を選択して Machine Learning を検索し、Azure Machine Learning プランを使用して新しい Azure Machine Learning リソースを作成します。 次の設定を使用します。
- [サブスクリプション]: お使いの Azure サブスクリプション。
- リソース グループ: リソース グループを作成または選択します。
- ワークスペース名: ワークスペースの一意の名前を入力します。
- リージョン: 地理的に最も近いリージョンを選びます
- ストレージ アカウント: ワークスペース用に作成される既定の新しいストレージ アカウントです。
- キー コンテナー: ワークスペース用に作成される既定の新しいキー コンテナーです。
- Application Insights: ワークスペース用に作成される既定の新しい Application Insights リソースです。
- [コンテナー レジストリ]: なし (コンテナーにモデルを初めてデプロイするときに、自動的に作成されます)
-
Review + create を選択し、次に [作成] を選択します。 ワークスペースが作成されるまで待ってから (数分かかる場合があります)、デプロイされたリソースに移動します。
-
[スタジオを起動する] を選択し (または新しいブラウザー タブを開いて https://ml.azure.com に移動し)、Microsoft アカウントを使って Azure Machine Learning スタジオにサインインします。
- Azure Machine Learning スタジオに、新しく作成したワークスペースが表示されます。 そうでない場合は、左側のメニューで自分の Azure ディレクトリを選択します。 次に、新しい左側のメニューから [ワークスペース] を選択します。そこに、ディレクトリに関連付けられているすべてのワークスペースが一覧表示されます。この演習用に作成したものを選択します。
注 このモジュールは、Azure Machine Learning ワークスペースを使用する多くのものの 1 つであり、「Microsoft Azure AI Fundamentals: 機械学習用のビジュアル ツールについて調べる」ラーニング パスの他のモジュールも含まれます。 独自の Azure サブスクリプションを使用している場合は、ワークスペースを 1 回作成し、それを他のモジュールで再利用することを検討できます。 ご利用のサブスクリプションに Azure Machine Learning ワークスペースが存在する限り、Azure サブスクリプションはデータ ストレージに対して少額を課金します。そのため、Azure Machine Learning ワークスペースが不要になった場合は、削除することをお勧めします。
コンピューティングを作成する
-
Azure Machine Learning スタジオで左上にある ≡ アイコン (3 つの行が積み重なったようなメニュー アイコン) を選択して、インターフェイスのさまざまなページを表示します (画面のサイズを最大化する必要がある場合があります)。 左側のペインでこれらのページを使って、ワークスペース内のリソースを管理できます。 [コンピューティング] ページ ( [管理] の下) を表示します。
-
[コンピューティング] ページで [コンピューティング クラスター] タブを選び、次の設定で新しいコンピューティング クラスターを追加します。 これを使用して機械学習モデルをトレーニングします。
- 場所: “ワークスペースと同じものを選択してください。場所が一覧にない場合は、最も近いものを選択してください”
- 仮想マシンのレベル: 専用
- [仮想マシンの種類]: CPU
- 仮想マシンのサイズ:
- [すべてのオプションから選択] を選択します
- [Standard_DS11_v2] を検索して選択します
- [次へ] を選択します
- コンピューティング名: 一意の名前を入力します
- [ノードの最小数]: 0
- [ノードの最大数]: 2
- [スケール ダウンする前のアイドル時間 (秒)]:120
- SSH アクセスの有効化: 解除します
- [作成] を選択します。
注 コンピューティング インスタンスとクラスターは、標準の Azure 仮想マシン イメージに基づいています。 このモジュールでは、コストとパフォーマンスの最適なバランスを実現するために Standard_DS11_v2 イメージが推奨されます。 サブスクリプションに、このイメージを含まないクォータが存在する場合は、代替イメージを選択します。ただし、大きなイメージはコストを上昇させる可能性があり、小さなイメージはタスクを完了するには十分でない可能性があることに注意してください。 または、Azure 管理者にクォータを拡張するように依頼します。
コンピューティング クラスターの作成には時間がかかります。 待っている間に次のステップに進んでかまいません。
パイプラインを作成してデータセットを追加する
Azure Machine Learning デザイナーの使用を開始するには、最初にパイプラインを作成する必要があります。
-
Azure Machine Learning スタジオで、画面の左上にある ☰ メニュー アイコンを選択して左側のペインを展開します。 [デザイナー] ページ ( [作成] の下) を表示し、 + を選択して新しいパイプラインを作成します。
-
ドラフトの名前 (Pipeline-Created-on-* date*) を Train Penguin Clustering に変更します。
Azure Machine Learning では、モデルのトレーニングやその他の操作用のデータは通常、”データセット” と呼ばれるオブジェクトにカプセル化されます。 このモジュールでは、ペンギンの 3 つの種の観察が含まれるデータセットを使用します。
-
[データ] ページ ([アセット] の下)を表示します。 [データ] ページには、Azure ML 内で使用する予定の特定のデータ ファイルまたはテーブルが含まれています。
- [データ] ページの [データ資産] タブで、 [作成] を選択します。 次に、次の設定でデータ資産を構成します。
- データ型:
- [名前]: penguin-data
- [説明]: ペンギンのデータ
- データセットの種類:表形式
- データ ソース: Web ファイルから
- Web URL:
- [Web URL]: https://aka.ms/penguin-data
- データ検証のスキップ: “選択しないでください”**
- 設定:
- [ファイル形式]: 区切り記号付き
- [区切り記号]: コンマ
- [エンコード]: UTF-8
- [列ヘッダー]: 最初のファイルにのみヘッダーを付ける
- [行のスキップ]: なし
- データセットに複数行のデータを含める: 選択しない**
- [スキーマ]:
- [パス] 以外のすべての列を含める
- 自動的に検出された型を確認する
- 確認
- [作成] を選択します。
- データ型:
- データセットが作成されたら、それを開き、[探索] ページを表示して、データのサンプルを確認します。 このデータは、ペンギンの複数の観察における、嘴峰 (くちばし) の長さと深さ、翼の長さ、および体重の測定値を表します。 このデータセットでは、 Adelie、Gentoo、Chinstrapの 3 つの種のペンギンを表しています。
注 この演習で使用するペンギンのデータセットは、Dr. Kristen Gorman と、Long Term Ecological Research Network のメンバーである Palmer Station、Antarctica LTER によって収集されて使用可能になっているデータのサブセットです。
データをキャンバスに読み込む
-
左側のメニューで [デザイナー] を選んで、パイプラインに戻ります。 [Designer] ページで、Train Penguin Clustering パイプライン ドラフトを選択します。
-
左側のパイプライン名の横にある矢印アイコンを選択し、パネルを展開します (まだ開いていない場合)。 既定では、パネルで [資産ライブラリ] ペインが開きます。これは、パネルの上部にある本のアイコンで表されます。 アセットを検索するために、検索バーがあります。 [データ] と [コンポーネント] の 2 つのボタンに注目してください。
-
[データ] を選択し、penguin-data データセットを検索し、キャンバス上に配置します。
-
キャンバス上で [penguin-data] データセットを右クリックし (Mac では Ctrl キーを押しながらクリック)、[データのプレビュー] をクリックします。
-
[プロファイル] タブを選択します。さまざまな列の分布がヒストグラムとして表示されることを確認してください。
-
データセットの次の特徴に注意してください。
- データセットには、次の列が含まれています。
- CulmenLength: ペンギンのくちばしの長さ (ミリメートル単位)。
- CulmenDepth: ペンギンのくちばしの深さ (ミリメートル単位)。
- FlipperLength: ペンギンの翼の長さ (ミリメートル単位)。
- BodyMass: ペンギンの体重 (グラム単位)。
- Species: 種インジケーター (0: “Adelie”、1: “Gentoo”、2: “Chinstrap”)
- CulmenLength 列には、2 つの欠損値が含まれます (CulmenDepth、FlipperLength、BodyMass 列にも 2 つの欠損値があります)。
- 測定値はスケールが異なります (数十ミリメートルから数千グラムまで)。
- データセットには、次の列が含まれています。
-
[DataOutput] ページを閉じると、パイプライン キャンバスにデータセットが表示されます。
変換を適用する
-
左側の [アセット ライブラリ] ウィンドウで、 [コンポーネント] を選択します (これには、データ変換とモデル トレーニングに使用できるさまざまなモジュールが含まれています)。 検索バーを使用して、モジュールを簡単に見つけることもできます。
-
ペンギンの観察をクラスター化するには、測定のみを使用するので、種の列を無視します。 そのため、[データセット内の列の選択] モジュールを検索し、次のように、キャンバスの penguin-data モジュールの下に配置して、penguin-data モジュールの下部にある出力を [データセット内の列の選択] モジュールの上部にある入力に接続します。
![[Select Columns in Dataset] (データセット内の列の選択) モジュールに接続されている penguin-data データセットのスクリーンショット。](/AI-900-AIFundamentals.ja-JP/instructions/media/create-clustering-model/dataset-select-columns.png)
-
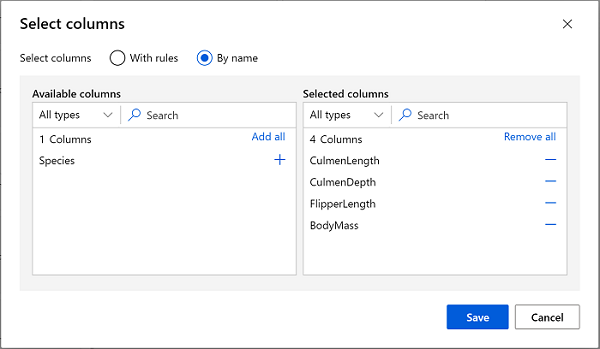
[データセット内の列の選択] モジュールをダブルクリックし、右側のペインで [列の編集] を選びます。 次に、[列の選択] ウィンドウで By name を選択し、次のように、[+] リンクを使用して、列名 CulmenLength、CulmenDepth、FlipperLength、BodyMass を選択します。
-
[保存] を選択し、 Select Columns in Dataset メニューを閉じて、デザイナー キャンバスに戻ります。
-
[アセット ライブラリ] で Clean Missing Data モジュールを検索し、次のように、キャンバスの [データセット内の列の選択] モジュールの下に配置して、それらを接続します。
![[Select Columns in Dataset] (データセット内の列の選択) モジュールを、[Clean Missing Data] (欠損データのクリーニング) モジュールに接続する方法のスクリーンショット。](/AI-900-AIFundamentals.ja-JP/instructions/media/create-clustering-model/clean-missing-data.png)
-
Clean Missing Data モジュールをダブルクリックし、右側の [設定] ペインで [列の編集] を選択します。 次に、 [クリーンする列] ウィンドウで、次のように [ルールを使用] を選択して [すべての列] を含めます。
![[With rules] (ルールを使用) オプションを使用してすべての列を選択する方法のスクリーンショット。](/AI-900-AIFundamentals.ja-JP/instructions/media/create-clustering-model/normalize-columns.png)
- [保存] を選択し、設定ウィンドウで次の構成設定を設定します。
- [欠損値の最小比率]:0.0
- [欠損値の最大比率]: 1.0
- [クリーニング モード]: 行全体の削除
-
[アセット ライブラリ] で [データの正規化] モジュールを見つけて、キャンバスの [欠損データのクリーニング] モジュールの下に配置します。 次に、Clean Missing Data モジュールからの一番左の出力を、Normalize Data モジュールの入力に接続します。
![[Clean Missing Data] (欠損データのクリーニング) モジュールが [Normalize Data] (データの正規化) モジュールに接続されているスクリーンショット。](/AI-900-AIFundamentals.ja-JP/instructions/media/create-clustering-model/dataset-normalize.png)
-
[データの正規化] モジュールをダブルクリックし、右側のペインで [変換メソッド] を [MinMax] に設定して、[列の編集] を選びます。 次に、 [変換する列] ウィンドウで、次のように [ルールを使用] を選択して [すべての列] を含めます。
- [保存] を選択し、 Normalize Data モジュールの設定を閉じて、デザイナー キャンバスに戻ります。
パイプラインを実行する
データ変換を適用するには、パイプラインを実験として実行する必要があります。
-
ページの上部にある [構成と送信] を選択して、 [パイプライン ジョブのセットアップ] ダイアログを開きます。
-
[基本] ページで [新規作成] を選択し、実験の名前を mslearn-penguin-training に設定し、 [次へ] を選択します。
-
[入力と出力] ページで、変更を加えずに [次へ] を選択します。
-
パイプラインを実行する既定のコンピューティングがないため、 [ランタイム設定] ページにエラーが表示されます。 [コンピューティングの種類の選択] ドロップダウンで [コンピューティング クラスター] を選択し、 [Azure ML コンピューティング クラスターの選択] ドロップダウンで、最近作成したコンピューティング クラスターを選択します。
-
[次へ] を選択してパイプライン ジョブを確認し、 [送信] を選択してトレーニング パイプラインを実行します。
-
実行が終了するまで待ちます。 これには、5 分以上かかることがあります。 [資産] の下にある [ジョブ] を選択して、ジョブの状態を確認できます。 そこから、Train Penguin Clustering ジョブを選択します。
変換されたデータを表示する
-
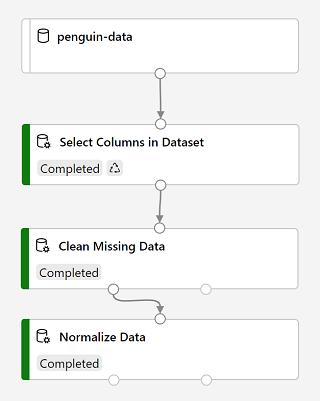
実行が完了すると、モジュールは次のようになります。
-
Normalize Data モジュールを右クリックして [データを表示する] を選択し、次に Transformed dataset を選択して結果を表示します。
-
データを表示します。Species 列が削除されていること、欠損値がないこと、4 つの特徴すべての値が共通のスケールに正規化されていることに注意してください。
-
[Transformed_dataset] ページを閉じて、パイプラインの実行に戻ります。
データセットから使用する特徴を選択して準備したので、それらを使用してクラスタリング モデルをトレーニングできる状態になりました。
データ変換を使用してデータを準備したら、それを使用して機械学習モデルをトレーニングできます。
トレーニング モジュールを追加する
次に示すように、以下の手順を実行して Train Penguin Clustering パイプラインを拡張します。
![K-Means Clustering アルゴリズム コンポーネントと [Assign Data to Modules] (モジュールにデータを割り当てる) コンポーネントのスクリーンショット。](/AI-900-AIFundamentals.ja-JP/instructions/media/create-clustering-model/k-means.png)
次の手順に従います。必要なモジュールを追加して構成するときに、上記の参照用イメージを使用します。
-
[Designer] ページに戻り、Train Penguin Clustering パイプライン ドラフトを開きます。
-
左側の [アセット ライブラリ] ペインで、 [データの分割] モジュールを見つけてキャンバスの [データの正規化] モジュールの下に配置します。 次に、Normalize Data モジュールの左側の出力を、Split Data モジュールの入力に接続します。
ヒント モジュールを簡単に見つけるには、検索バーを使います。
- Split Data モジュールを選択し、その設定を次のように構成します。
- Splitting mode: Split Rows (行を分割)
- 最初の出力データセット内の行の割合:0.7
- ランダム化分割: True
- [ランダム シード]: 123
- Stratified split: False
-
[アセット ライブラリ] で、[クラスタリング モデルのトレーニング] モジュールを検索し、キャンバスの [データの分割] モジュールの下に配置します。 次に、 [データの分割] モジュールの “結果データセット 1” (左側) の出力を [クラスタリング モデルのトレーニング] モジュールの “データセット” (右側) の入力に接続します。
-
クラスタリング モデルでは、元のデータセットから選択したすべての特徴を使用して、データ項目にクラスターを割り当てる必要があります。 [クラスタリング モデルのトレーニング] モジュールをダブルクリックし、右側のペインで [列の編集] を選択します。 [ルールを使用] オプションを使用し、次のようにすべての列を含めます。
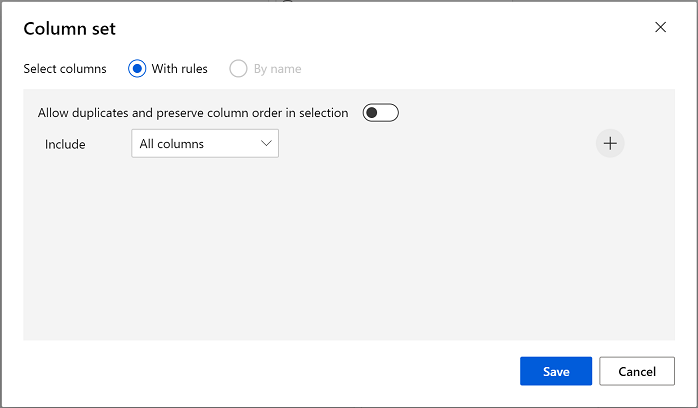
-
トレーニング中のモデルは、特徴を使用してデータをクラスターにグループ化します。そのため、”クラスタリング” アルゴリズムを使用してモデルをトレーニングする必要があります。 [アセット ライブラリ] で K-Means Clustering モジュールを見つけて、キャンバス上で Split data モジュールの左側、 Train Clustering Model モジュールの上に配置します。 次に、その出力を、Train Clustering Model モジュールの Untrained model (左側) の入力に接続します。
-
K-Means アルゴリズムでは、指定した数 (K で示される値) のクラスターに項目がグループ化されます。[K-Means クラスタリング] モジュールを選択し、右側のペインので、[重心の数] パラメーターを 3 に設定します。
注 ペンギンの測定値のようなデータの観察は、多次元ベクトルと考えることができます。 K-Means アルゴリズムは次のように機能します。
- n 次元空間内の “重心” と呼ばれるランダムに選択されたポイントとして K 座標を初期化します (n は特徴ベクトル内のディメンションの数です)。
- 特徴ベクトルを同じ空間内の点としてプロットし、各ポイントを最も近い重心に割り当てます。
- 重心をそれに割り当てられたポイントの中央に移動します (“平均” 距離に基づいて)。
- 移動後に、ポイントを最も近い重心に再度割り当てます。
- クラスターの割り当てが安定するか 指定された回数の反復が 完了するまで、ステップ c と d を繰り返します。
データの 70% を使用してクラスタリング モデルをトレーニングした後、モデルを使用して残りの 30% のデータをクラスターに割り当てることにより、それをテストすることができます。
- [アセット ライブラリ] で、[クラスターへのデータの割り当て] モジュールを見つけ、キャンバスの [クラスター モデルのトレーニング] モジュールの下に配置します。 次に、Train Clustering Model モジュールのトレーニング済みモデル (左側) の出力を Assign Data to Clusters モジュールのトレーニング済みモデル (左側) の入力に接続し、Split Data モジュールの結果データセット 2 (右側) の出力を Assign Data to Clusters モジュールのデータセット (右側) の入力に接続します。
トレーニング パイプラインを実行する
これで、トレーニング パイプラインを実行してモデルをトレーニングする準備ができました。
-
パイプラインが次のようになっていることを確認します。
-
[構成と送信] を選択し、コンピューティング クラスター上で mslearn-penguin-training という名前の既存の実験を使用してパイプラインを実行します。
-
実行が終了するまで待ちます。 これには、5 分以上かかることがあります。 [資産] の下にある [ジョブ] を選択して、ジョブの状態を確認します。 そこから、最新の Train Penguin Clustering ジョブを選択します。
-
実験の実行が完了したら、 Assign Data to Clusters モジュールを右クリックし、 [データを表示する] を選択し、 Results dataset を選択して結果を表示します。
-
下にスクロールして、各行が割り当てられているクラスター (0、1、または 2) が含まれる [割り当て] 列を確認します。 また、この行を表すポイントから各クラスターの中心までの距離を示す新しい列もあります。ポイントから最も近いクラスターが、それが割り当てられているものです。
-
Results_dataset の視覚化を閉じて、パイプラインの実行に戻ります。
モデルではペンギンの観察に対するクラスターが予測されますが、その予測の信頼性はどの程度でしょうか。 これを評価するには、モデルを評価する必要があります。
クラスタリング モデルの評価は、クラスターの割り当てに対して事前にわかっている true の値がないという事実により困難になります。 適切なクラスタリング モデルは、各クラスター内の項目間の分離レベルが良好なモデルであり、その分離の測定に役立つメトリックが必要です。
Evaluate Mode モジュールを追加する
-
[Designer] ページで、Train Penguin Clustering パイプライン ドラフトを開きます。
-
[アセット ライブラリ] で、キャンバスの [クラスターへのデータの割り当て] モジュールを見つけ、キャンバスの [モデルの評価] モジュールの下に配置します。 [クラスターへのデータの割り当て] モジュールの出力を、[モデルの評価] モジュールの [スコア付けされたデータセット] (左) 入力に接続します。
-
パイプラインが次のようになっていることを確認します。
![[Assign Data to Clusters] (クラスターへのデータの割り当て) モジュールに [Evaluate Model] (モデル評価) モジュールを追加する方法のスクリーンショット。](/AI-900-AIFundamentals.ja-JP/instructions/media/create-clustering-model/evaluate-cluster.png)
-
[構成と送信] を選択し、コンピューティング クラスター上で mslearn-penguin-training という名前の既存の実験を使用してパイプラインを実行します。
-
実験の実行が完了するまで待ちます。 状態をチェックするには、 [ジョブ] ページに移動し、最新の Train Penguin Clustering ジョブを選択します。
- Evaluate Model モジュールを右クリックし、 [データを表示する] を選択し、 [評価結果] を選択します。 各行のメトリックを確認します。
- Average Distance to Other Center (他の中心への平均距離)
- Average Distance to Cluster Center (クラスターの中心への平均距離)
- Number of Points (ポイント数)
- Maximal Distance to Cluster Center (クラスターの中心までの最大距離)
- [Evaluation_results] タブを閉じます。
これで、動作するクラスタリング モデルが完成したので、それを使用して、”推論パイプライン” のクラスターに新しいデータを割り当てることができます。
クラスタリング モデルをトレーニングするためのパイプラインを作成して実行した後は、”推論パイプライン” を作成できます。 推論パイプラインは、新しいデータの観測値をクラスターに割り当てるためにモデルを使用します。 このモデルは、アプリケーションで使用するために発行できる予測サービスの基礎を形成します。
推論パイプラインを作成する
-
キャンバスの上にあるメニューを見つけて、 Create inference pipeline を選択します。 メニューで [推論パイプラインの作成] を見つけるには、画面を完全に展開し、画面の右上隅にある […] アイコンをクリックしなければならない場合があります。

-
Create inference pipeline ドロップダウン リストで、 Real-time inference pipeline を選択します。 数秒後に、Train Penguin Clustering-real time inference (ペンギン クラスタリングのトレーニング - リアルタイム推論) という名前の新しいバージョンのパイプラインが開きます。
-
新しいパイプラインの名前を Predict Penguin Clusters (ペンギン クラスターを予測する) に変更し、新しいパイプラインを確認します。 トレーニング パイプラインの変換とクラスタリング モデルは、このパイプラインの一部です。 トレーニング済みのモデルは、新しいデータのスコア付けに使用されます。 パイプラインには、結果を返す Web サービス出力も含まれています。
推論パイプラインに対して次の変更を行います。
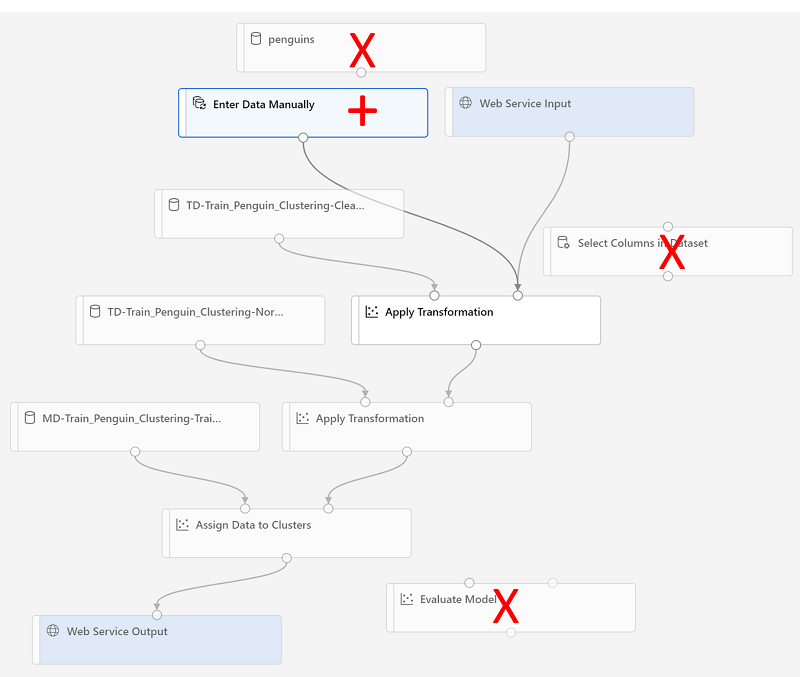
- 新しいデータを送信するための [Web サービス入力] コンポーネントを追加します。
- penguin-data データセットを、Species 列が含まれない [データの手動入力] コンポーネントに置き換えます。
- 冗長になった [データセット内の列の選択] コンポーネントを削除します。
- [Web サービス入力] コンポーネントと [データの手動入力] コンポーネント (クラスター化するデータの入力を表します) を、最初の [変換の適用] モジュールに接続します。
パイプラインを変更する際の参考として上記の図と情報を使用して、以下の残りの手順に従います。
-
パイプラインには、カスタム データ セットから作成されたモデルの [Web サービス入力] コンポーネントは自動的には含まれません。 アセット ライブラリから [Web サービス入力] コンポーネントを検索し、パイプラインの上部に配置します。 Web Service Input コンポーネントの出力を、キャンバス上に既に存在する最初の Apply Transformation コンポーネントの [データセット] (右) の入力に接続します。
-
推論パイプラインでは、新しいデータが元のトレーニング データのスキーマと一致することを前提としているので、トレーニング パイプラインからの penguin-data データセットが含まれます。 ただし、この入力データには、モデルでは使用されないペンギンの種の列が含まれます。 penguin-data データセットと [データセット内の列の選択] モジュールの両方を削除して、[アセット ライブラリ] セクションの [データの手動入力] モジュールに置き換えます。
-
次に、Enter Data Manually モジュールの設定を変更して、次の CSV 入力が使用されるようにします。これには、3 つの新しいペンギンの観察 (ヘッダーを含む) の特徴値が含まれています。
CulmenLength,CulmenDepth,FlipperLength,BodyMass 39.1,18.7,181,3750 49.1,14.8,220,5150 46.6,17.8,193,3800 -
Enter Data Manually モジュールの出力を、最初の Apply Transformation モジュールの [データセット] (右) 入力に接続します。
-
Evaluate Mode モジュールを削除します。
-
パイプラインが以下の図のようになっていることを確認します。
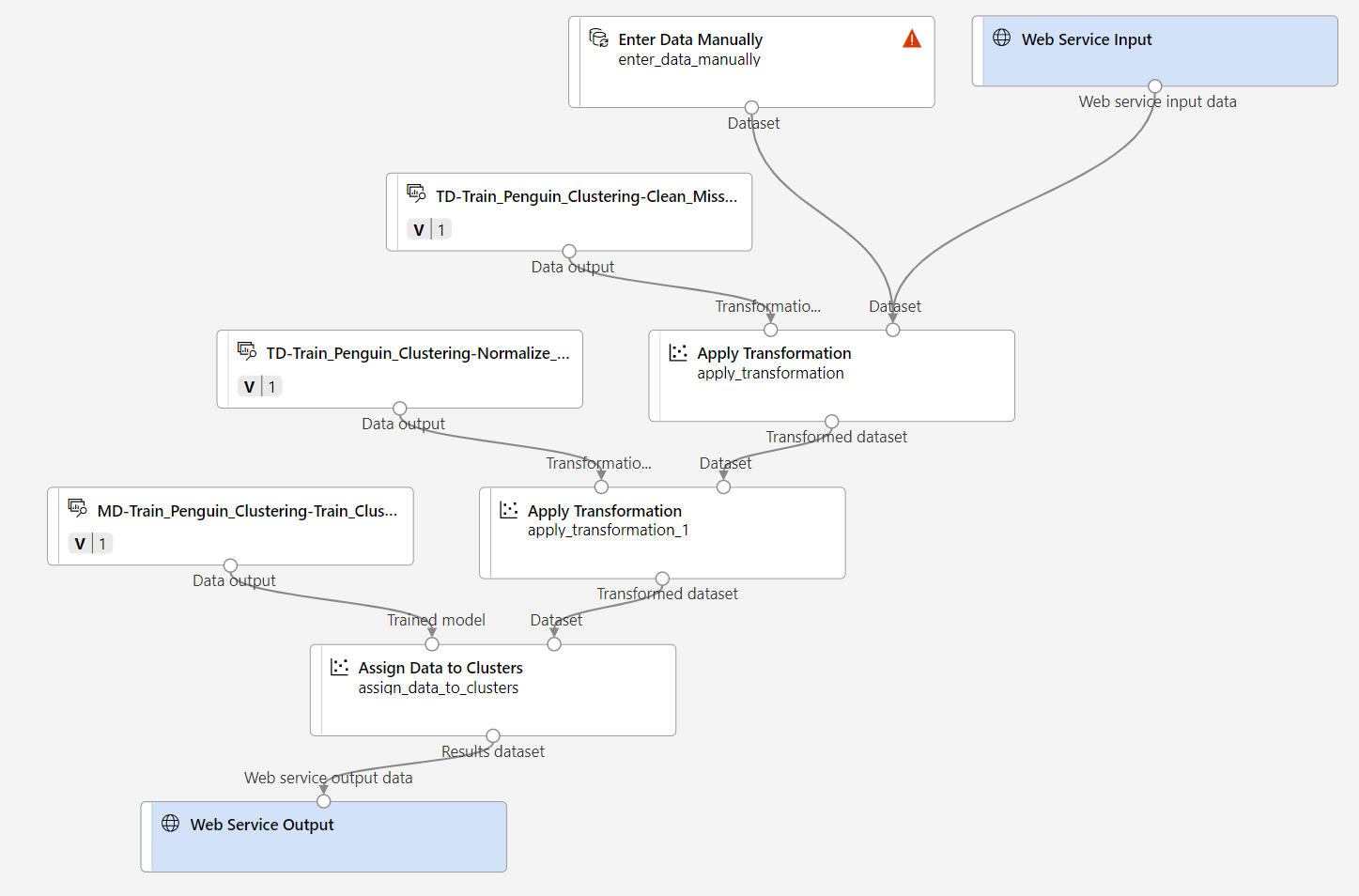
-
コンピューティング クラスター上でパイプラインを mslearn-penguin-inference という名前の新しい実験として送信します。 実験の実行には時間がかかる場合があります。
-
[ジョブ] に移動し、mslearn-penguin-inference 実験名を持つ最新の Predict Penguin Clusters ジョブを選択します。
-
パイプラインが完了したら、 Assign Data to Clusters モジュールを右クリックし、 [データを表示する] を選択し、 Results dataset を選択し、入力データの 3 つのペンギンの観察に対して予測されたクラスターの割り当てとメトリックを確認します。
推論パイプラインにより、特徴に基づいてペンギンの観察がクラスターに割り当てられます。 これで、クライアント アプリケーションで使用できるように、パイプラインを発行する準備ができました。
サービスをデプロイする
この演習では、Azure コンテナー インスタンス (ACI) に Web サービスをデプロイします。 この種類のコンピューティングは、動的に作成され、開発とテストに役立ちます。 運用環境では、”推論クラスター” を作成する必要があります。これにより、スケーラビリティとセキュリティを向上させる Azure Kubernetes Service (AKS) クラスターが提供されます。
-
Predict Penguin Clusters の推論実行ページで、上部のメニュー バーの [デプロイ] を選択します。
![Predict Auto Price (自動車の価格の予測) 推論パイプラインの [デプロイ] ボタンのスクリーンショット。](/AI-900-AIFundamentals.ja-JP/instructions/media/create-clustering-model/deploy-screenshot.png)
- [新しいリアルタイム エンドポイントをデプロイ] を選択し、次の設定を使用します。
- [名前]: predict-penguin-clusters
- [説明]: ペンギンをクラスター化します。
- [コンピューティングの種類]: Azure コンテナー インスタンス
-
Web サービスがデプロイされるまで待ちます。これには数分かかることがあります。
- デプロイの状態を表示するには、画面の左上にあるメニュー アイコンを選択して左側のペインを展開します。 [エンドポイント] ページ ( [資産] の下) を表示し、predict-penguin-clusters を選択します。 デプロイが完了すると、 [デプロイの状態] が [正常] に変わります。
サービスをテストする
-
[エンドポイント] ページで、predict-penguin-clusters リアルタイム エンドポイントを開き、 [テスト] タブを選択します。
![左側のペインの [エンドポイント] オプションの場所のスクリーンショット。](/AI-900-AIFundamentals.ja-JP/instructions/media/create-clustering-model/endpoints-screenshot.png)
-
これを使用して、新しいデータでモデルをテストします。 [データを入力してリアルタイム エンドポイントをテストする] の下の現在のデータを削除します。 次のデータをコピーしてデータ セクションに貼り付けます。
{ "Inputs": { "input1": [ { "CulmenLength": 49.1, "CulmenDepth": 4.8, "FlipperLength": 1220, "BodyMass": 5150 } ] }, "GlobalParameters": {} }注 上の JSON では、ペンギンの特徴を定義し、クラスターの割り当てを予測するために作成した predict-penguin-clusters サービスを使用します。
-
[Test] を選択します。 画面の右側に、出力 ‘Assignments’ が表示されます。 割り当てられたクラスターが、クラスターの中心までの距離が最も短いクラスターであることがわかります。
![サンプルのテスト結果が示された [テスト] ペインのスクリーンショット。](/AI-900-AIFundamentals.ja-JP/instructions/media/create-clustering-model/test-interface.png)
[使用する] タブの資格情報を使用してクライアント アプリケーションに接続する準備ができているサービスをテストしました。ここでラボを終了します。 デプロイしたサービスを引き続き試してみることをお勧めします。
クリーンアップ
作成した Web サービスは “Azure コンテナー インスタンス” にホストされます。 それ以上実験する予定がない場合は、不要な Azure の使用が発生するのを避けるために、エンドポイントを削除する必要があります。 コンピューティング クラスターも削除する必要があります。
-
Azure Machine Learning スタジオの [エンドポイント] タブで、predict-penguin-clusters エンドポイントを選択します。 次に、[削除] (🗑) を選択し、エンドポイントを削除することを確認します。
-
[コンピューティング] ページの [コンピューティング クラスター] タブで、コンピューティング クラスターを選んでから、 [削除] を選びます。
注: コンピューティングを削除すると、確実にサブスクリプションがコンピューティング リソースに対して課金されなくなります。 ただし、サブスクリプションに Azure Machine Learning ワークスペースが存在する限り、データ ストレージに対して少額が課金されます。 Azure Machine Learning の探索を完了したら、Azure Machine Learning ワークスペースとそれに関連付けられたリソースを削除できます。 ただし、このシリーズの他のいずれかのラボを完了する予定がある場合は、作成し直す必要があります。
ワークスペースを削除するには:
- Azure portal の [リソース グループ] ページで、Azure Machine Learning ワークスペースの作成時に指定したリソース グループを開きます。
- [リソース グループの削除] をクリックし、リソース グループ名を入力して削除することを確認し、[削除] を選択します。