Menjelajahi pengelompokan dengan Azure Machine Learning Designer
Catatan Untuk menyelesaikan lab ini, Anda memerlukan langganan Azure dengan akses administrator.
Membuat ruang kerja Pembelajaran Mesin Microsoft Azure
-
Masuk ke portal Microsoft Azure menggunakan kredensial Microsoft Anda.
- Pilih + Buat sumber daya, cari Pembelajaran Mesin, dan buat sumber daya Azure Machine Learning baru dengan paket Azure Machine Learning. Gunakan pengaturan berikut:
- Langganan: Langganan Azure Anda.
- Grup sumber daya: Buat atau pilih grup sumber daya.
- Nama ruang kerja: Masukkan nama unik untuk ruang kerja Anda.
- Wilayah: Pilih wilayah geografis terdekat.
- Akun penyimpanan: Perhatikan akun penyimpanan default baru yang akan dibuat untuk ruang kerja Anda.
- Key vault: Perhatikan key vault baru bawaan yang akan dibuat untuk ruang kerja Anda.
- Application insights: Perhatikan sumber daya application insights baru bawaan yang akan dibuat untuk ruang kerja Anda.
- Registri kontainer: Tidak ada (registri akan dibuat secara otomatis saat pertama kali Anda menyebarkan model ke kontainer)
-
Pilih Tinjau + buat, lalu pilih Buat. Tunggu hingga ruang kerja Anda dibuat (dapat memakan waktu beberapa menit), lalu buka sumber daya yang disebarkan.
-
Pilih Luncurkan studio (atau buka tab browser baru dan arahkan ke https://ml.azure.com, dan masuk ke studio Azure Machine Learning menggunakan akun Microsoft Anda).
- Di studio Azure Machine Learning, Anda akan melihat ruang kerja yang baru dibuat. Jika tidak demikian, pilih direktori Azure Anda di menu sebelah kiri. Kemudian dari menu sebelah kiri yang baru, pilih Ruang Kerja, tempat semua ruang kerja yang terkait dengan langganan Anda dicantumkan.
Catatan Modul ini adalah salah satu dari banyak modul yang memanfaatkan ruang kerja Azure Machine Learning, termasuk modul lainnya di jalur pembelajaran Dasar-Dasar AI Microsoft Azure: Menjelajahi alat visual untuk pembelajaran mesin. Jika menggunakan langganan Azure Anda sendiri, Anda dapat mempertimbangkan untuk membuat ruang kerja satu kali dan menggunakannya kembali di modul lain. Langganan Azure Anda akan dikenakan biaya kecil untuk penyimpanan data selama ruang kerja Azure Machine Learning ada di langganan Anda, jadi sebaiknya hapus ruang kerja Azure Machine Learning saat tidak lagi diperlukan.
Membuat komputasi
-
Di studio Azure Machine Learning, pilih tiga baris di kiri atas untuk melihat berbagai halaman di antarmuka (Anda mungkin perlu memaksimalkan ukuran layar). Anda dapat menggunakan halaman ini di panel sebelah kiri untuk mengelola sumber daya di ruang kerja. Pilih halaman Komputasi (di bagian Kelola).
-
Pada halaman Komputasi, pilih tab Kluster komputasi, dan tambahkan kluster komputasi baru dengan pengaturan berikut. Anda akan menggunakan ini untuk melatih model pembelajaran mesin:
- Lokasi: Pilih lokasi yang sama dengan ruang kerja Anda. Jika lokasi tersebut tidak terdaftar, pilih yang terdekat dengan lokasi Anda.
- Tingkatan mesin virtual: Khusus
- Jenis mesin virtual: CPU
- Ukuran mesin virtual:
- Pilih opsi Pilih dari semua opsi
- Cari dan pilih Standard_DS11_v2
- Pilih Selanjutnya
- Nama komputasi: masukkan nama unik.
- Jumlah minimum node: 0
- Jumlah maksimum node: 2
- Detik diam sebelum menurunkan skala: 120
- Aktifkan akses SSH: Hapus
- Pilih Buat
Catatan Instans dan kluster Komputasi didasarkan pada gambar mesin virtual Azure standar. Untuk modul ini, gambar Standard_DS11_v2 disarankan untuk mencapai keseimbangan biaya dan performa yang optimal. Jika langganan Anda memiliki kuota yang tidak menyertakan gambar ini, pilih gambar alternatif; tetapi perlu diingat bahwa gambar yang lebih besar dapat menimbulkan biaya yang lebih tinggi dan gambar yang lebih kecil mungkin tidak cukup untuk menyelesaikan tugas. Atau, minta administrator Azure Anda untuk memperbesar kuota Anda.
Kluster komputasi akan membutuhkan waktu untuk dibuat. Sembari menunggu, Anda dapat melanjutkan ke langkah berikutnya.
Membuat alur dan menambahkan himpunan data
Untuk memulai dengan perancang Azure Machine Learning, langkah pertama Anda harus membuat alur.
-
Di Azure Machine Learning studio, perluas panel kiri dengan memilih ikon tiga garis di kiri atas layar. Lihat halaman Desainer (di bagian Pembuat), dan pilih + untuk membuat alur baru.
-
Di Pengaturan, pada Detail Draf, ubah nama draf (Pipeline-Created-on-date**) menjadi Latih Pengklusteran Penguin.
Di Azure Machine Learning, data untuk pelatihan model dan operasi lainnya biasanya dirangkum dalam objek yang disebut himpunan data. Dalam modul ini, Anda akan menggunakan himpunan data yang mencakup pengamatan tiga spesies penguin.
-
Lihat halaman Data (di bagian Aset). Halaman Data berisi file atau tabel data tertentu yang Anda rencanakan untuk digunakan di Azure ML.
- Di halaman Data, pada tab Aset data, pilih Buat. Kemudian konfigurasikan aset data dengan pengaturan berikut:
- Jenis data:
- Nama: penguin-data
- Deskripsi: Data penguin
- Jenis himpunan data: Tabular
- Sumber data: Dari File Web
- URL Web
- URL Web: https://aka.ms/penguin-data
- Lewati validasi data: jangan pilih
- Pengaturan:
- Format file: Terbatas
- Pemisah: Koma
- Pengodean: UTF-8
- Header kolom: Hanya file pertama yang memiliki header
- Lompati baris: Tidak ada
- Himpunan data berisi data multibaris: jangan pilih
- Skema:
- Sertakan semua kolom selain Jalur
- Meninjau jenis yang terdeteksi secara otomatis
-
Tinjau
- Pilih Buat
- Jenis data:
- Setelah himpunan data dibuat, buka dan tampilkan halaman Jelajahi untuk melihat sampel data. Data ini menunjukkan pengukuran panjang dan kedalaman culmen (tagihan), panjang sirip, dan massa tubuh untuk beberapa pengamatan penguin. Ada tiga spesies penguin yang diwakili dalam himpunan data: Adelie, Gentoo, dan Chinstrap.
Catatan Himpunan data penguin yang digunakan dalam latihan ini adalah subkumpulan data yang dikumpulkan dan disediakan oleh Dr. Kristen Gorman dan Palmer Station, Antarctica LTER, anggota Long Term Ecological Research Network.
Memuat data ke kanvas
-
Kembali ke alur dengan memilih Perancang di menu sebelah kiri. Pada halaman Desainer, pilih Latih Pengklusteran Penguin.
-
Di samping nama alur di sebelah kiri, pilih ikon anak panah untuk memperluas panel jika belum diperluas. Panel akan terbuka secara default ke panel Pustaka aset, yang ditunjukkan dengan ikon buku di bagian atas panel. Perhatikan bahwa terdapat bilah pencarian untuk menemukan aset. Perhatikan dua tombol, Data dan Komponen.
-
Cari dan tempatkan himpunan data penguin-data ke kanvas.
-
Klik kanan (Ctrl+klik pada Mac) himpunan data penguin-data di kanvas, dan klik Pratinjau data.
-
Tinjau skema data di tab Profil, perhatikan bahwa Anda dapat melihat distribusi berbagai kolom sebagai histogram.
-
Perhatikan karakteristik himpunan data berikut:
- Himpunan data menyertakan kolom berikut:
- CulmenLength: Panjang tagihan penguin dalam milimeter.
- CulmenDepth: Kedalaman tagihan penguin dalam milimeter.
- FlipperLength: Panjang sirip penguin dalam milimeter.
- BodyMass: Berat penguin dalam gram.
- Spesies: Indikator spesies (0:”Adelie”, 1:”Gentoo”, 2:”Chinstrap”)
- Ada dua nilai yang hilang di kolom CulmenLength (kolom CulmenDepth, FlipperLength, dan BodyMass juga memiliki dua nilai yang hilang).
- Nilai pengukuran dalam skala yang berbeda (dari puluhan milimeter hingga ribuan gram).
- Himpunan data menyertakan kolom berikut:
-
Tutup visualisasi himpunan data sehingga Anda dapat melihat himpunan data di kanvas alur pipa.
Menerapkan transformasi
-
Di panel Pustaka aset di sebelah kiri, klik Komponen, yang berisi berbagai modul yang dapat Anda gunakan untuk transformasi data dan pelatihan model. Anda juga dapat menggunakan bilah pencarian untuk menemukan modul dengan cepat.
-
Untuk mengklusterkan pengamatan penguin, kita hanya akan menggunakan pengukuran - kita akan mengabaikan kolom spesies. Jadi, cari modul Memilih Kolom dalam Himpunan Data dan tempatkan ke kanvas, di bawah modul penguin-data dan sambungkan output di bagian bawah penguin-data ke input di bagian atas modul Memilih Kolom dalam Himpunan Data, seperti ini:
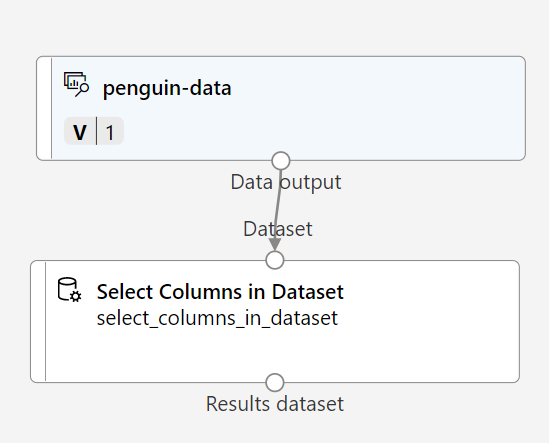
-
Pilih modul Memilih Kolom dalam Himpunan Data, dan pilih Edit kolom di panel sebelah kanan. Kemudian di jendela Pilih kolom, pilih Berdasarkan nama dan gunakan tautan + untuk memilih nama kolom CulmenLength, CulmenDepth, FlipperLength, dan BodyMass; seperti ini:
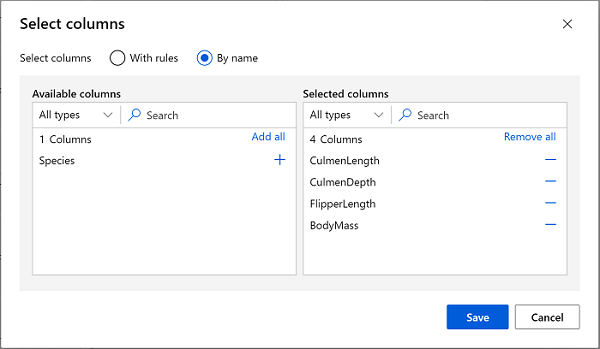
-
Tutup pengaturan modul Pilih Kolom dalam Himpunan Data untuk kembali ke kanvas perancang.
-
Di Pustaka aset, cari modul Membersihkan Data yang Hilang dan tempatkan ke kanvas, di bawah modul Memilih kolom dalam himpunan data dan menyambungkannya seperti ini:
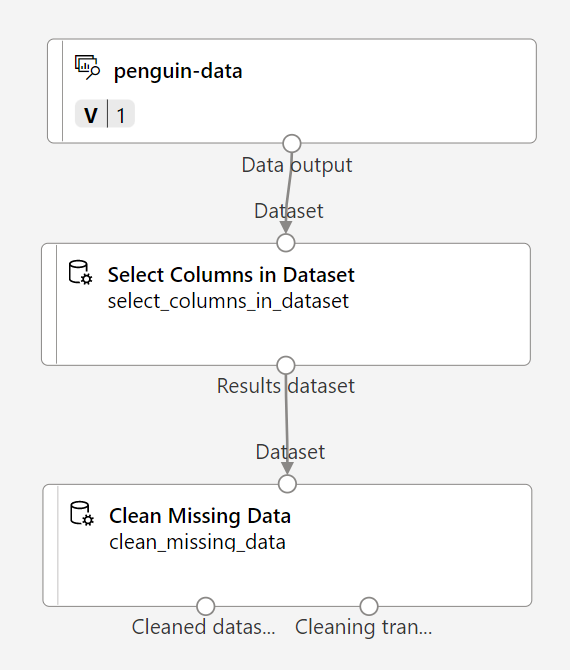
-
Klik dua kali modul Membersihkan Data yang Hilang, dan klik Edit kolom di panel pengaturan di sebelah kanan. Kemudian di jendela Kolom yang akan dihapus, pilih Dengan aturan dan sertakan Semua kolom; seperti ini:
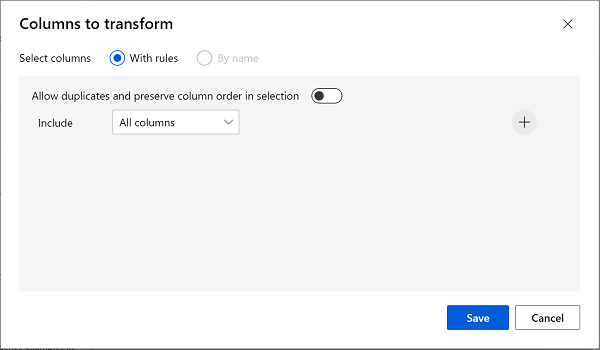
- Pilih Simpan , lalu, di panel pengaturan, atur pengaturan konfigurasi berikut:
- Rasio nilai hilang minimum: 0,0
- Rasio nilai hilang maksimum: 1,0
- Mode penghapusan: Hapus seluruh baris
-
Di Pustaka aset, cari modul Menormalisasi data dan tempatkan ke kanvas, di bawah modul Membersihkan Data yang Hilang. Kemudian, sambungkan output paling kiri dari modul Bersihkan Data yang Hilang ke input modul Normalisasi Data.
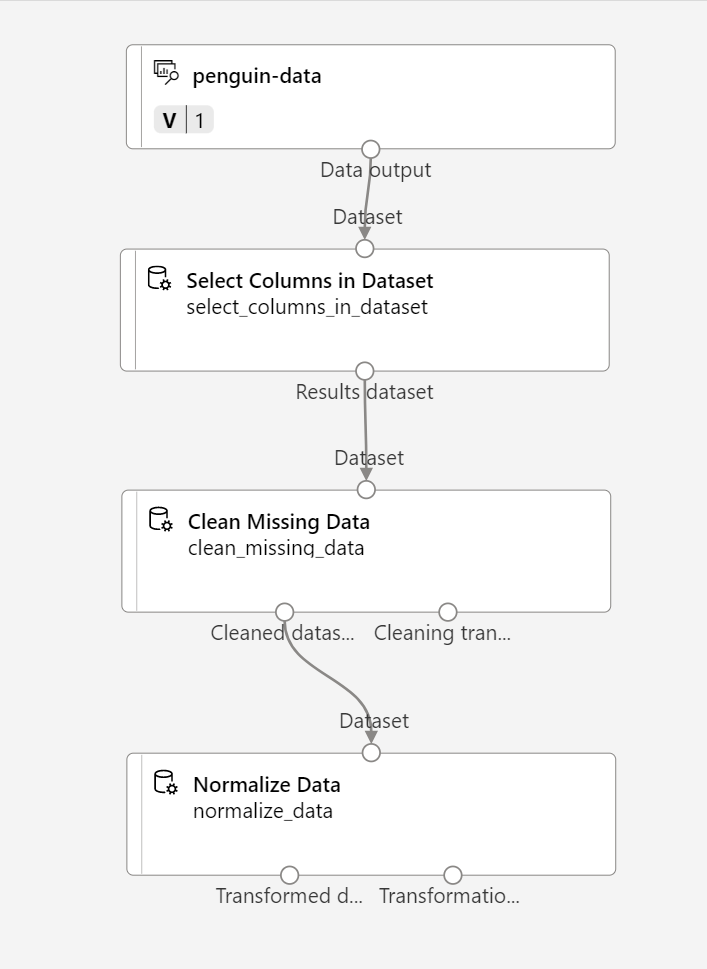
-
Klik dua kali modul Menormalisasi Data, dan di panel sebelah kanan, atur Metode transformasi ke MinMax dan pilih Edit kolom. Kemudian di jendela Kolom yang akan diubah, pilih Dengan aturan dan sertakan Semua kolom; seperti ini:
- Tutup pengaturan modul Normalkan Data untuk kembali ke kanvas perancang.
Menjalankan alur
Untuk menerapkan transformasi data Anda, Anda harus menjalankan alur sebagai eksperimen.
-
Pilih Konfigurasikan & Kirim di bagian atas halaman untuk membuka dialog Siapkan pekerjaan alur.
-
Pada halaman Dasar pilih Buat baru dan atur nama eksperimen ke mslearn-penguin-training lalu pilih Berikutnya .
-
Pada halaman Input & output pilih Berikutnya tanpa membuat perubahan apa pun.
-
Pada halaman Pengaturan runtime muncul kesalahan karena Anda tidak memiliki komputasi default untuk menjalankan alur. Di menu drop-down Pilih jenis komputasi pilih Kluster komputasi dan di menu drop-down Pilih kluster komputasi Azure ML pilih kluster komputasi yang baru dibuat.
-
Pilih Berikutnya untuk meninjau pekerjaan alur lalu pilih Kirim untuk menjalankan alur pelatihan.
-
Tunggu sampai eksekusi selesai. Eksekusi eksperimen dapat memakan waktu 5 menit atau lebih. Anda dapat memeriksa status pekerjaan dengan memilih Pekerjaan di bawah Aset. Dari sana, pilih pekerjaan Latih Pengklusteran ** Penguin.
Menampilkan data yang diubah
-
Ketika eksekusi sudah selesai, modul akan terlihat seperti ini:
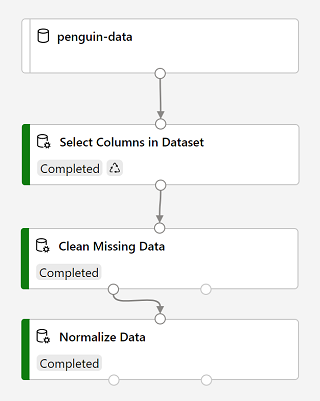
-
Di tab baru, klik kanan modul Normalisasi Data, pilih Lihat pratinjau data, lalu pilih Himpunan data yang diubah untuk melihat hasilnya.
-
Lihat data, mencatat bahwa kolom Spesies telah dihapus, tidak ada nilai yang hilang, dan nilai untuk keempat fitur telah dinormalisasi ke skala umum.
-
Tutup (2) himpunan data untuk kembali ke alur.
Setelah memilih dan menyiapkan fitur yang ingin Anda gunakan dari himpunan data, Anda siap menggunakannya untuk melatih model pengklusteran.
Setelah menggunakan transformasi data untuk menyiapkan data, Anda dapat menggunakannya untuk melatih model pembelajaran mesin.
Menambahkan modul pelatihan
Lakukan langkah-langkah berikut untuk memperluas alurLatih Penguin Pengklusteran seperti yang ditunjukkan di sini:
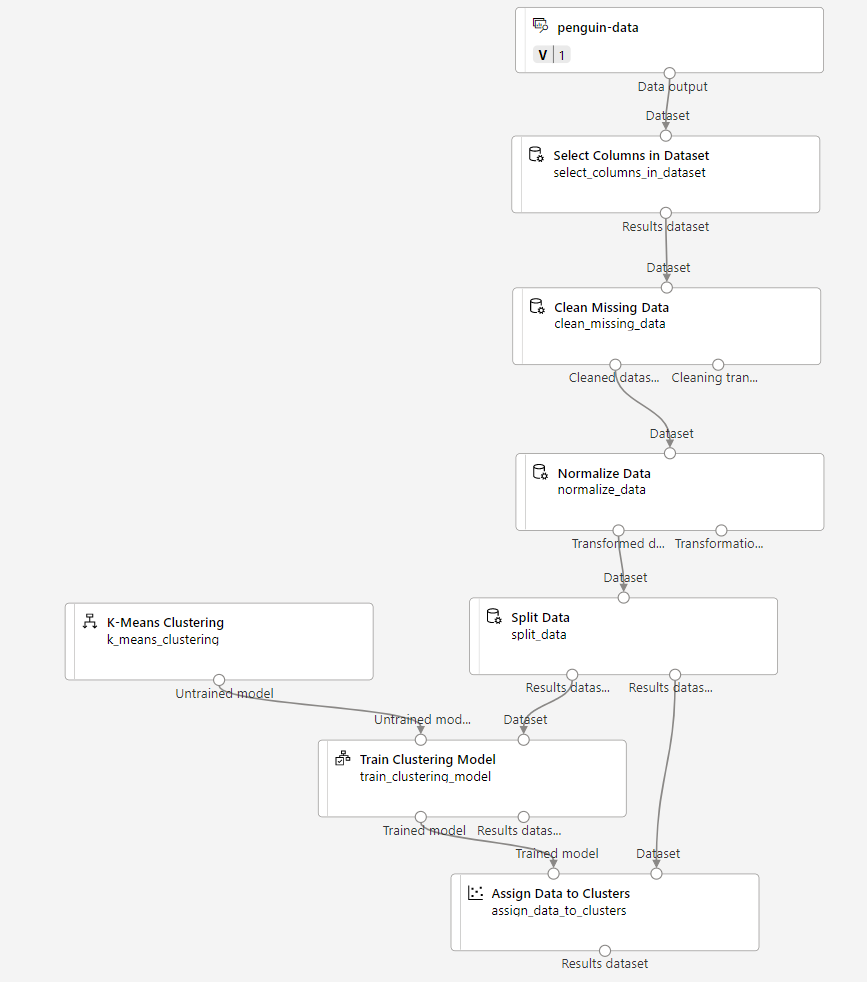
Ikuti langkah-langkah di bawah, menggunakan gambar di atas untuk referensi saat Anda menambahkan dan mengonfigurasi modul yang diperlukan.
-
Kembali ke halaman Perancang ** dan buka **draf alur Pengklusteran Penguin Latih.
-
Di panel Pustaka aset di sebelah kiri, cari dan tempatkan modul Pisahkan Data ke kanvas di bawah modul Normalisasi Data. Kemudian, sambungkan output kiri modul Normalisasi Data ke input modul Pisahkan Data.
Tips Gunakan bilah pencarian untuk menemukan modul dengan cepat.
- Pilih modul Split Data, dan konfigurasikan pengaturannya sebagai berikut:
- Mode pemisah: Pisahkan Baris
- Pecahan baris dalam himpunan data output pertama: 0,7
- Pemisahan acak: Benar
- Nilai awal acak: 123
- Pemisahan bertingkat: False
-
Di pustaka Aset, cari dan tempatkan modul Melatih Model Pengklusteran ke kanvas, di bawah modul Memisahkan Data. Kemudian hubungkan output Hasil dataset1 (kiri) dari modul Pisahkan Data ke input Himpunan data (kanan) dari modul Uji Model Pengklusteran.
-
Model pengklusteran harus menetapkan kluster ke item data dengan menggunakan semua fitur yang Anda pilih dari himpunan data asli. Klik dua kali modul Latih Model Pengklusteran dan di panel sebelah kanan, pilih Edit kolom. Gunakan opsi Dengan aturan untuk menyertakan semua kolom; seperti ini:
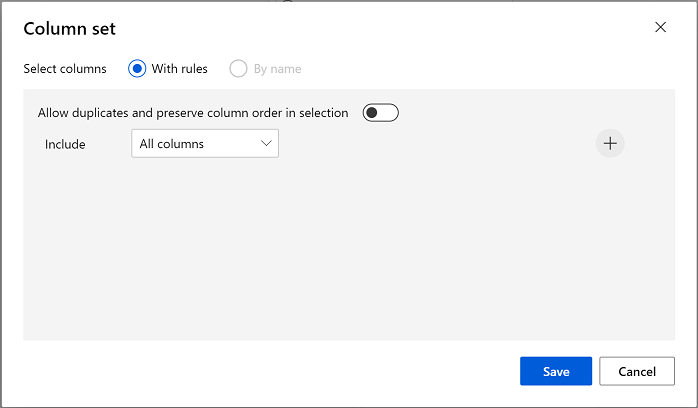
-
Model yang kami latih akan menggunakan fitur untuk mengelompokkan data ke dalam kluster, jadi kami perlu melatih model menggunakan algoritme pengklusteran. Dalam Pustaka aset, cari dan tempatkan modul Pengklusteran K-Means ke kanvas, ke sebelah kiri himpunan data penguin-data dan di atas modul Melatih Model Pengklusteran. Kemudian, sambungkan output-nya ke input Model tidak terlatih (kiri) modul Latih Model Pengklusteran.
-
Algoritme K-Means mengelompokkan item ke jumlah kluster yang Anda tentukan - nilai yang dirujuk sebagai K. Pilih modul Pengklusteran K-Means dan di kanan panel, atur parameter Jumlah sentroid menjadi 3.
Catatan Anda dapat membayangkan observasi data, seperti mengukur penguin, sebagai vektor multidimensi. Algoritme K-Means bekerja dengan:
- menginisialisasi koordinat K sebagai titik yang dipilih secara acak yang disebut sentroid dalam ruang n-dimensi (yang mana n adalah jumlah dimensi dalam vektor fitur).
- Merencanakan vektor fitur sebagai titik di ruang yang sama, dan menetapkan setiap titik ke sentroid terdekatnya.
- Memindahkan sentroid ke tengah titik yang dialokasikan untuk itu (berdasarkan jarak rata-rata).
- Menetapkan kembali titik ke sentroid terdekatnya setelah perpindahan.
- Mengulangi langkah c. dan D. Mengulangi langkah 3 dan 4 hingga alokasi kluster stabil atau jumlah iterasi yang ditentukan telah selesai.
Setelah menggunakan 70% data untuk melatih model pengklusteran, Anda dapat menggunakan 30% sisanya untuk mengujinya menggunakan model untuk menetapkan data ke kluster.
- Dalam Pustaka aset, cari dan tempatkan modul Menetapkan Data ke Kluster ke kanvas, di bawah modul Melatih Model Pengklusteran. Kemudian, sambungkan output Model terlatih (kiri) modul Latih Model Pengklusteran ke input Model terlatih (kiri) modul Tetapkan Data ke Kluster; dan sambungkan output Dataset2 hasil (kanan) modul Pisahkan Data ke input Himpunan data (kanan) modul Tetapkan Data ke Kluster.
Menjalankan alur pelatihan
Sekarang Anda siap untuk menjalankan alur pelatihan dan melatih model.
-
Pastikan alur Anda terlihat seperti ini:
-
Pilih Kirim, dan jalankan alur menggunakan eksperimen yang ada bernama mslearn-penguin-training pada kluster komputasi Anda.
-
Tunggu sampai eksekusi selesai. Eksekusi eksperimen dapat memakan waktu 5 menit atau lebih. Periksa status pekerjaan dengan memilih Pekerjaan di bawah Aset. Dari sana, pilih pekerjaan Latih Pengklusteran** Penguin terbaru**.
-
Di tab baru, klik kanan modul Tetapkan Data ke Kluster, pilih Lihat pratinjau data, lalu pilih Himpunan data hasil untuk melihat hasilnya.
-
Gulir ke kanan, dan perhatikan kolom Tugas, yang berisi kluster (0, 1, atau 2) tempat setiap baris ditetapkan. Ada juga kolom baru yang menunjukkan jarak dari titik yang mewakili baris ini ke pusat masing-masing kluster - kluster yang titiknya paling dekat adalah yang ditetapkan.
-
Tutup visualisasi Results_dataset untuk kembali ke eksekusi alur.
Model ini memprediksi kluster untuk pengamatan penguin, tetapi seberapa andal prediksinya? Untuk menilai itu, Anda perlu mengevaluasi model.
Mengevaluasi model pengklusteran dibuat sulit oleh fakta bahwa sebelumnya tidak ada nilai true yang diketahui untuk penetapan kluster. Model pengklusteran yang sukses adalah model yang mencapai tingkat pemisahan yang baik antara item di setiap kluster, jadi kami membutuhkan metrik untuk membantu kami mengukur pemisahan tersebut.
Menambahkan modul Evaluasi Model
-
Pada halaman Desainer, pilih Latih Pengklusteran Penguin.
-
Di Pustaka aset, cari dan tempatkan modul Mengevaluasi Model pada kanvas, di bawah modul Menetapkan Data ke Kluster. Sambungkan output modul Menetapkan Data ke Kluster ke input Himpunan data yang dinilai (kiri) dari modul Mengevaluasi Model.
-
Pastikan alur Anda terlihat seperti ini:
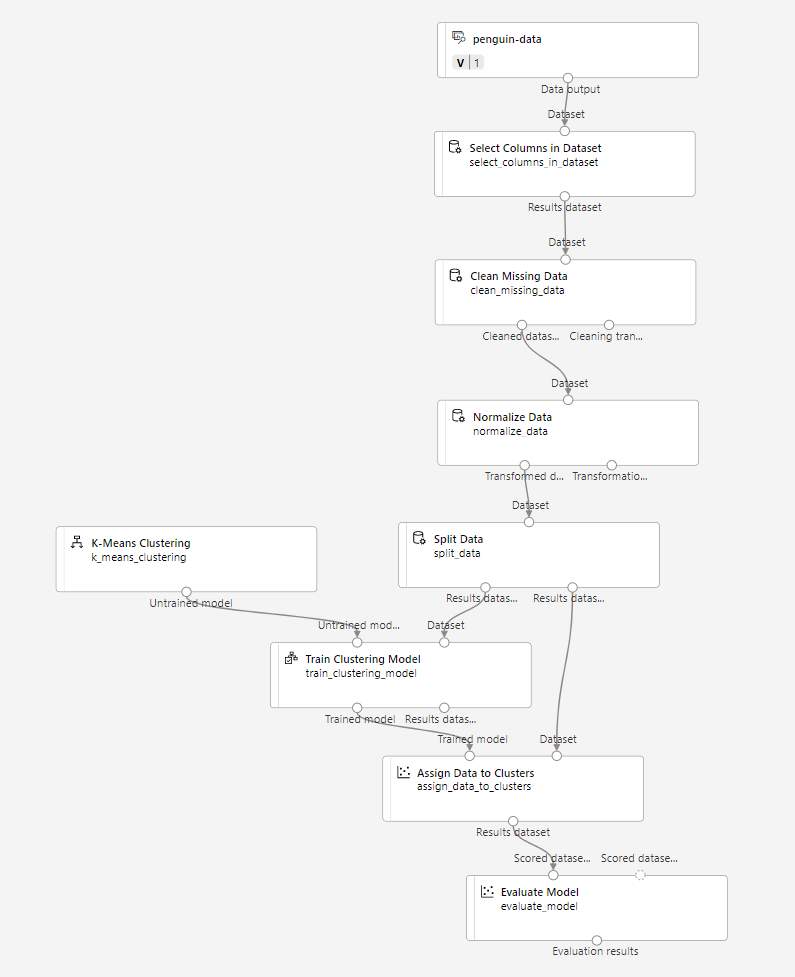
-
Pilih Kirim, dan jalankan alur menggunakan eksperimen yang ada bernama mslearn-penguin-training pada kluster komputasi Anda.
-
Tunggu hingga eksekusi eksperimen selesai. Untuk memeriksa statusnya, buka halaman Pekerjaan dan pilih pekerjaan Melatih Pengklusteran** Penguin terbaru**.
- Klik kanan modul Mengevaluasi Model dan pilih Pratinjau data, lalu pilih Hasil evaluasi. Tinjau metrik di setiap baris:
- Jarak Rata-Rata ke Pusat Lainnya
- Jarak Rata-Rata ke Pusat Kluster
- Jumlah Poin
- Jarak Maksimal ke Pusat Kluster
- Tutup panel Evaluation_results.
Setelah memiliki model pengklusteran yang berfungsi, Anda dapat menggunakannya untuk menetapkan data baru ke kluster dalam alur inferensi.
Setelah membuat dan menjalankan alur untuk melatih model pengklusteran, Anda dapat membuat alur inferensi. Alur inferensi menggunakan model untuk menetapkan pengamatan data baru ke kluster. Model ini akan menjadi dasar untuk layanan prediktif yang dapat Anda terbitkan untuk digunakan oleh aplikasi.
Membuat alur inferensi
-
Cari menu di atas kanvas dan klik Buat alur inferensi. Anda mungkin perlu memperluas layar hingga penuh dan mengeklik ikon tiga titik … di sudut kanan atas layar untuk menemukan Buat alur inferensi di menu.

-
Di daftar drop-down Buat alur masuk, klik Alur inferensi real-time. Setelah beberapa detik, versi baru dari alur Anda bernama Latih Pengklusteran Penguin-inferensi real time akan dibuka.
-
Ganti nama alur baru menjadi Prediksi Kluster Penguin, lalu tinjau alur baru. Model transformasi dan pengklusteran dalam alur pelatihan Anda adalah bagian dari alur ini. Model yang dilatih akan digunakan untuk menilai data baru. Alur juga berisi output layanan web untuk menampilkan hasil.
Anda akan membuat perubahan berikut pada alur inferensi:
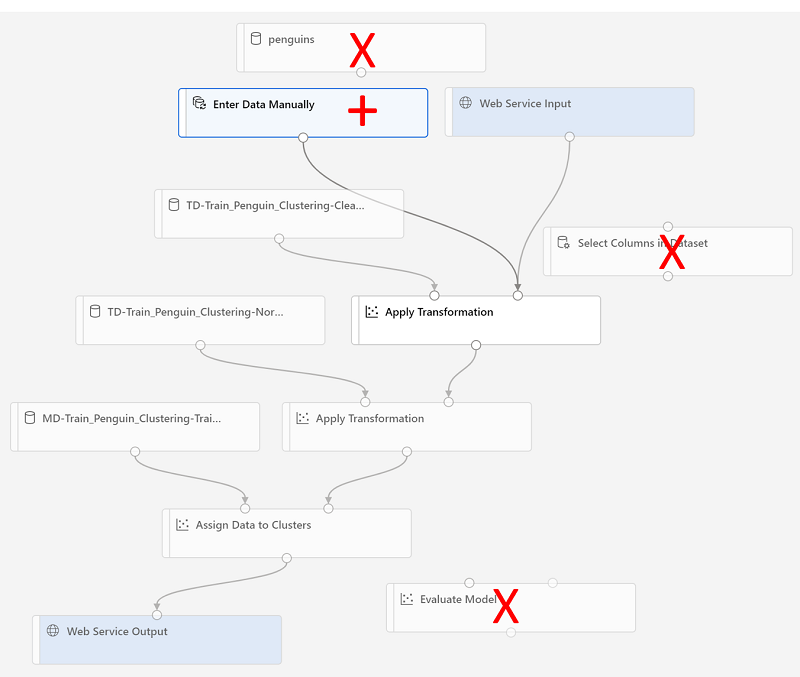
- Tambahkan komponen input layanan web agar data baru dapat dikirimkan.
- Ganti himpunan data penguin-data dengan modul Masukkan Data Secara Manual yang tidak menyertakan kolom Spesies.
- Hapus modul Pilih Kolom dalam Himpunan Data, yang sekarang redundan.
- Sambungkan modul Input Layanan Web dan Masukkan Data Secara Manual (yang mewakili input data yang akan diklusterkan) ke modul Terapkan Transformasi pertama.
Ikuti langkah-langkah yang tersisa di bawah, menggunakan gambar dan informasi di atas untuk referensi saat Anda memodifikasi alur.
-
Alur tidak secara otomatis menyertakan komponen Input Layanan Web untuk model yang dibuat dari himpunan data kustom. Cari komponen Input Layanan Web dari pustaka aset dan tempatkan di bagian atas alur. Hubungkan output komponen Input Layanan Web ke input sisi kanan komponen Terapkan Transformasi yang sudah ada di kanvas.
-
Alur inferensi mengasumsikan bahwa data baru akan cocok dengan skema data pelatihan asli, sehingga himpunan data penguin-data dari alur pelatihan disertakan. Namun, data input ini mencakup kolom untuk spesies penguin, yang tidak digunakan model. Hapus himpunan data penguin-data dan modul Pilih Kolom dalam Himpunan Data, dan ganti dengan modul Masukkan Data Secara Manual dari bagian Pustaka aset.
-
Kemudian, ubah pengaturan modul Masukkan Data Secara Manual untuk menggunakan input CSV berikut, yang berisi nilai fitur untuk tiga pengamatan penguin baru (termasuk header):
CulmenLength,CulmenDepth,FlipperLength,BodyMass 39.1,18.7,181,3750 49.1,14.8,220,5150 46.6,17.8,193,3800 -
Sambungkan output dari modul Input Layanan Web dan Masukkan Data Secara Manual ke input Himpunan Data (kanan) modul Terapkan Transformasi pertama.
-
Hapus modul Evaluasi Model.
-
Verifikasi bahwa alur Anda terlihat mirip dengan gambar berikut:
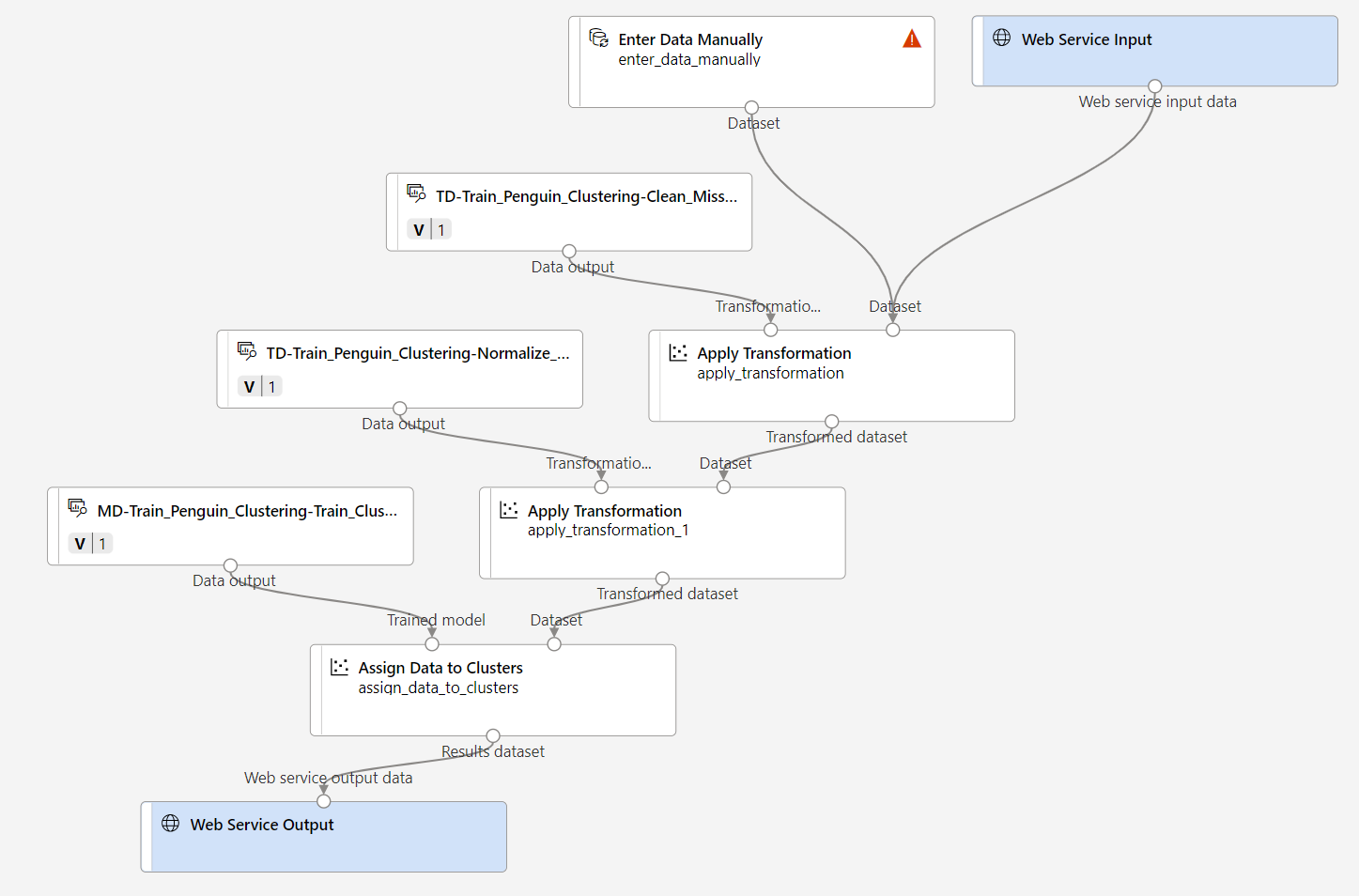
-
Kirimkan alur sebagai eksperimen baru bernama mslearn-penguin-inference pada kluster komputasi Anda. Eksperimen mungkin memerlukan beberapa saat untuk dijalankan.
-
Buka Pekerjaan** dan pilih pekerjaan Predict Penguin Clusters** terbaru dengan **nama eksperimen mslearn-penguin-inference.**
-
Di tab baru, klik kanan pada modul Tetapkan Data ke Kluster, pilih Lihat pratinjau data dan pilih Himpunan data hasil untuk melihat perkiraan penetapan dan metrik kluster untuk tiga pengamatan penguin dalam data input.
Alur inferensi Anda menetapkan pengamatan penguin ke kluster berdasarkan fiturnya. Sekarang Anda siap menerbitkan alur agar aplikasi klien dapat menggunakannya.
Menyebarkan layanan
Dalam latihan ini, Anda akan menyebarkan layanan web ke Azure Container Instance (ACI). Jenis komputasi ini dibuat secara dinamis, serta berguna untuk pengembangan dan pengujian. Untuk produksi, Anda harus membuat kluster inferensi, yang menyediakan kluster Azure Kubernetes Service (AKS) yang memberikan skalabilitas dan keamanan yang lebih baik.
-
Saat berada di halaman eksekusi inferensi Prediksi Kluster Penguin, pilih Sebarkan di bilah menu atas.

- Sebarkan titik akhir real time baru, menggunakan pengaturan berikut:
- Nama: predict-penguin-clusters
- Deskripsi: Penguin kluster.
- Jenis komputasi: Azure Container Instance
-
Tunggu hingga layanan web disebarkan - ini bisa memakan waktu beberapa menit.
- Untuk melihat status penyebaran, luaskan panel kiri dengan memilih tiga baris di kiri atas layar. Lihat halaman Titik akhir (di bagian Aset) dan pilih predict-penguin-clusters. Setelah penyebaran selesai, status Penyebaran akan berubah menjadi Sehat.
Menguji layanan
-
Pada halaman Titik akhir, buka titik akhir real time predict-penguin-clusters, dan pilih tab Uji.
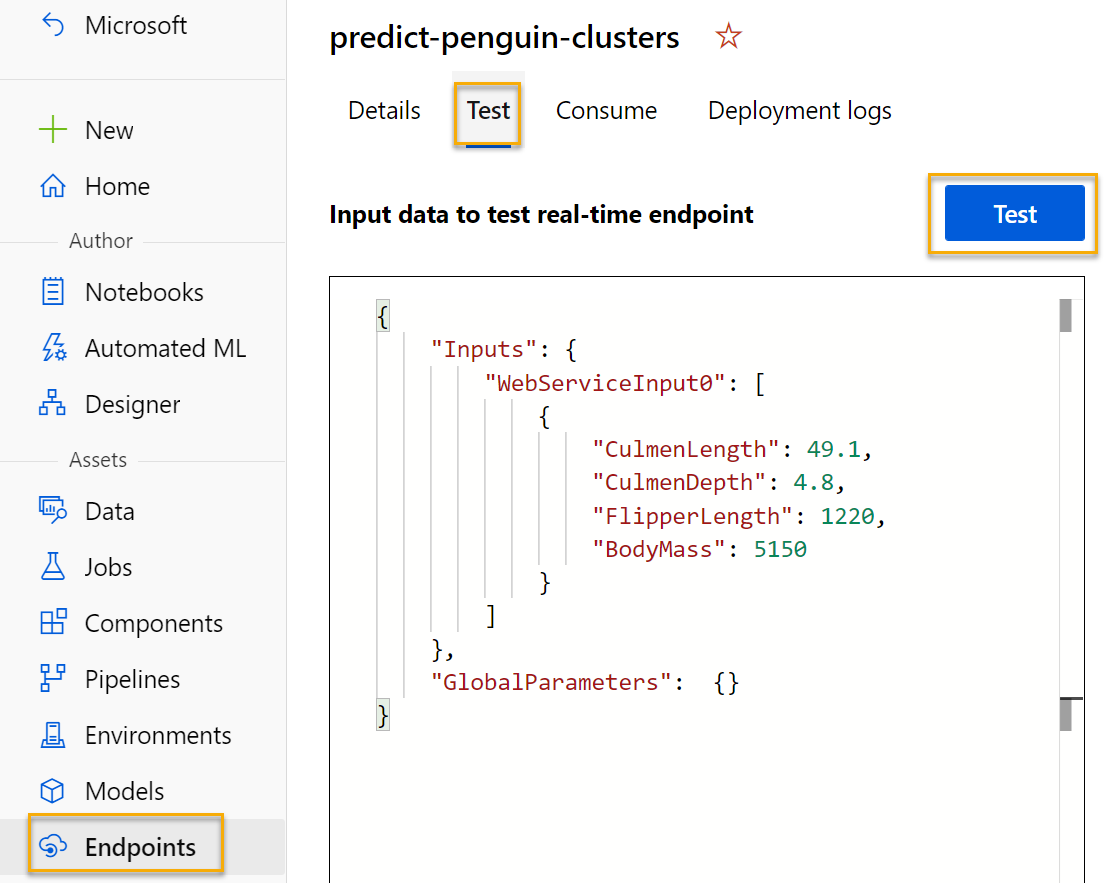
-
Kami akan menggunakannya untuk menguji model dengan data baru. Hapus data saat ini pada Data input untuk menguji titik akhir real time. Salin dan tempel data di bawah ini ke bagian data:
{ "Inputs": { "input1": [ { "CulmenLength": 49.1, "CulmenDepth": 4.8, "FlipperLength": 1220, "BodyMass": 5150 } ] }, "GlobalParameters": {} }Catatan JSON di atas menentukan fitur untuk penguin, dan menggunakan layanan predict-penguin-clusters yang Anda buat untuk memprediksi tugas kluster.
-
Pilih Uji. Di sebelah kanan layar, Anda akan melihat ‘Penetapan’ output. Perhatikan bagaimana kluster yang ditetapkan adalah kluster dengan jarak terpendek ke pusat kluster.
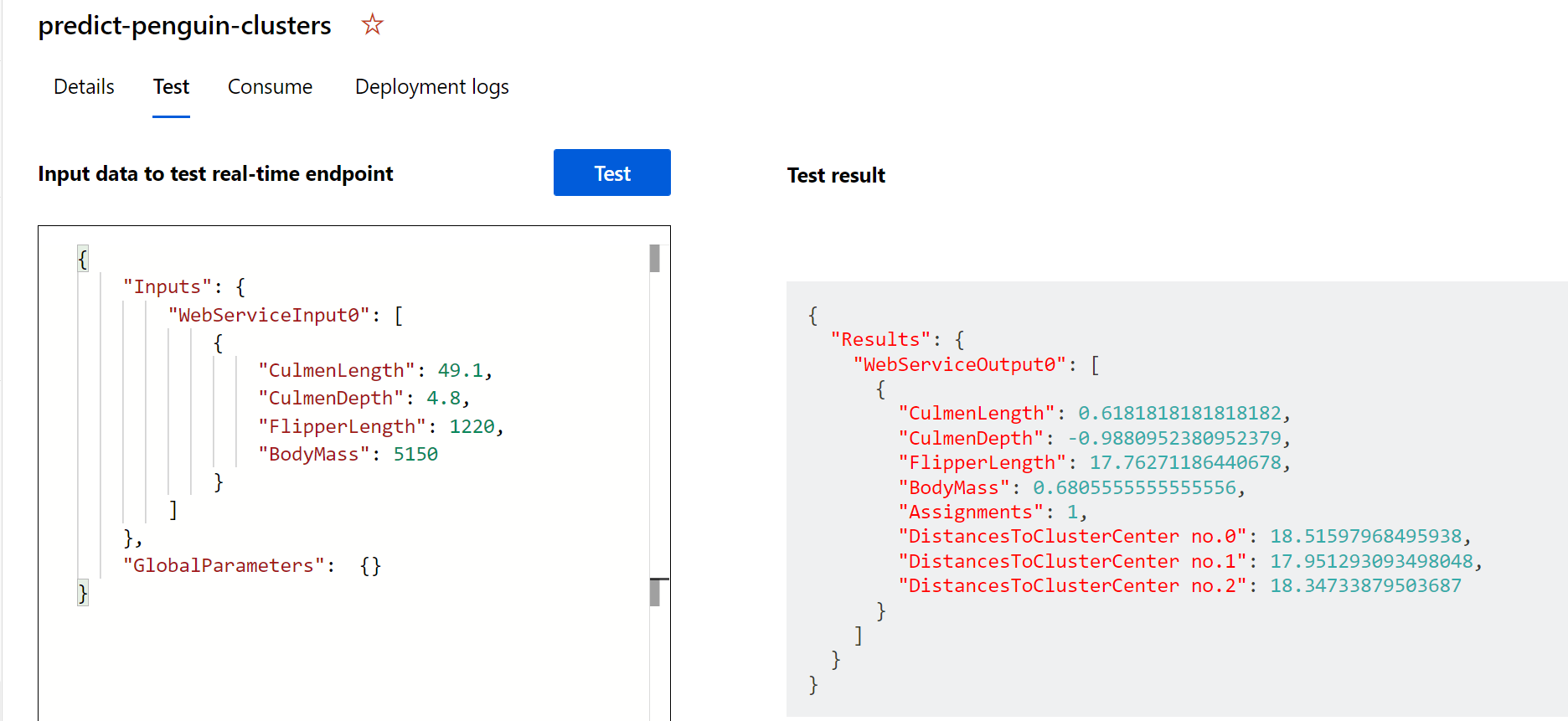
Anda baru saja menguji layanan yang siap untuk disambungkan ke aplikasi klien menggunakan kredensial di tab Konsumsi. Kami akan mengakhiri lab di sini. Anda dipersilakan untuk terus bereksperimen dengan layanan yang baru saja Anda sebarkan.
Pembersihan
Layanan web yang Anda buat dihost dalam Azure Container Instance. Jika tidak berniat untuk bereksperimen dengan ini lebih lanjut, Anda harus menghapus titik akhir untuk menghindari mengumpulkan penggunaan Azure yang tidak perlu. Anda juga harus menghapus kluster komputasi.
-
Di studio Azure Machine Learning, di tab Titik Akhir, pilih titik akhir predict-penguin-clusters. Selanjutnya, pilih Hapus (🗑) dan konfirmasikan bahwa Anda ingin menghapus titik akhir.
-
Pada halaman Komputasi, pada tab Kluster komputasi, pilih kluster komputasi Anda, lalu pilih Hapus.
Catatan Menghentikan komputasi memastikan langganan Anda tidak akan dikenakan biaya untuk sumber daya komputasi. Namun, Anda akan dikenakan biaya kecil untuk penyimpanan data selama ruang kerja Azure Machine Learning ada di langganan Anda. Jika telah selesai menjelajahi Azure Machine Learning, Anda dapat menghapus ruang kerja Azure Machine Learning dan sumber daya terkait. Namun, jika berencana untuk menyelesaikan laboratorium lain dalam seri ini, Anda harus membuatnya kembali.
Untuk menghapus ruang kerja Anda:
- Di portal Microsoft Azure, di halaman Grup sumber daya, buka grup sumber daya yang Anda tentukan saat membuat ruang kerja Azure Machine Learning Anda.
- Klik Hapus grup sumber daya, ketik nama grup sumber daya untuk mengonfirmasi bahwa Anda ingin menghapusnya, dan pilih Hapus.