Exploración de la regresión con el diseñador de Azure Machine Learning
Nota Para completar este laboratorio, necesitará una suscripción de Azure en la que tenga acceso de administrador.
En este módulo, entrenará un modelo de regresión que predice el precio de un automóvil en función de sus características.
Creación de un área de trabajo de Azure Machine Learning
-
Inicie sesión en Azure Portal con las credenciales de Microsoft.
- Seleccione +Crear un recurso, busque Machine Learning y cree un recurso de Azure Machine Learning con un plan Azure Machine Learning. Use la configuración siguiente:
- Suscripción: su suscripción a Azure.
- Grupo de recursos: cree o seleccione un grupo de recursos.
- Nombre del área de trabajo: escriba un nombre único para el área de trabajo.
- Región: seleccione la región geográfica más cercana.
- Cuenta de almacenamiento: tenga en cuenta la nueva cuenta de almacenamiento predeterminada que se creará para el área de trabajo.
- Almacén de claves: tenga en cuenta el nuevo almacén de claves predeterminado que se creará para el área de trabajo.
- Application Insights: tenga en cuenta el nuevo recurso de Application Insights predeterminado que se creará para el área de trabajo.
- Registro de contenedor: ninguno (se creará uno automáticamente la primera vez que implemente un modelo en un contenedor).
-
Seleccione Revisar y crear y, luego, Crear. Espere a que se cree el área de trabajo (puede tardar unos minutos) y, a continuación, vaya al recurso implementado.
-
Seleccione Iniciar estudio (o abra una nueva pestaña del explorador y vaya a https://ml.azure.com e inicie sesión en estudio de Azure Machine Learning con su cuenta de Microsoft).
- En estudio de Azure Machine Learning, debería ver el área de trabajo recién creada. Si no es el caso, seleccione el directorio de Azure en el menú de la izquierda. A continuación, en el nuevo menú de la izquierda, seleccione Áreas de trabajo, donde se muestran todas las áreas de trabajo asociadas al directorio y seleccione la que creó para este ejercicio.
Nota Este módulo es uno de los muchos que hacen uso de un área de trabajo Azure Machine Learning, incluidos el resto de módulos de la ruta de aprendizajeMicrosoft Azure AI Fundamentals: exploración de las herramientas visuales para el aprendizaje automático. Si usa su propia suscripción de Azure, le recomendamos que cree el área de trabajo una vez y la reutilice en otros módulos. A la suscripción de Azure se le cargará un importe reducido por el almacenamiento de datos, siempre y cuando el área de trabajo de Azure Machine Learning exista en la suscripción, por lo que se recomienda eliminar el área de trabajo de Azure Machine Learning cuando ya no sea necesaria.
Creación del proceso
-
En Estudio de Azure Machine Learning, seleccione el icono ≡ (un icono de menú que se parece a una pila de tres líneas) en la parte superior izquierda para ver las distintas páginas de la interfaz (es posible que tenga que maximizar el tamaño de la pantalla). Puede usar estas páginas del panel de la izquierda para administrar los recursos del área de trabajo. Vea la página Proceso (en Administrar).
-
En la página Proceso, seleccione la pestaña Clústeres de proceso y agregue un clúster de proceso nuevo con la configuración siguiente para entrenar un modelo de Machine Learning:
- Ubicación: seleccione la misma que el área de trabajo. Si esa ubicación no aparece, elija la más cercana.
- Nivel de máquina virtual: dedicado
- Tipo de máquina virtual: CPU
- Tamaño de la máquina virtual:
- Elija Seleccionar de entre todas las opciones
- Busque y seleccione Standard_DS11_v2
- Seleccione Siguiente.
- Nombre del proceso: escriba un nombre único
- Número mínimo de nodos: 0
- Número máximo de nodos: 2
- Segundos de inactividad antes de la reducción vertical: 120
- Habilitar acceso SSH: Eliminar
- Seleccione Crear
Nota Las instancia de proceso y los clústeres se basan en imágenes de máquina virtual de Azure estándar. Para este módulo, se recomienda la imagen Standard_DS11_v2 para lograr el equilibrio óptimo entre el costo y el rendimiento. Si la suscripción tiene una cuota que no incluye esta imagen, elija una imagen alternativa, pero tenga en cuenta que una imagen más grande puede incurrir en un costo mayor y una imagen más pequeña puede no ser suficiente para completar las tareas. Como alternativa, pida al administrador de Azure que amplíe la cuota.
El clúster de proceso tardará algún tiempo en crearse. Mientras espera, puede continuar con el siguiente paso.
Crear una canalización en Designer y agregar un conjunto de datos
Azure Machine Learning incluye un conjunto de datos de ejemplo que puede usar para el modelo de regresión.
-
En Estudio de Azure Machine Learning, expanda el panel izquierdo seleccionando el icono de menú de la parte superior izquierda de la pantalla. Vea la página Diseñador (en Creación) y seleccione + para crear una canalización.
-
Cambie el nombre del borrador (Pipeline-Created-on-* date*) a Auto Price Training.
-
Junto al nombre de la canalización en el lado izquierdo, seleccione el icono de flechas para expandir el panel si está contraído. El panel debería abrirse de forma predeterminada en el Panel biblioteca, indicado por el icono de libros situado en la parte superior del panel. Hay una barra de búsqueda para buscar recursos en el panel y dos botones, Datos y Componentes.
-
Seleccione Componente. Busque el conjunto de datos Datos de precio de automóviles (Sin formato) y colóquelo en el lienzo.
-
Haga clic con el botón derecho (Ctrl+clic en Mac) en el conjunto de datos Automobile price data (Raw) en el lienzo y seleccione Vista previa de los datos.
-
Revise el esquema Salida del conjunto de datos de los datos y observe que puede ver las distribuciones de las distintas columnas como histogramas.
-
Desplácese a la derecha del conjunto de datos hasta que vea la columna Price, que es la etiqueta que predice el modelo.
-
Desplácese de nuevo a la izquierda y seleccione el encabezado de la columna normalized-losses (Pérdidas normalizadas). Después, revise las estadísticas de esta columna. Tenga en cuenta que faltan bastantes valores en esta columna. Los valores que faltan limitan la utilidad de la columna para predecir la etiqueta price, por lo que es posible que quiera excluirla del entrenamiento.
-
Cierre la ventana Salida de datos para poder ver el conjunto de datos en el lienzo de esta forma:
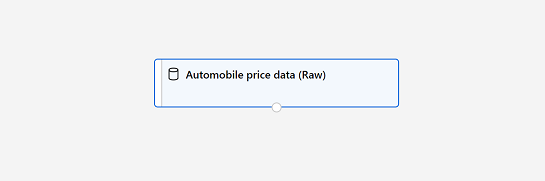
Adición de transformaciones de datos
Normalmente se aplican transformaciones de datos para preparar los datos para el modelado. En el caso de los datos de precios de automóviles, debe agregar transformaciones para solucionar los problemas que ha identificado al explorar los datos.
-
En el panel Biblioteca de recursos de la izquierda, seleccione Componentes, que contiene una amplia gama de módulos que puede usar para la transformación de datos y el entrenamiento del modelo. También puede utilizar la barra de búsqueda para localizar los módulos con rapidez.
-
Busque un módulo Seleccionar columnas del conjunto de datos y colóquelo en el lienzo, debajo del módulo Datos de precio de automóviles (Sin formato). Después, conecte la salida de la parte inferior del módulo Automobile price data (Raw) a la entrada de la parte superior del módulo Seleccionar columnas del conjunto de datos, de esta forma:
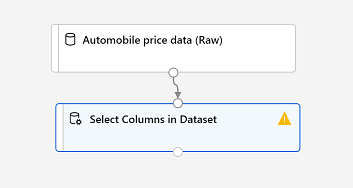
-
Haga doble clic en el módulo Seleccionar columnas del conjunto de datos para acceder a un panel de configuración a la derecha. Seleccione Editar columna. A continuación, en la ventana Seleccionar columnas, seleccione Por nombre y Agregar todo para agregar todas las columnas. A continuación, quite las Pérdidas normalizadas, y la selección de columna final tendrá el siguiente aspecto:
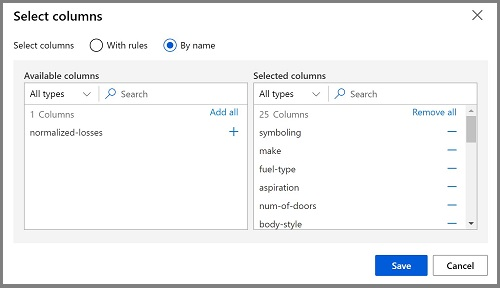
-
Seleccione Guardar y cierre la ventana de propiedades.
En el resto de este ejercicio, aprenderá paso a paso cómo crear una canalización similar a la siguiente:
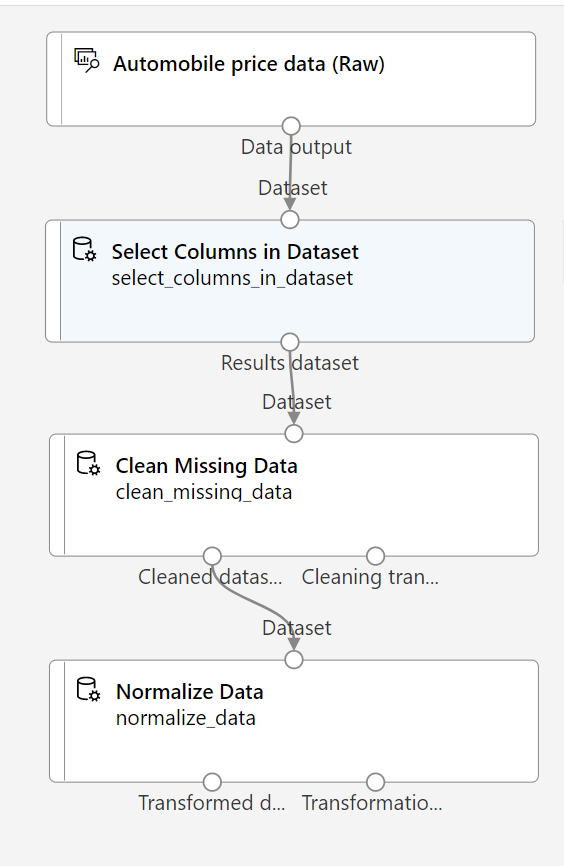
Siga los pasos restantes, y use la imagen como referencia a medida que agrega y configura los módulos necesarios.
-
En el panelBiblioteca de recursos, busque un módulo Limpiar datos que faltan y colóquelo en el módulo Seleccionar columnas del conjunto de datos en el lienzo. Después, conecte la salida del módulo Seleccionar columnas del conjunto de datos a la entrada del módulo Limpiar datos que faltan.
-
Haga doble clic en el módulo Limpiar datos que faltan y, en el panel de la derecha, seleccione Editar columna. Después, en la ventana Columnas para eliminar, seleccione Con reglas, en la lista Incluir seleccione Nombres de columna y, en el cuadro de nombres de columna, escriba bore, stroke y horsepower de esta forma:
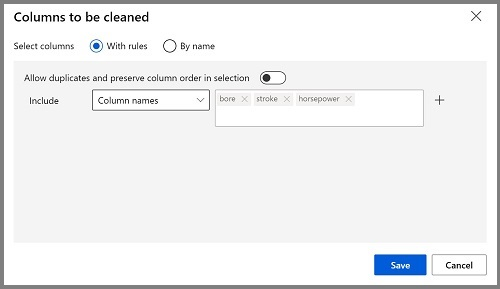
- Con el módulo Limpiar datos que faltan seleccionado, en el panel de la derecha, establezca las siguientes opciones de configuración:
- Relación mínima de valores que faltan: 0,0
- Relación máxima de valores que faltan: 1,0
- Modo de limpieza: quitar toda la fila
Consejo Si ve las estadísticas para las columnas bore, stroke, y horsepower, verá un número de valores que faltan. Estas columnas tienen menos valores que faltan que normalized-losses, por lo que pueden seguir siendo útiles para predecir el valor price cuando se excluyan del entrenamiento las filas en las que faltan valores.
-
En el Panel biblioteca, busque un módulo Normalizar datos y colóquelo en el lienzo, debajo del módulo Limpiar datos que faltan. Después, conecte la salida del módulo Limpiar datos que faltan a la entrada del módulo Normalizar datos.
- Haga doble clic en el módulo Normalizar datos para ver su panel de parámetros. Tendrá que especificar el método de transformación y las columnas que se van a transformar. Establezca la transformación en MinMax. Aplique una regla; para ello, seleccione Editar columna para incluir los siguientes Nombres de columna:
- symboling
- wheel-base
- length
- width
- height
- curb-weight
- engine-size
- bore
- stroke
- compression-ratio
- horsepower
- peak-rpm
- city-mpg
- highway-mpg
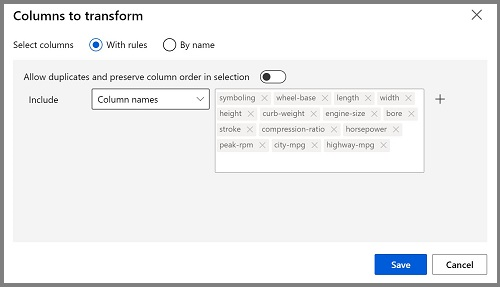
Consejo Si compara los valores de las columnas stroke, peak-rpm, y city-mpg todas se miden en diferentes escalas y es posible que los valores más grandes para peak-rpm puedan sesgar el algoritmo y crear una dependencia excecsiva en esta columna, en comparación con las columnas de valores inferiores, como stroke. Normalmente, los científicos de datos mitigan este posible sesgo mediante la normalización de las columnas numéricas para que estén en escalas similares.
Ejecución de la canalización
Para aplicar las transformaciones de datos, debe ejecutar la canalización.
-
Asegúrese de que la canalización sea similar a esta imagen:
-
Seleccione Configurar y enviar en la parte superior de la página para abrir el diálogo Configurar trabajo de canalización.
-
En la página Aspectos básicos seleccione Crear nuevo y llame al experimento mslearn-auto-training, a continuación, seleccione Siguiente.
-
En la página Entradas y salidas seleccione Siguiente sin hacer cambios.
-
En la página Configuración de runtime aparece un error porque no tiene un proceso predeterminado para ejecutar la canalización. En la lista desplegable Seleccionar tipo de proceso, seleccione Clúster de proceso y en la lista desplegable Seleccionar clúster de proceso de Azure ML seleccione el clúster de proceso que acaba de crear.
-
Seleccione Siguiente para revisar el trabajo de canalización y, a continuación, seleccione Enviar para ejecutar la canalización de entrenamiento.
-
Espere unos minutos hasta que finalice la ejecución. Para comprobar el estado del trabajo, seleccione Trabajos en Recursos. Desde ahí, seleccione el trabajo Auto Price Training. Desde aquí, puede ver cuándo se ha completado el trabajo. Una vez completado el trabajo, el conjunto de datos ya está preparado para el entrenamiento del modelo.
-
Vaya al menú de la izquierda. En Creación, seleccione Diseñador. Después, seleccione la canalización Entrenamiento de precios automáticos en la lista de canalizaciones.
Creación de una canalización de entrenamiento
Después de haber usado transformaciones de datos para preparar los datos, puede usarlos para entrenar un modelo de Machine Learning. Siga estos pasos para ampliar la canalización Auto Price Training.
-
Asegúrese de que el menú izquierdo tiene Diseñador seleccionado y que ha vuelto a la canalización Entrenamiento de precios automáticos.
-
En el panelBiblioteca de la izquierda, busque y coloque un módulo Dividir datos en el lienzo debajo del módulo Normalizar datos. Después, conecte la salida Conjunto de datos transformado (izquierda) del módulo Normalizar los datos a la entrada del módulo Dividir datos.
Consejo Use la barra de búsqueda para localizar los módulos con rapidez.
- Seleccione el módulo Dividir datos y configure sus valores como se indica a continuación:
- Modo de división: dividir filas
- Fracción de filas del primer conjunto de datos de salida: 0,7
- División aleatoria: True
- Valor de inicialización aleatorio: 123
- División estratificada: falso
-
En el panel Biblioteca de recursos, busque y coloque un módulo Entrenar modelo en el lienzo, en el módulo Dividir datos. Después, conecte la salida de Conjunto de datos de resultados 1 (izquierda) del módulo Dividir datos a la entrada Conjunto de datos (derecha) del módulo Entrenar modelo.
-
El modelo que va a entrenar predecirá el valor de price, por lo que debe seleccionar el módulo Entrenar modelo y modificar su configuración para establecer la columna Etiqueta en price (con la misma ortografía y mayúsculas y minúsculas).
La etiqueta price que predecirá el modelo es un valor numérico, por lo que es necesario entrenar el modelo mediante un algoritmo de regresión.
-
En el panel Biblioteca de recursos, busque y coloque un módulo Regresión lineal en el lienzo, a la izquierda del módulo Dividir datos y por encima del módulo Entrenar modelo. Después, conecte su salida a la entrada Modelo no entrenado (izquierda) del módulo Entrenar modelo.
Nota Puede usar varios algoritmos para entrenar un modelo de regresión. Para ayudarle a elegir uno, eche un vistazo a la Hoja de referencia rápida de algoritmos de aprendizaje automático del diseñador de Azure Machine Learning.
Para probar el modelo entrenado, es necesario usarlo para puntuar el conjunto de datos de validación que se ha conservado al dividir los datos originales, es decir, para predecir las etiquetas de las características del conjunto de datos de validación.
-
En el panel Biblioteca de recursos, busque y coloque un módulo Puntuar modelo en el lienzo, debajo del módulo Entrenar modelo. Después, conecte la salida del módulo Entrenar modelo a la entrada Modelo entrenado (izquierda) del módulo Puntuar modelo y arrastre la salida Conjunto de datos de resultados 2 (derecha) del módulo Dividir datos a la entrada Conjunto de datos (derecha) del módulo Puntuar modelo.
-
Asegúrese de que la canalización es similar a la imagen siguiente:
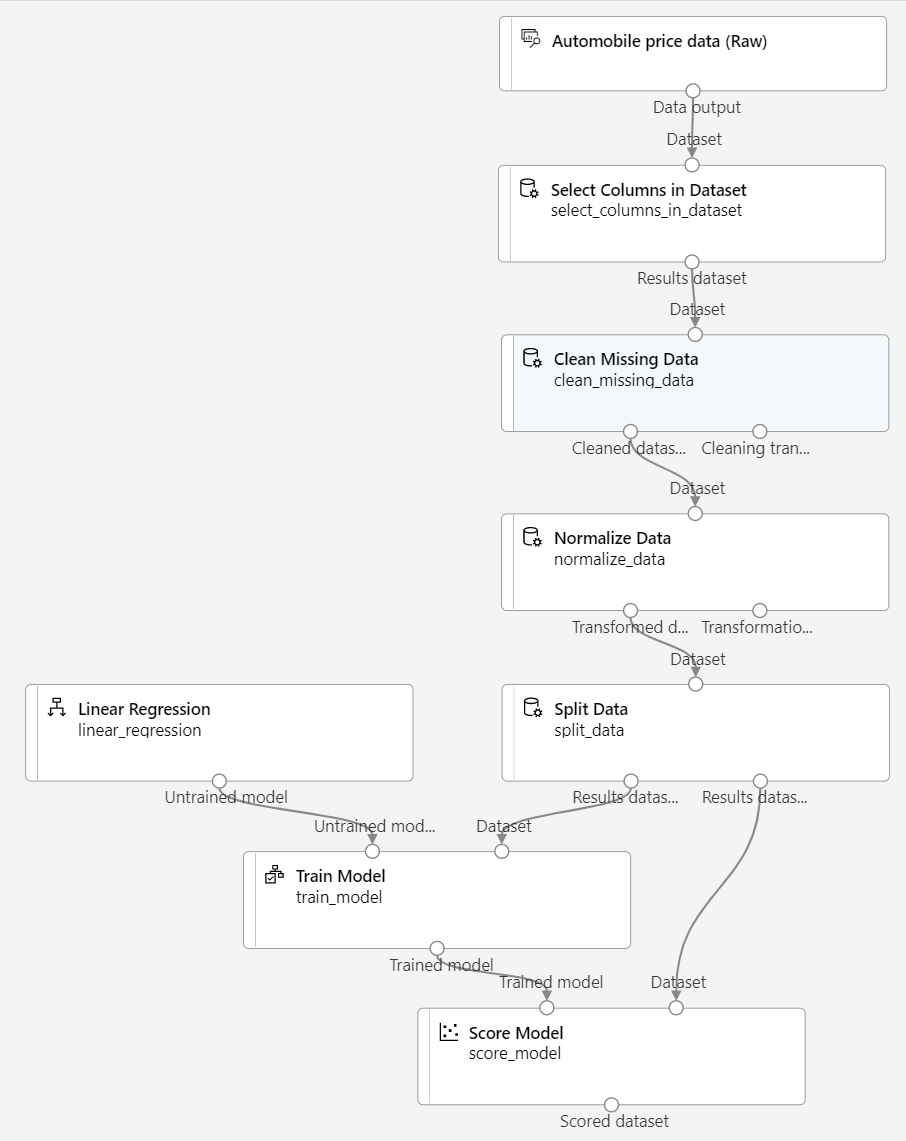
Ejecución de la canalización de entrenamiento
Ya está a punto para ejecutar la canalización de entrenamiento y entrenar el modelo.
-
Seleccione Configurar y enviar y ejecute la canalización mediante el experimento existente llamado mslearn-auto-training.
-
La ejecución del experimento tardará 5 minutos o más en completarse. Vuelva a la página Trabajos y seleccione la ejecución más reciente del trabajo Auto Price Training.
-
Cuando se complete la ejecución del experimento, haga clic con el botón derecho en el módulo Puntuar modelo, seleccione Vista previa de los datos y, a continuación, en Conjunto de datos puntuado para ver los resultados.
-
Desplácese a la derecha y observe que junto a la columna price (que contiene los valores reales conocidos de la etiqueta) hay una nueva columna denominada Etiquetas puntuadas, que contiene los valores de etiqueta pronosticados.
-
Cierre la pestaña scored_dataset.
El modelo predice valores para la etiqueta price, ¿pero qué fiabilidad tienen sus predicciones? Para valorarlo, tendrá que evaluar el modelo.
Evaluación de modelo
Una manera de evaluar un modelo de regresión es comparar las etiquetas previstas con las etiquetas reales del conjunto de datos de validación que se retuvo durante el entrenamiento. Otra manera es comparar el rendimiento de varios modelos.
-
Abra la canalización Auto Price Training que ha creado.
-
En el panel Biblioteca de recursos, busque y coloque un módulo Evaluar modelo al lienzo bajo el módulo Puntuar modelo, y conecte la salida del módulo Puntuar modelo a la entrada Puntuación de conjunto de datos (izquierda) del módulo Evaluar modelo.
-
Asegúrese de que la canalización es similar a la siguiente:
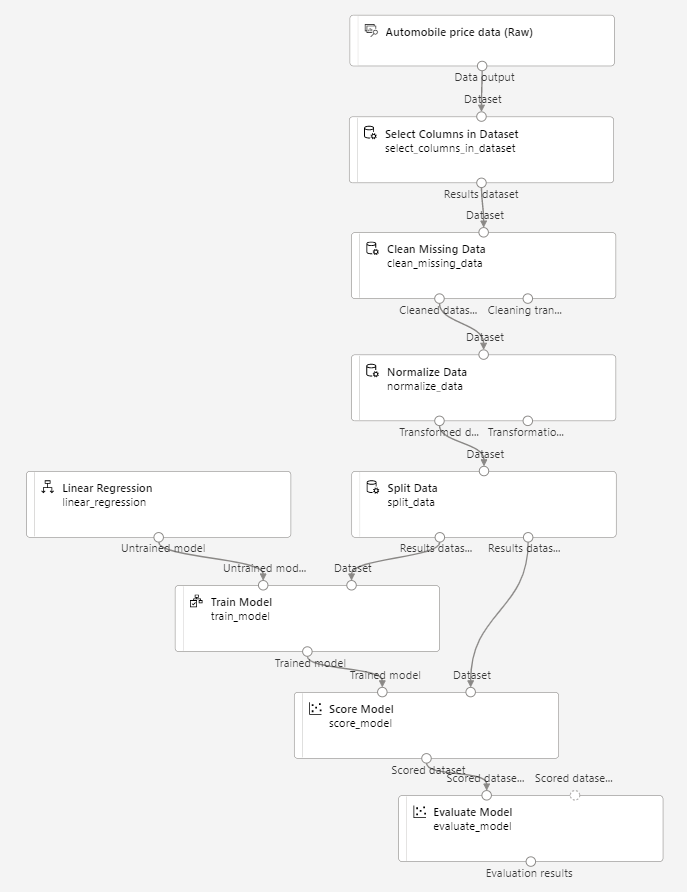
-
Seleccione Configurar y enviar y ejecute la canalización mediante el experimento existente llamado mslearn-auto-training.
-
Esta ejecución del experimento tardará un par de minutos en completarse. Vuelva a la página Trabajos y seleccione la ejecución más reciente del trabajo Auto Price Training.
-
Cuando se haya completado la ejecución del experimento, seleccione Detalles del trabajo, que abrirá otra pestaña. Busque y haga clic con el botón derecho en el módulo Evaluar modelo. Seleccione Vista previa de los datos y, a continuación, Resultados de evaluación.
- En el panel Evaluation_results, revise las métricas de rendimiento de la regresión:
- Error medio absoluto (MAE)
- Raíz del error cuadrático medio (RMSE)
- Error cuadrático relativo (RSE)
- Error absoluto relativo (RAE)
- Coeficiente de determinación (R2)
- Cierre el panel Evaluation_results.
Cuando haya identificado un modelo con métricas de evaluación que se ajusten a las necesidades, puede prepararse para usar ese modelo con nuevos datos.
Creación y ejecución de una canalización de inferencia
-
Busque el menú situado encima del lienzo y seleccione Crear canalización de inferencia. Es posible que tenga que acceder a la pantalla completa y hacer clic en el icono de tres puntos … en la esquina superior derecha de la pantalla para buscar Create inference pipeline (Crear canalización de inferencia) en el menú.

-
En la lista desplegable Crear canalización de inferencia, seleccione Canalización de inferencia en tiempo real. Después de unos segundos, se abrirá una versión nueva de la canalización denominada Entrenamiento de precios automático-inferencia en tiempo real.
-
Cambie el nombre de la nueva canalización a Predicción de precios automática y después revísela. Contiene una entrada de servicio web para los nuevos datos que se van a enviar y una salida de servicio web para devolver los resultados. Algunas de las transformaciones y los pasos de entrenamiento forman parte de esta canalización. El modelo entrenado se usará para puntuar los nuevos datos.
Va a realizar los siguientes cambios en la canalización de inferencia en los pasos siguientes:
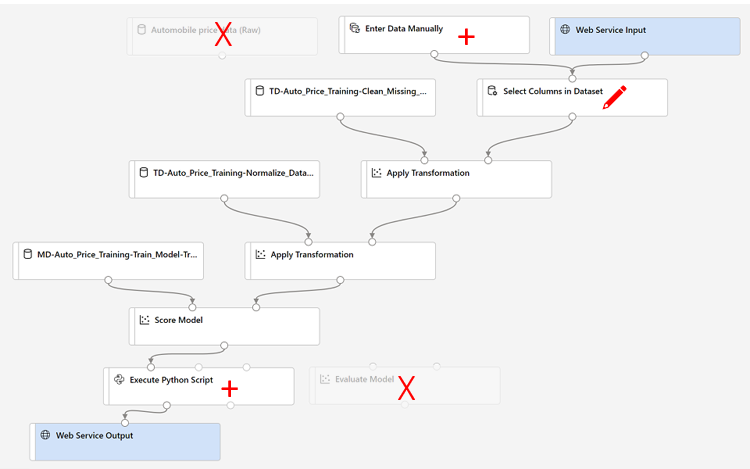
Use la imagen como referencia a medida que modifique la canalización en los pasos siguientes.
- La canalización de inferencia supone que los datos nuevos coincidirán con el esquema de los datos de entrenamiento originales, por lo que se incluye el conjunto de datos Automobile price data (Raw) de la canalización de entrenamiento. Pero estos datos de entrada incluyen la etiqueta price que predice el modelo, lo que no resulta intuitivo incluir en los nuevos datos de automóvil para los que todavía no se ha realizado una predicción del precio. Elimine este módulo y reemplácelo con un módulo Introducir datos manualmente de la sección Entrada y salida de datos.
-
Edite el módulo Introducir datos manualmente e introduzca los siguientes datos CSV, que incluyen valores de características sin etiquetas de tres coches (copie y pegue el bloque de texto entero):
symboling,normalized-losses,make,fuel-type,aspiration,num-of-doors,body-style,drive-wheels,engine-location,wheel-base,length,width,height,curb-weight,engine-type,num-of-cylinders,engine-size,fuel-system,bore,stroke,compression-ratio,horsepower,peak-rpm,city-mpg,highway-mpg 3,NaN,alfa-romero,gas,std,two,convertible,rwd,front,88.6,168.8,64.1,48.8,2548,dohc,four,130,mpfi,3.47,2.68,9,111,5000,21,27 3,NaN,alfa-romero,gas,std,two,convertible,rwd,front,88.6,168.8,64.1,48.8,2548,dohc,four,130,mpfi,3.47,2.68,9,111,5000,21,27 1,NaN,alfa-romero,gas,std,two,hatchback,rwd,front,94.5,171.2,65.5,52.4,2823,ohcv,six,152,mpfi,2.68,3.47,9,154,5000,19,26 -
Conecte el nuevo módulo Escribir los datos manualmente a la misma entrada Conjunto de datos del módulo Seleccionar columnas del conjunto de datos como Entrada de servicio web.
-
Ahora que ha cambiado el esquema de los datos entrantes para excluir el campo** price, tendrá que quitar todos los usos explícitos de este campo en los módulos restantes. Seleccione el módulo **Seleccionar columnas del conjunto de datos y, después, en el panel Configuración, edite las columnas para quitar el campo price.
-
La canalización de inferencia incluye el módulo Evaluar modelo, que no resulta útil al realizar predicciones a partir de los datos nuevos, por lo que puede eliminarlo.
- En la salida del módulo Puntuar modelo se incluyen todas las características de entrada y la etiqueta predicha. Para modificar la salida de forma que solo incluya la predicción:
- Elimine la conexión entre el módulo Puntuar modelo y Salida de servicio web.
- Agregue un módulo Ejecutar script de Python desde la sección Python Language (Lenguaje Python) y reemplace todo el script de Python predeterminado por el código siguiente (que solo selecciona la columna Scored Labels y le cambia el nombre por predicted_price):
import pandas as pd def azureml_main(dataframe1 = None, dataframe2 = None): scored_results = dataframe1[['Scored Labels']] scored_results.rename(columns={'Scored Labels':'predicted_price'}, inplace=True) return scored_resultsNota: Copiar y pegar puede introducir espacios en el script de Python que no deben estar allí. Compruebe que no hay un espacio antes de importar o def o return. Asegúrese de que haya una sangría de tabulación antes de scored_results y scored_results.rename() .
-
Conecte la salida del módulo Puntuar modelo a la entrada del Dataset1 (a la izquierda) del Script de ejecución de Python.
-
Conecte la salida Conjunto de datos resultante (izquierda) del módulo Ejecutar script de Python al módulo Salida de servicio web.
-
Compruebe que la canalización tiene un aspecto similar a la imagen siguiente:
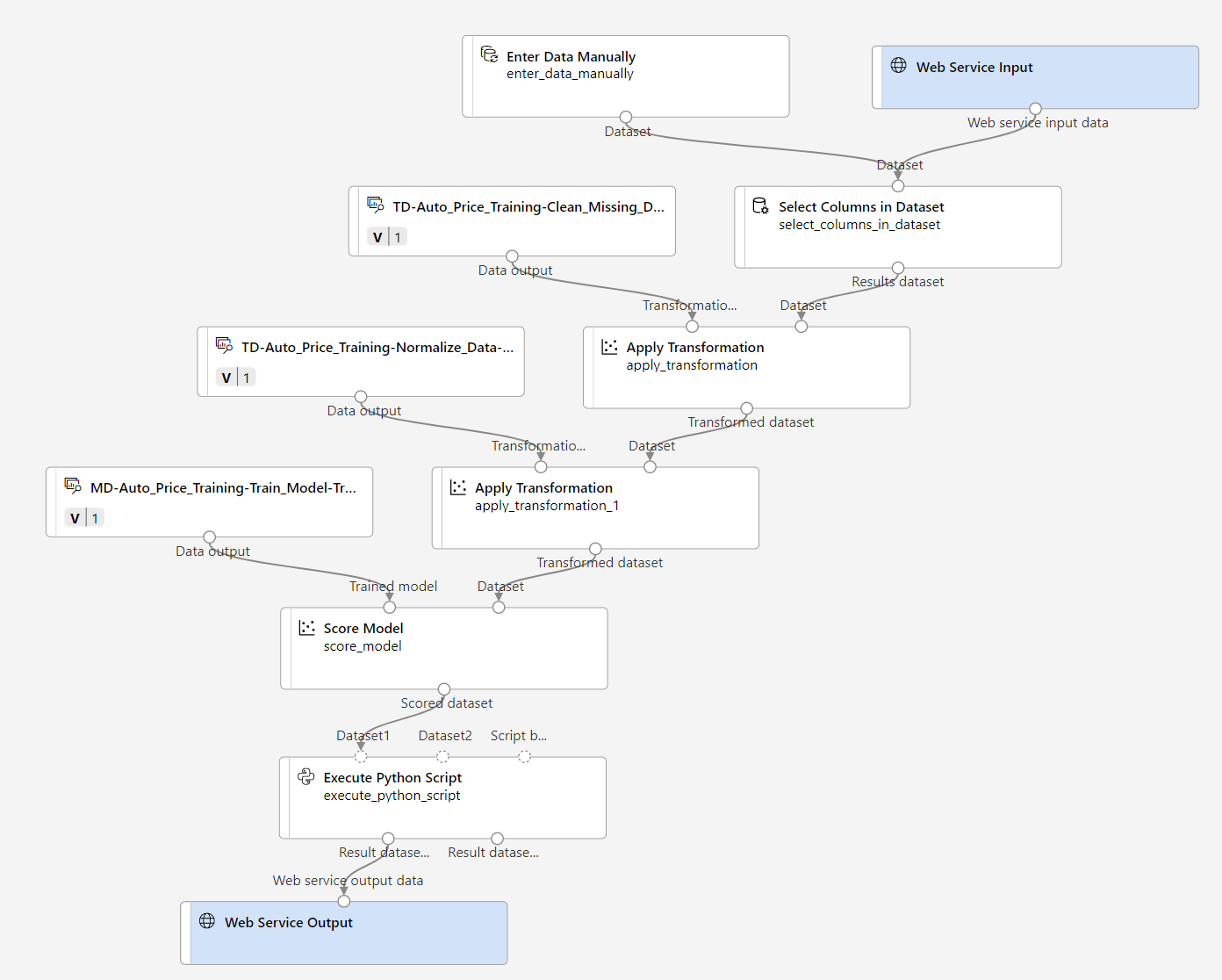
-
Envíe la canalización como un nuevo experimento denominado mslearn-auto-inference en el clúster de proceso. El experimento puede tardar un tiempo en ejecutarse.
-
Vuelva a la página Trabajos y seleccione la ejecución más reciente del trabajo Auto Price Training (la relacionada con mslearn-auto-inference experiment).
-
Cuando se haya completado la canalización, haga clic con el botón derecho en el módulo Ejecutar script de Python. Seleccione Vista previa de datos y luego Conjunto de datos de resultado para ver los precios previstos de los tres automóviles en los datos de entrada.
- Cierre la pestaña Result_Dataset.
La canalización de inferencia predice los precios de los automóviles en función de sus características. Ya está a punto para publicar la canalización a fin de que las aplicaciones cliente la puedan usar.
Implementación de un modelo
Después de crear y probar una canalización de inferencia para la inferencia en tiempo real, puede publicarla como un servicio para que lo usen las aplicaciones cliente.
Nota En este ejercicio, implementará el servicio web en una instancia de Azure Container (ACI). Este tipo de proceso se crea dinámicamente y resulta útil para el desarrollo y las pruebas. Para producción, debe crear un clúster de inferencia, que proporciona un clúster de Azure Kubernetes Service (AKS) que ofrece mejor escalabilidad y seguridad.
Implementación de un servicio
-
En la página del trabajo Predict Auto Price, seleccione Implementar en la barra de menús superior.

- En la pantalla de configuración, seleccione Implementar un nuevo punto de conexión en tiempo real y use siguiente configuración:
- Nombre: predict-auto-price
- Descripción: regresión de precios automática.
- Tipo de proceso: instancia de Azure Container.
- Seleccione Implementar y espere unos minutos a que el servicio web se implemente.
Probar el servicio
-
En la página Puntos de conexión, abra el punto de conexión en tiempo real predict-auto-price.
-
Cuando se abra el punto de conexión predict-auto-price, seleccione la pestaña Prueba. Lo usaremos para probar el modelo con nuevos datos. Elimine los datos actuales en Punto de conexión de prueba de datos de entrada. Copie y pegue los datos siguientes en la sección de datos:
{ "Inputs": { "WebServiceInput0": [ { "symboling": 3, "normalized-losses": 1.0, "make": "alfa-romero", "fuel-type": "gas", "aspiration": "std", "num-of-doors": "two", "body-style": "convertible", "drive-wheels": "rwd", "engine-location": "front", "wheel-base": 88.6, "length": 168.8, "width": 64.1, "height": 48.8, "curb-weight": 2548, "engine-type": "dohc", "num-of-cylinders": "four", "engine-size": 130, "fuel-system": "mpfi", "bore": 3.47, "stroke": 2.68, "compression-ratio": 9, "horsepower": 111, "peak-rpm": 5000, "city-mpg": 21, "highway-mpg": 27 } ] }, "GlobalParameters": {} } -
Seleccione Probar. En la parte derecha de la pantalla, debería ver la salida “predicted_price”. La salida es el precio previsto para un vehículo con las características de entrada concretas especificadas en los datos.
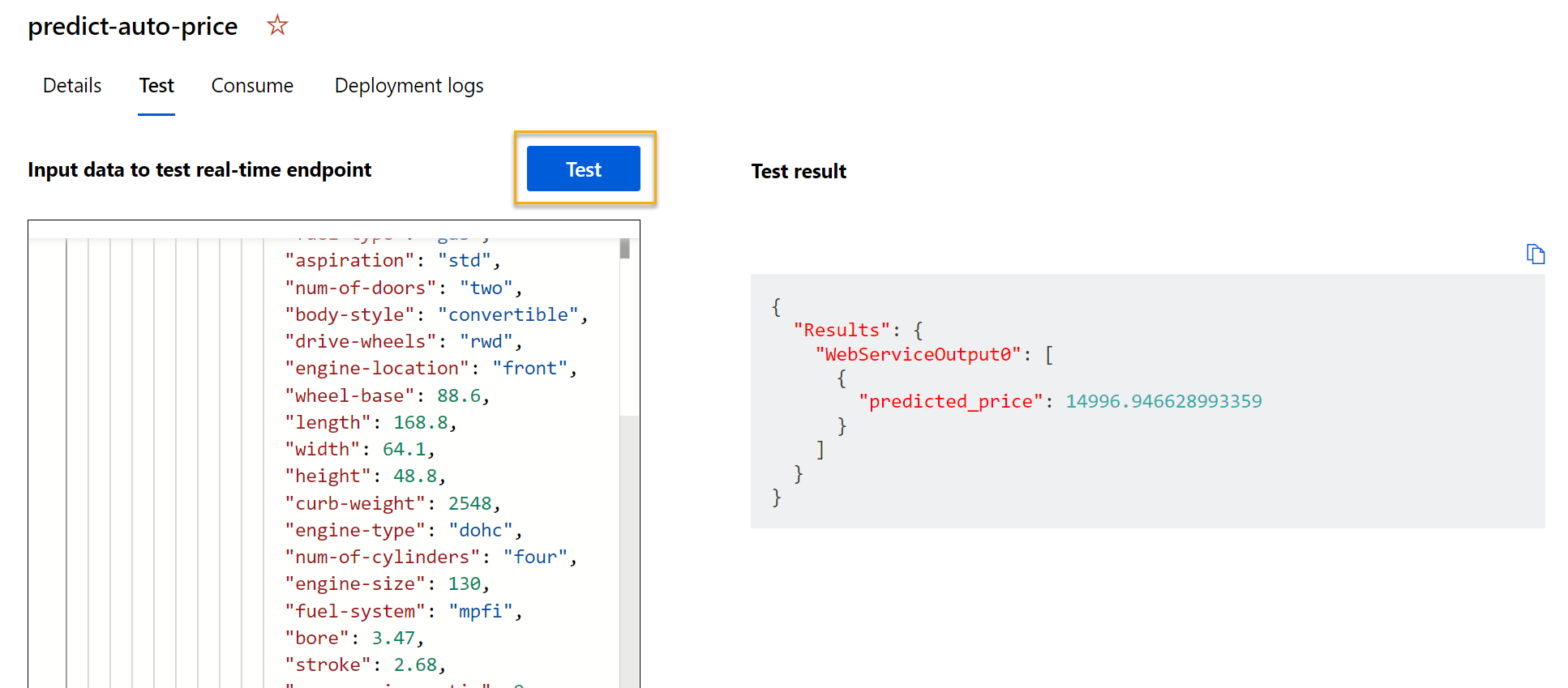
Revisemos lo que ha hecho. Ha limpiado y transformado un conjunto de datos de automóviles y, a continuación, ha usado las características del automóvil para entrenar un modelo. El modelo predice el precio de un automóvil, que es la etiqueta.
También ha probado un servicio que está listo para conectarse a una aplicación cliente mediante las credenciales de la pestaña Consumir. Terminaremos el laboratorio aquí. Si lo desea, puede seguir experimentando con el servicio que acaba de implementar.
Limpieza
El servicio web que se ha creado se hospeda en una instancia de Azure Container. Si no tiene previsto experimentar con él, debe eliminar el punto de conexión para evitar el uso innecesario de Azure. También debe eliminar el clúster de proceso.
-
En Azure Machine Learning Studio, en la pestaña Puntos de conexión, seleccione el punto de conexión predict-auto-price. A continuación, seleccione Eliminar y confirme que quiere eliminar el punto de conexión.
-
En la página Proceso, en la pestaña Instancias de proceso, seleccione su instancia de proceso y, luego, Eliminar.
Nota: Al eliminar el proceso, garantiza que no se cobren los recursos de proceso en la suscripción. Sin embargo, se le cobrará un importe reducido por el almacenamiento de datos, siempre que el área de trabajo de Azure Machine Learning exista en la suscripción. Si ha terminado de explorar Azure Machine Learning, puede eliminar el área de trabajo de Azure Machine Learning y los recursos asociados. Sin embargo, si planea completar cualquier otro laboratorio de esta serie, tendrá que volver a crearla.
Para eliminar el área de trabajo:
- En Azure Portal, en la página Grupos de recursos, abra el grupo de recursos que haya especificado al crear el área de trabajo de Azure Machine Learning.
- Haga clic en Eliminar grupo de recursos, escriba el nombre del grupo de recursos para confirmar que quiere eliminarlo y seleccione Eliminar.