Exploración de Machine Learning automatizado en Azure ML
En este ejercicio, usará la característica de aprendizaje automático automatizado en Azure Machine Learning para entrenar y evaluar un modelo de aprendizaje automático. Después, implementará y probará el modelo entrenado.
Este ejercicio debería tardar en completarse 30 minutos aproximadamente.
Nota Para completar este laboratorio, necesitará una suscripción de Azure en la que tenga acceso de administrador.
Creación de un área de trabajo de Azure Machine Learning
Para usar Azure Machine Learning, debe aprovisionar un área de trabajo de Azure Machine Learning en su suscripción de Azure. Tras haberlo hecho, podrá usar el Estudio de Azure Machine Learning para trabajar con los recursos del área de trabajo.
Sugerencia: si ya tiene un área de trabajo de Azure Machine Learning, puede usarla y pasar a la siguiente tarea.
-
Inicie sesión en Azure Portal en
https://portal.azure.comcon las credenciales de Microsoft. - Seleccione + Crear un recurso, busque Machine Learning y cree un nuevo recurso de Azure Machine Learning con la configuración siguiente:
- Suscripción: su suscripción a Azure.
- Grupo de recursos: cree o seleccione un grupo de recursos.
- Nombre: escriba un nombre único para el área de trabajo.
- Región: seleccione la región geográfica más cercana.
- Cuenta de almacenamiento: tenga en cuenta la nueva cuenta de almacenamiento predeterminada que se creará para el área de trabajo.
- Almacén de claves: tenga en cuenta el nuevo almacén de claves predeterminado que se creará para el área de trabajo.
- Application Insights: tenga en cuenta el nuevo recurso de Application Insights predeterminado que se creará para el área de trabajo.
- Registro de contenedor: ninguno (se creará uno automáticamente la primera vez que implemente un modelo en un contenedor).
-
Seleccione Revisar y crear y, luego, Crear. Espere a que se cree el área de trabajo (puede tardar unos minutos) y, a continuación, vaya al recurso implementado.
-
Seleccione Iniciar estudio (o abra una nueva pestaña del explorador y vaya a https://ml.azure.com e inicie sesión en estudio de Azure Machine Learning con su cuenta de Microsoft). Cierre los mensajes que se muestran.
- En estudio de Azure Machine Learning, debería ver el área de trabajo recién creada. Si no, selecciona Todas las áreas de trabajo en el menú izquierdo y selecciona el área de trabajo que acabas de crear.
Habilitación de características en vista previa (GB)
Algunas características de Azure Machine Learning están en versión preliminar y deben habilitarse explícitamente en el área de trabajo.
-
En Azure Machine Learning Studio, haga clic en Administrar características en versión preliminar (el icono de altavoz: 🕫).

-
Habilite la siguiente característica en vista previa (GB):
- Experiencia guiada para enviar trabajos de entrenamiento con proceso sin servidor
Uso del aprendizaje automático automatizado para entrenar un modelo
El aprendizaje automático automatizado le permite probar varios algoritmos y parámetros para entrenar varios modelos e identificar el que se ajusta mejor a sus datos. En este ejercicio, usará un conjunto de datos de información histórica de alquiler de bicicletas para entrenar un modelo que prediga el número de alquileres de bicicletas que se espera un día determinado, en función de las características estacionales y meteorológicas.
Cita: los datos que se usan en este ejercicio se derivan de Capital Bikeshare y se utilizan de acuerdo con el contrato de licencia de los datos publicados.
-
En Estudio de Azure Machine Learning, vea la página ML automatizado (en Creación).
-
Cree un nuevo trabajo de ML automatizado con la siguiente configuración, usando Siguiente cuando sea necesario para avanzar por la interfaz de usuario:
Configuración básica:
- Nombre del trabajo: mslearn-bike-automl
- Nuevo nombre del experimento: mslearn-bike-rental.
- Descripción: aprendizaje automático automatizado para la predicción del alquiler de bicicletas
- Etiquetas: ninguna
Tipo de tarea y datos:
- Selección del tipo de tarea: regresión
- Selección del conjunto de datos: cree un conjunto de datos con la siguiente configuración:
- Tipo de datos:
- Nombre: bike-rentals.
- Descripción: datos históricos de alquiler de bicicletas
- Tipo: tabular
- Origen de datos:
- Seleccione De archivos web
- Dirección URL web:
- Dirección URL web:
https://aka.ms/bike-rentals - Omitir validación de datos: no seleccionar.
- Dirección URL web:
- Configuración:
- Formato de archivo: delimitado
- Delimitador: coma
- Codificación: UTF-8
- Encabezados de columna: solo el primer archivo tiene encabezados
- Omitir filas: ninguno
- Dataset contains multi-line data (El conjunto de datos contiene datos de varias líneas): no seleccionar
- Esquema:
- incluir todas las columnas que no sean Ruta de acceso
- Revisar los tipos detectados automáticamente
Seleccione el conjunto de datos bike-rentals después de crearlo.
- Tipo de datos:
Configuración de la tarea:
- Tipo de tarea: regresión
- Conjunto de datos: bike-rentals.
- Columna de destino: alquileres (entero)
- Opciones de configuración adicionales:
- Métrica primaria: error de desviación media cuadrática normalizada
- Explicación del mejor modelo: no seleccionado
- Use all supported models (Usar todos los modelos admitidos): no seleccionado. Restringirá el trabajo para probar solo algunos algoritmos específicos.
- Allowed models (Modelos permitidos): seleccione solo RandomForest y LightGBM: normalmente, le gustaría probar tantos como sea posible, pero cada modelo agregado aumenta el tiempo que se tarda en ejecutar el experimento.
- Límites: expanda esta sección
- Pruebas máximas: 3
- Número máximo de pruebas simultáneas: 3
- Número máximo de nodos: 3
- Umbral de puntuación de métrica: 0,85 (esto hace que el experimento finalice si un modelo logra una puntuación de métrica de raíz del error cuadrático medio normalizado de 0,085 o menos).
- Tiempo de expiración: 15
- Tiempo de expiración de iteración: 5
- Habilitación de la terminación anticipada: seleccionada
- Validación y prueba:
- Tipo de validación: división entre entrenamiento y validación.
- Porcentaje de datos de validación: 10
- Conjunto de datos de prueba: ninguno
Proceso:
- Selección del tipo de proceso: sin servidor
- Tipo de máquina virtual: CPU
- Nivel de máquina virtual: dedicado
- Tamaño de máquina virtual: Standard_DS3_V2
- Número de instancias: 1
-
Envíe el trabajo de entrenamiento. Se inicia automáticamente.
-
espere a que el trabajo finalice. Este proceso puede tardar un poco. Ahora podría ser un buen momento para hacer una pausa.
Revisión del mejor modelo
Una vez completado el trabajo de aprendizaje automático automatizado, puede revisar el mejor modelo que haya entrenado.
-
En la pestaña Visión general de la ejecución del aprendizaje automático automatizado, tenga en cuenta el resumen del mejor modelo.
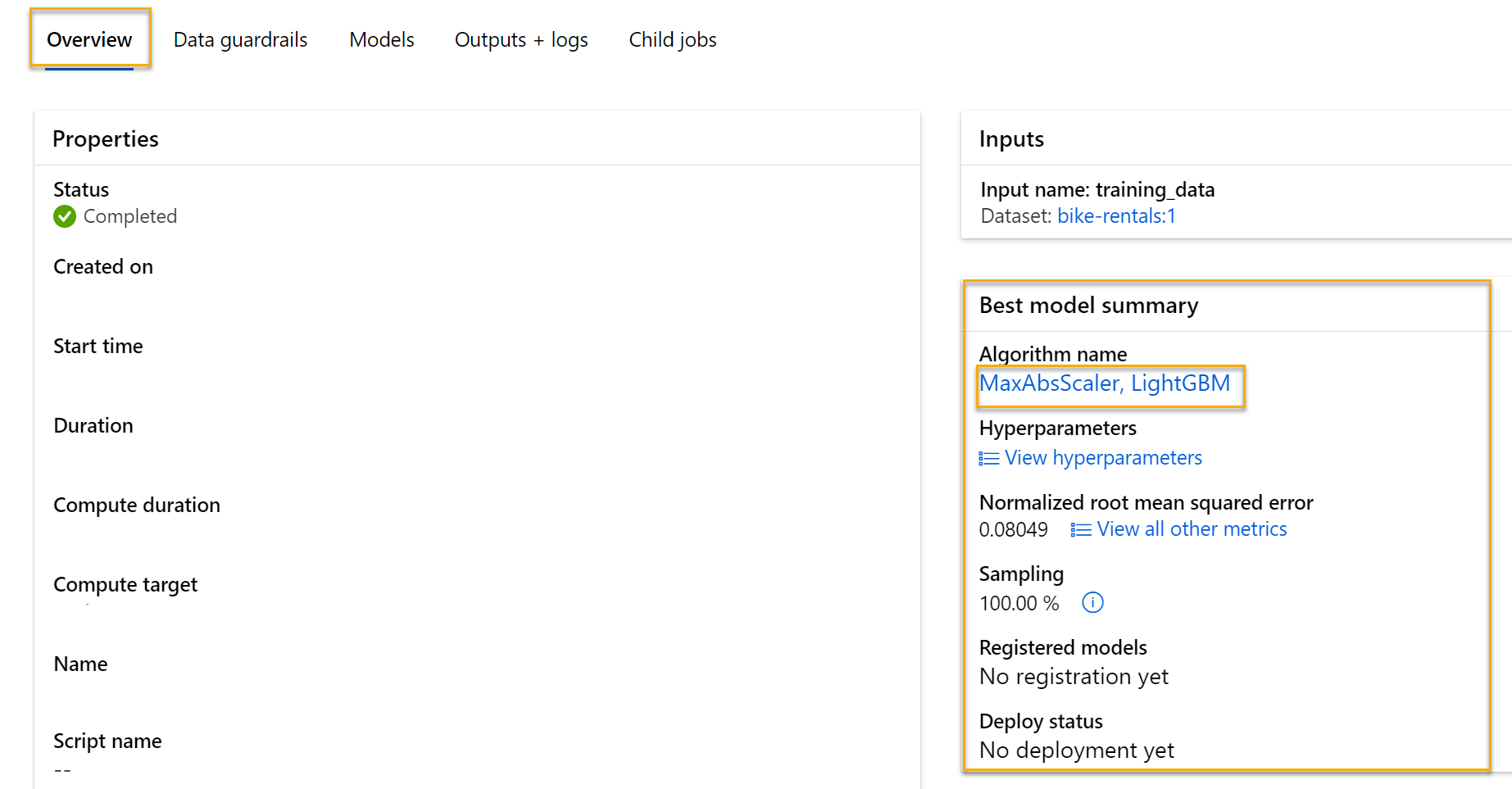
Nota: Es posible que vea un mensaje bajo el estado “Advertencia: Se alcanzó la puntuación de salida especificada por el usuario…”. Este es un comportamiento esperado. Continúe con la sección siguiente.
-
Seleccione el texto bajo Nombre del algoritmo para el mejor modelo a fin de ver sus detalles.
-
Seleccione la pestaña Métricas y seleccione los gráficos valores residuales y predicted_true si aún no están seleccionados.
Revise los gráficos en los que se muestran el rendimiento del modelo. En el gráfico de valores residuales se muestran los valores residuales (las diferencias entre los valores predichos y reales) como un histograma. El gráfico de predicted_true compara los valores previstos con los valores True.
Implementación y prueba del modelo
- En la pestaña Modelo del mejor modelo entrenado en el trabajo de aprendizaje automático automatizado, seleccione Implementar y use la opción Servicio web para implementar el modelo con la siguiente configuración:
- Nombre: predict-rentals
- Descripción: predicción de alquileres de bicicletas
- Tipo de proceso: instancia de Azure Container.
- Habilitar autenticación: seleccionada
- Espere a que se inicie la implementación; esto puede tardar unos segundos. El estado de implementación del punto de conexión predict-rentals se indicará en la parte principal de la página como En ejecución.
- Espere a que el estado de implementación cambie a Realizado correctamente. Esto podría tardar de 5 a 10 minutos.
Prueba del modelo implementado
Ahora puede probar el servicio implementado.
-
En Estudio de Azure Machine Learning, en el menú de la izquierda, seleccione Puntos de conexión y abra el punto de conexión predict-rentals en tiempo real.
-
En la página predict-rentals del punto de conexión en tiempo real, aparecerá la pestaña Prueba.
-
En el panel de datos de entrada para evaluar el punto de conexión, reemplace la plantilla JSON por los datos de entrada siguientes:
{ "Inputs": { "data": [ { "day": 1, "mnth": 1, "year": 2022, "season": 2, "holiday": 0, "weekday": 1, "workingday": 1, "weathersit": 2, "temp": 0.3, "atemp": 0.3, "hum": 0.3, "windspeed": 0.3 } ] }, "GlobalParameters": 1.0 } -
Haga clic en el botón Probar.
-
Revise los resultados de la prueba, que incluyen un número previsto de alquileres en función de las características de entrada similar a lo siguiente:
{ "Results": [ 444.27799000000000 ] }El panel de prueba tomó los datos de entrada y utilizó el modelo entrenado para devolver el número de alquileres previsto.
Revisemos lo que ha hecho. Ha usado un conjunto de datos históricos de alquiler de bicicletas para entrenar un modelo. El modelo predice el número de alquileres de bicicletas que se espera en un día determinado, en función de las características estacionales y meteorológicas.
Limpieza
El servicio web que se ha creado se hospeda en una instancia de Azure Container. Si no tiene previsto experimentar con él, debe eliminar el punto de conexión para evitar el uso innecesario de Azure.
-
En Azure Machine Learning Studio, en la pestaña Puntos de conexión, seleccione el punto de conexión predict-rentals. A continuación, seleccione Eliminar y confirme que quiere eliminar el punto de conexión.
Eliminar el proceso garantiza que no se cobren los recursos de proceso en la suscripción. Sin embargo, se le cobrará un importe reducido por el almacenamiento de datos, siempre que el área de trabajo de Azure Machine Learning exista en la suscripción. Si ha terminado de explorar Azure Machine Learning, puede eliminar el área de trabajo de Azure Machine Learning y los recursos asociados.
Para eliminar el área de trabajo:
- En Azure Portal, en la página Grupos de recursos, abra el grupo de recursos que haya especificado al crear el área de trabajo de Azure Machine Learning.
- Haga clic en Eliminar grupo de recursos, escriba el nombre del grupo de recursos para confirmar que quiere eliminarlo y seleccione Eliminar.