Erkunden der Objekterkennung
Hinweis: Um dieses Lab abzuschließen, benötigen Sie ein Azure-Abonnement, in dem Sie über Administratorzugriff verfügen.
Objekterkennung ist eine Form des maschinellen Sehens, bei der ein Machine Learning-Modell trainiert wird, um einzelne Instanzen von Objekten in einem Bild zu klassifizieren und einen Begrenzungsrahmen zu markieren, der ihre Position kennzeichnet. Sie können sich dies als eine Entwicklung von der Bildklassifizierung (bei der das Modell die Frage „Was zeigt dieses Bild?“ beantwortet) bis zum Erstellen von Lösungen vorstellen, bei denen wir das Modell Folgendes fragen können: „Welche Objekte befinden sich auf diesem Bild und wo befinden sie sich?“.
Beispielsweise könnte eine Initiative zur Straßenverkehrssicherheit feststellen, dass Fußgängerinnen und Radfahrerinnen die am stärksten gefährdeten Verkehrsteilnehmerinnen an Verkehrskreuzungen sind. Mithilfe von Kameras zur Überwachung von Kreuzungen könnten Bilder von Verkehrsteilnehmerinnen analysiert werden, um Fußgängerinnen und Radfahrerinnen zu erkennen und deren Anzahl zu überwachen oder sogar das Verhalten von Verkehrssignalen zu ändern.
Der Dienst Custom Vision in Microsoft Azure bietet eine cloudbasierte Lösung zur Erstellung und Veröffentlichung von benutzerdefinierten Objekterkennungsmodellen. In Azure können Sie den Custom Vision-Dienst verwenden, um ein Objekterkennungsmodell auf der Grundlage vorhandener Bilder zu trainieren. Die Erstellung einer Objekterkennungslösung erfolgt in zwei Schritten. Zunächst müssen Sie ein Modell trainieren, um die Position und Klasse der Objekte mithilfe von beschrifteten Bildern zu erkennen. Wenn das Modell dann trainiert ist, müssen Sie es als Dienst veröffentlichen, der von Anwendungen genutzt werden kann.
Um die Fähigkeiten des Custom Vision-Diensts zur Erkennung von Objekten in Bildern zu testen, verwenden wir eine einfache Befehlszeilenanwendung, die in der Cloud Shell ausgeführt wird. Die gleichen Prinzipien und Funktionen gelten auch für reale Lösungen, wie Websites oder mobile Apps.
Erstellen einer Azure KI Services-Ressource
Sie können den Custom Vision-Dienst verwenden, indem Sie entweder eine Ressource für Custom Vision oder eine für Azure KI Services erstellen.
Hinweis: Nicht jede Ressource ist in jeder Region verfügbar. Unabhängig davon, ob Sie eine Custom Vision- oder eine Azure KI Services-Ressource erstellen, können nur Ressourcen, die in bestimmten Regionen erstellt wurden, für den Zugriff auf Custom Vision-Dienste verwendet werden. Der Einfachheit halber wird in den folgenden Konfigurationsanweisungen eine Region für Sie vorausgewählt.
Erstellen Sie eine Ressource für Azure KI Services in Ihrem Azure-Abonnement.
-
Öffnen Sie auf einer anderen Browserregisterkarte das Azure-Portal unter https://portal.azure.com, und melden Sie sich mit Ihrem Microsoft-Konto an.
- Klicken Sie auf die Schaltfläche +Ressource erstellen und suchen Sie nach Azure KI Services. Wählen Sie Erstellen eines Azure KI Services-Plans aus. Sie werden zu einer Seite weitergeleitet, um eine Azure KI Services-Ressource zu erstellen. Konfigurieren Sie sie mit den folgenden Einstellungen:
- Abonnement: Ihr Azure-Abonnement.
- Ressourcengruppe: Wählen Sie eine Ressourcengruppe aus, oder erstellen Sie eine Ressourcengruppe mit einem eindeutigen Namen.
- Region: East US
- Name: Geben Sie einen eindeutigen Namen ein.
- Tarif: Standard S0.
- Durch Aktivieren dieses Kontrollkästchens bestätige ich, dass ich die folgenden Bedingungen gelesen und verstanden habe: Aktiviert.
-
Überprüfen und erstellen Sie die Ressource und warten Sie, bis die Bereitstellung abgeschlossen ist. Wechseln Sie dann zur bereitgestellten Ressource.
- Zeigen Sie die Seite Schlüssel und Endpunkt für Ihre Azure KI Services-Ressource an. Sie benötigen den Endpunkt und die Schlüssel, um von Clientanwendungen aus eine Verbindung herzustellen.
Erstellen eines Custom Vision-Projekts
Um ein Objekterkennungsmodell zu trainieren, müssen Sie ein Custom Vision-Projekt auf der Grundlage Ihrer Trainingsressource erstellen. Dazu verwenden Sie das Custom Vision-Portal.
-
Öffnen Sie auf einer neuen Browserregisterkarte das Custom Vision-Portal unter https://customvision.ai, und melden Sie sich mit dem Microsoft-Konto an, das Ihrem Azure-Abonnement zugeordnet ist.
- Erstellen Sie ein neues Projekt mit den folgenden Einstellungen:
- Name: Verkehrssicherheit
- Beschreibung: Objekterkennung für Straßenverkehrssicherheit
- Ressource: Die Ressource, die Sie zuvor erstellt haben.
- Projekttypen: Objekterkennung.
- Domänen: Allgemein [A1]
- Warten Sie, bis das Projekt erstellt und im Browser geöffnet wurde.
Hinzufügen und Markieren von Bildern
Um ein Objekterkennungsmodell zu trainieren, müssen Sie Bilder hochladen, die die Klassen enthalten, die das Modell identifizieren soll, und sie mit Tags versehen, um Begrenzungsrahmen für jede Objektinstanz anzugeben.
-
Laden Sie die Trainingsbilder von https://aka.ms/traffic-images herunter, und extrahieren Sie sie. Der extrahierte Ordner enthält eine Sammlung von Bildern von Radfahrerinnen und Fußgängerinnen.
-
Wählen Sie im Custom Vision-Portal in Ihrem Objekterkennungsprojekt Verkehrssicherheit die Option Bilder hinzufügen aus, und laden Sie alle Bilder aus dem extrahierten Ordner hoch.
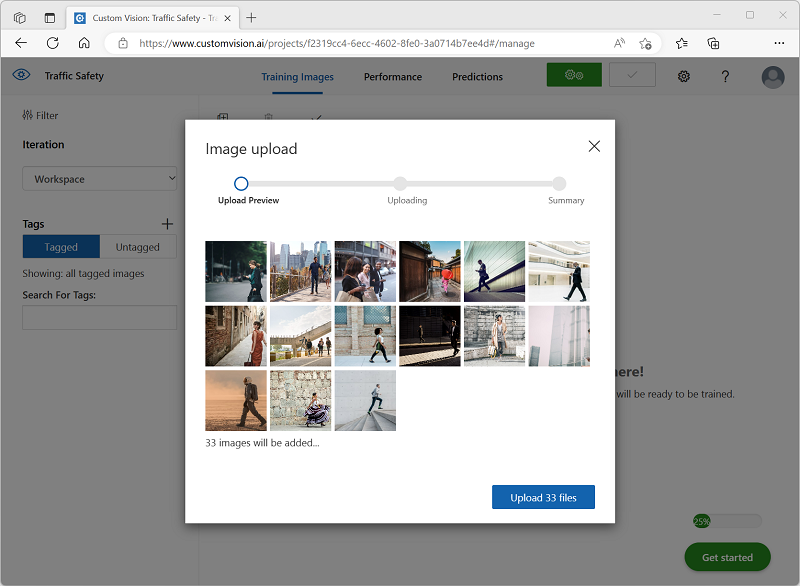
-
Nachdem die Bilder hochgeladen wurden, wählen Sie das erste Bild aus, um es zu öffnen.
-
Zeigen Sie mit dem Mauszeiger auf ein beliebiges Objekt (Radfahrerin oder Fußgängerin) im Bild, bis ein automatisch erkannter Bereich angezeigt wird. Wählen Sie dann das Objekt aus, und ändern Sie gegebenenfalls die Größe des Bereichs, um es zu umranden. Alternativ können Sie auch einfach einen Rahmen um das Objekt herum ziehen, um einen Bereich zu erstellen.
Wenn das Objekt innerhalb des rechteckigen Bereichs eng ausgewählt ist, geben Sie das entsprechende Tag für das Objekt (Cyclist oder Pedestrian) ein, und verwenden Sie die Schaltfläche Tagregion ( + ), um das Tag dem Projekt hinzuzufügen.
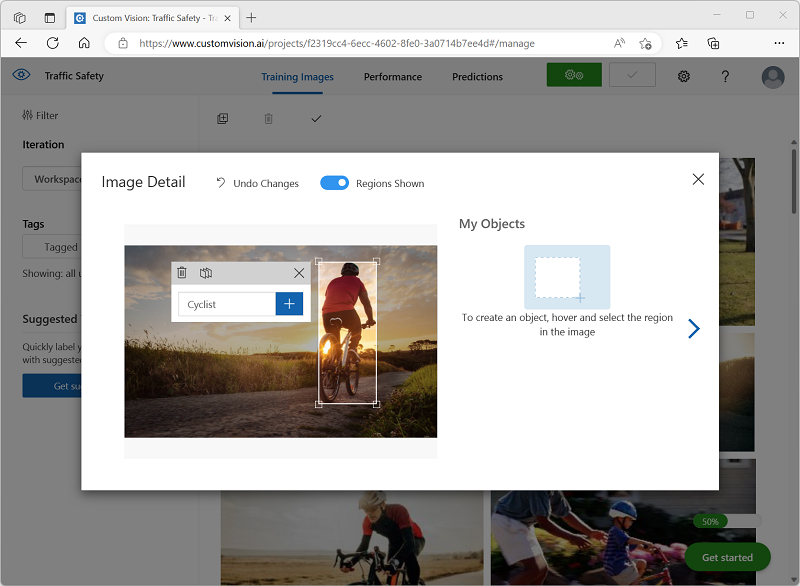
-
Verwenden Sie den Link Weiter ( (>) auf der rechten Seite, um zum nächsten Bild zu wechseln und dessen Objekte zu taggen. Gehen Sie dann die gesamte Bildersammlung durch, und taggen Sie alle Radfahrerinnen und Fußgängerinnen.
Beachten Sie beim Taggen der Bilder Folgendes:
- Einige Bilder enthalten mehrere Objekte, möglicherweise unterschiedlicher Arten. Taggen Sie alle, auch wenn sie sich überlappen.
- Nachdem ein Tag einmal eingegeben wurde, können Sie es beim Taggen neuer Objekte aus der Liste auswählen.
- Sie können in den Bildern zurück und vorwärts navigieren, um Tags anzupassen.
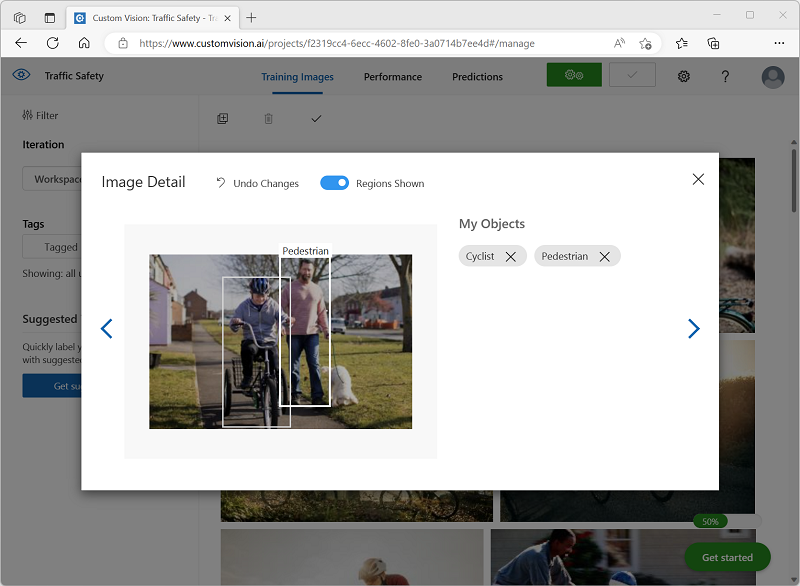
-
Wenn Sie mit dem Markieren des letzten Bilds fertig sind, schließen Sie den Editor für Bilddetails und wählen auf der Seite Training Images (Trainingsbilder) unter Tags die Option Tagged (Markiert) aus, um alle markierten Bilder anzuzeigen:
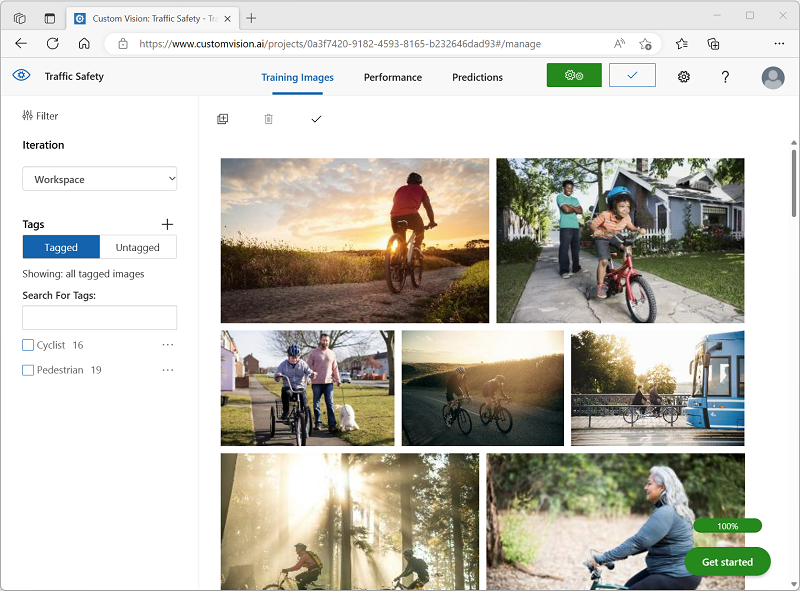
Trainieren und Testen eines Modells
Nachdem Sie nun die Bilder in Ihrem Projekt markiert haben, können Sie ein Modell trainieren.
-
Klicken Sie im Custom Vision-Projekt auf Train (Trainieren), um ein Objekterkennungsmodell anhand der markierten Bilder zu trainieren. Wählen Sie die Option Quick Training (Schnelles Training) aus.
Hinweis: Der Trainingsvorgang kann einige Minuten dauern. Während Sie warten, sehen Sie sich die Videoanalyse für Smart Citys an. Dort geht es um ein echtes Projekt, bei dem maschinelles Sehen in einer Initiative zur Verbesserung der Straßenverkehrssicherheit verwendet wird.
-
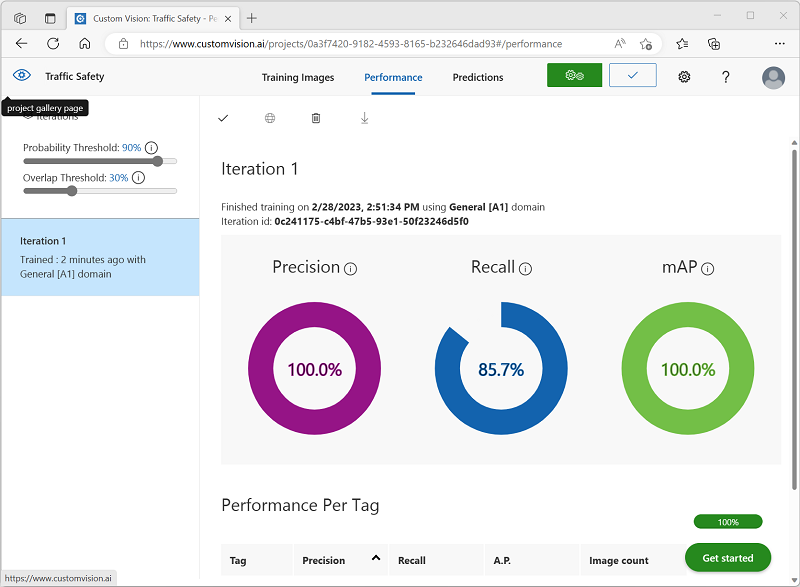
Wenn das Training abgeschlossen ist, überprüfen Sie die Leistungsmetriken Precision (Genauigkeit), Recall (Abruf) und mAP. Diese messen die Vorhersagequalität des Objekterkennungsmodells und sollten alle einigermaßen hoch sein.
-
Passen Sie den Wahrscheinlichkeitsschwellenwert links an. Erhöhen Sie ihn von 50 % auf 90 %, und beobachten Sie die Auswirkung auf die Leistungsmetriken. Diese Einstellung bestimmt den Wahrscheinlichkeitswert, den jede Tagauswertung erfüllen oder überschreiten muss, um als Vorhersage gezählt zu werden.
-
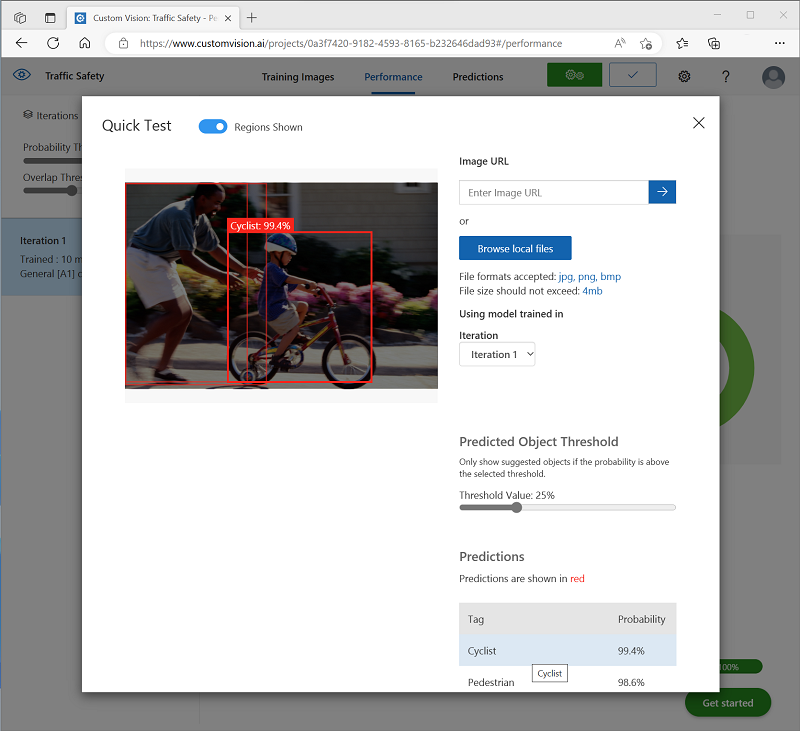
Klicken Sie oben rechts auf der Seite auf Schnelltest, geben Sie dann in das Feld Bild-URL die URL
https://aka.ms/pedestrian-cyclistein, und sehen Sie sich die Ergebnisse an.Im Bereich auf der rechten Seite wird unter Vorhersagen jedes erkannte Objekt mit seinem Tag und seiner Wahrscheinlichkeit aufgeführt. Wählen Sie jedes Objekt aus, um zu sehen, wie es im Bild hervorgehoben wird.
Die vorhergesagten Objekte sind möglicherweise nicht alle richtig, denn schließlich haben Radfahrerinnen und Fußgängerinnen viele gemeinsame Merkmale. Die Vorhersagen, für die das Modell am zuversichtlichsten ist, weisen die höchsten Wahrscheinlichkeitswerte auf. Verwenden Sie den Schieberegler Schwellenwert, um Objekte mit geringer Wahrscheinlichkeit zu entfernen. Sie sollten in der Lage sein, einen Punkt zu finden, an dem nur richtige Vorhersagen enthalten sind (wahrscheinlich bei ca. 85 bis 90 %).
-
Schließen Sie dann das Fenster Quick Test (Schnelltest).
Veröffentlichen des Objekterkennungsmodells
Jetzt können Sie Ihr trainiertes Modell veröffentlichen und in einer Clientanwendung verwenden.
- Klicken Sie auf 🗸 Publish (Veröffentlichen), um das trainierte Modell mit den folgenden Einstellungen zu veröffentlichen:
- Modellname: traffic-safety
- Vorhersageressource: Die Ressource, die Sie zuvor erstellt haben.
-
Nach der Veröffentlichung klicken Sie auf das Symbol für die Vorhersage-URL (🌐), um die für die Verwendung des veröffentlichten Modells erforderlichen Informationen anzuzeigen.
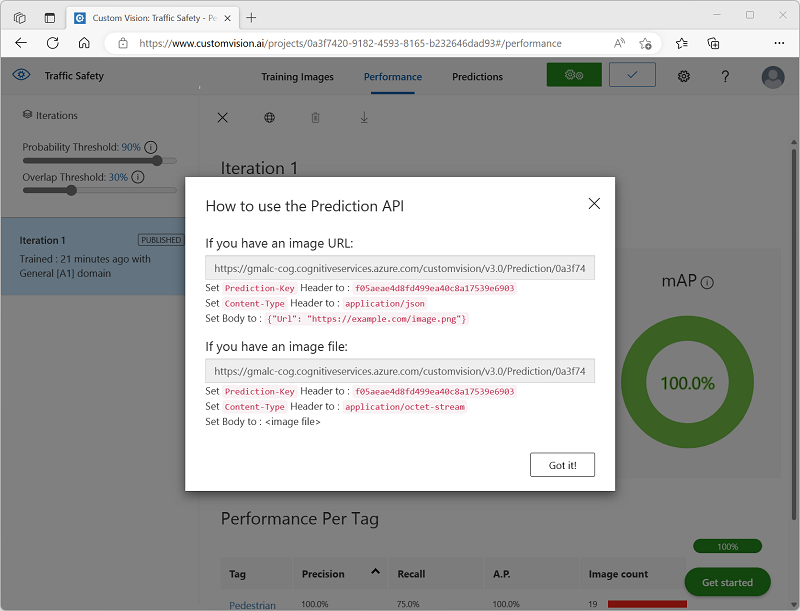
Später benötigen Sie die entsprechenden Werte für die URL und den Vorhersageschlüssel, um eine Vorhersage von einer Bild-URL zu erhalten, lassen Sie also dieses Dialogfeld geöffnet, und fahren Sie mit der nächsten Aufgabe fort.
Vorbereiten einer Clientanwendung
Um die Funktionen des Custom Vision-Diensts zu testen, verwenden wir eine einfache Befehlszeilenanwendung, die in Cloud Shell in Azure ausgeführt wird.
-
Wechseln Sie zurück zur Browserregisterkarte mit dem Azure-Portal, und wählen Sie oben auf der Seite rechts neben dem Suchfeld die Schaltfläche Cloud Shell ( [>_] ) aus. Dadurch wird am unteren Rand des Portals ein Cloud Shell-Bereich geöffnet.
Wenn Sie die Cloud Shell zum ersten Mal öffnen, werden Sie möglicherweise aufgefordert, die Art der Shell zu wählen, die Sie verwenden möchten (Bash oder PowerShell). Wählen Sie in diesem Fall PowerShell aus.
Wenn Sie aufgefordert werden, Speicher für Ihre Cloud Shell zu erstellen, achten Sie darauf, dass Ihr Abonnement ausgewählt ist, und wählen Sie Speicher erstellen aus. Warten Sie dann etwa eine Minute, bis der Speicher erstellt ist.
Wenn die Cloud Shell bereit ist, sollte sie in etwa wie folgt aussehen:
Hinweis: Vergewissern Sie sich, dass der oben links im Cloud Shell-Bereich angezeigte Shelltyp PowerShell lautet. Wenn Bash angezeigt wird, wechseln Sie über das Dropdownmenü zu PowerShell.
Beachten Sie, dass Sie die Größe der Cloud Shell durch Ziehen der Trennzeichenleiste oben im Bereich ändern können, oder den Bereich mithilfe der Symbole — , ◻ und X oben rechts minimieren, maximieren und schließen können. Weitere Informationen zur Verwendung von Azure Cloud Shell finden Sie in der Azure Cloud Shell-Dokumentation.
-
Geben Sie in der Befehlsshell die folgenden Befehle ein, um die Dateien für diese Übung herunterzuladen, und speichern Sie sie in einem Ordner namens ai-900 (nachdem Sie diesen Ordner entfernt haben, falls er bereits vorhanden ist).
rm -r ai-900 -f git clone https://github.com/MicrosoftLearning/AI-900-AIFundamentals ai-900 -
Nachdem die Dateien heruntergeladen wurden, geben Sie die folgenden Befehle ein, um zum Verzeichnis ai-900 zu wechseln und die Codedatei für diese Übung zu bearbeiten:
cd ai-900 code detect-objects.ps1Dadurch öffnet sich ein Editor wie in der Abbildung unten:
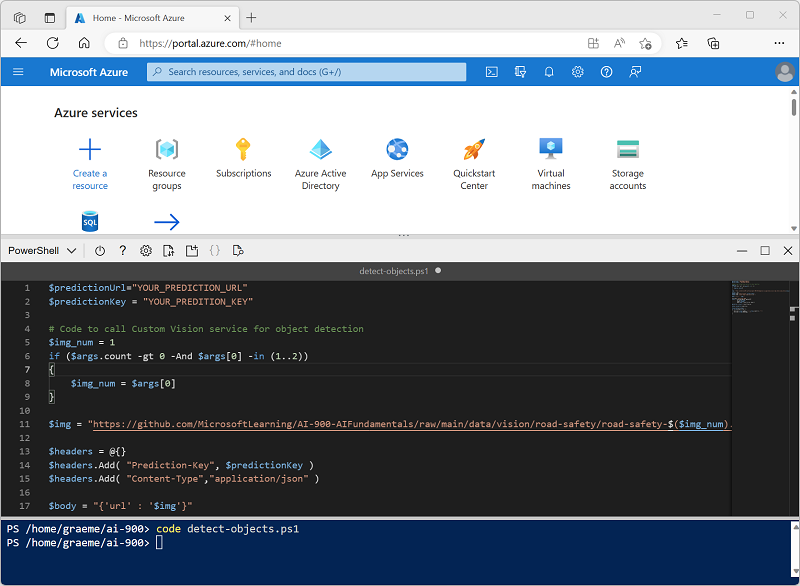
Tipp: Sie können die Trennlinie zwischen der Cloud Shell-Befehlszeile und dem Code-Editor verschieben, um die Größe der Bereiche zu ändern.
-
Machen Sie sich nicht zu viele Gedanken über die Details des Codes. Wichtig ist, dass er mit Code beginnt, um die Vorhersage-URL und den Schlüssel für Ihr Custom Vision-Modell anzugeben. Sie müssen diese aktualisieren, damit der restliche Code Ihr Modell verwendet.
Rufen Sie die Vorhersage-URL und den Vorhersageschlüssel aus dem Dialogfeld ab, das Sie in der Browserregisterkarte für Ihr Custom Vision-Projekt geöffnet haben. Sie benötigen die zu verwendenden Versionen , wenn Sie über eine Bild-URL verfügen.
Verwenden Sie diese Werte, um die Platzhalter YOUR_PREDICTION_URL und YOUR_PREDICTION_KEY in der Codedatei zu ersetzen.
Nach dem Einfügen der Werte für die Vorhersage-URL und den Vorhersageschlüssel sollten die ersten beiden Codezeilen in etwa wie folgt aussehen:
$predictionUrl="https..." $predictionKey ="1a2b3c4d5e6f7g8h9i0j...." -
Nachdem Sie die Änderungen an den Variablen im Code vorgenommen haben, drücken Sie STRG+S, um die Datei zu speichern. Drücken Sie anschließend STRG+Q, um den Code-Editor zu schließen.
Testen der Clientanwendung
Jetzt können Sie die Beispielclientanwendung verwenden, um Radfahrerinnen und Fußgängerinnen in Bildern zu erkennen.
-
Geben Sie im PowerShell-Bereich den folgenden Befehl ein, um den Code auszuführen:
./detect-objects.ps1 1Dieser Code verwendet Ihr Modell, um Objekte im folgenden Bild zu erkennen:

-
Überprüfen Sie die Vorhersage, die alle erkannten Objekte mit einer Wahrscheinlichkeit von 90 % oder mehr zusammen mit den Koordinaten eines Begrenzungsrahmens um ihre Position auflistet.
-
Versuchen wir es nun mit einem anderen Bild. Führen Sie den folgenden Befehl aus:
./detect-objects.ps1 2Dieses Mal wird das folgende Bild analysiert:

Hoffentlich hat Ihr Objekterkennungsmodell gut funktioniert, um Fußgängerinnen und Radfahrerinnen in den Testbildern zu erkennen.