Untersuchen der Klassifizierung mit dem Azure Machine Learning-Designer
Hinweis: Um dieses Lab abzuschließen, benötigen Sie ein Azure-Abonnement, in dem Sie über Administratorzugriff verfügen.
Erstellen eines Azure Machine Learning-Arbeitsbereichs
-
Melden Sie sich mit Ihren Microsoft-Anmeldeinformationen beim Azure-Portal an.
- Klicken Sie auf + Ressource erstellen, suchen Sie nach Machine Learning, und erstellen Sie eine neue Azure Machine Learning-Ressource mit einem Azure Machine Learning-Plan. Verwenden Sie folgende Einstellungen:
- Abonnement: Ihr Azure-Abonnement.
- Ressourcengruppe: Erstellen Sie eine Ressourcengruppe, oder wählen Sie eine Ressourcengruppe aus.
- Arbeitsbereichsname: Geben Sie einen eindeutigen Namen für den Arbeitsbereich ein.
- Region: Wählen Sie die geografisch nächstgelegene Region aus.
- Speicherkonto: Für Ihren Arbeitsbereich wird standardmäßig ein neues Speicherkonto erstellt.
- Schlüsseltresor: Für Ihren Arbeitsbereich wird standardmäßig ein neuer Schlüsseltresor erstellt.
- Application Insights: Für Ihren Arbeitsbereich wird standardmäßig eine neue Application Insights-Ressource erstellt.
- Containerregistrierung: Keine (wird automatisch erstellt, wenn Sie das erste Mal ein Modell in einem Container bereitstellen)
-
Klicken Sie aufÜberprüfen + erstellen und dann auf Erstellen. Warten Sie, bis Ihr Arbeitsbereich erstellt wurde (dies kann einige Minuten dauern), und wechseln Sie dann zur bereitgestellten Ressource.
-
Wählen Sie Studio starten aus (oder öffnen Sie eine neue Browserregisterkarte. Navigieren Sie dann zu https://ml.azure.com, und melden Sie sich mit Ihrem Microsoft-Konto bei Azure Machine Learning Studio an).
- In Azure Machine Learning Studio sollte Ihr neu erstellter Arbeitsbereich angezeigt werden. Wenn dies nicht der Fall ist, wählen Sie im linken Menü Ihr Azure-Verzeichnis aus. Wählen Sie dann im neuen Menü auf der linken Seite Arbeitsbereiche aus, wo alle Arbeitsbereiche aufgeführt sind, die Ihrem Verzeichnis zugeordnet sind, und wählen Sie den Arbeitsbereich aus, den Sie für diese Übung erstellt haben.
Hinweis: Dieses Modul ist eines von vielen, in denen ein Azure Machine Learning-Arbeitsbereich verwendet wird (einschließlich der anderen Module im Lernpfad Microsoft Azure KI-Grundlagen: Erkunden visueller Tools für maschinelles Lernen). Wenn Sie Ihr eigenes Azure-Abonnement verwenden, sollten Sie den Arbeitsbereich einmal erstellen und in anderen Modulen wiederverwenden. Ihrem Azure-Abonnement wird eine kleine Menge an Datenspeicher in Rechnung gestellt, solange der Azure Machine Learning-Arbeitsbereich in Ihrem Abonnement vorhanden ist. Daher wird empfohlen, den Azure Machine Learning-Arbeitsbereich zu löschen, wenn er nicht mehr benötigt wird.
Erstellen von Computeressourcen
-
Wählen Sie in Azure Machine Learning Studio das Symbol ≡ aus (ein Menüsymbol, dass wie drei übereinander angeordnete Linien aussieht), um die verschiedenen Seiten auf der Benutzeroberfläche anzuzeigen (möglicherweise müssen Sie die Größe des Bildschirms maximieren). Sie können diese Seiten im linken Bereich verwenden, um die Ressourcen in Ihrem Arbeitsbereich zu verwalten. Wählen die Seite Compute (unter Verwalten) aus.
-
Wählen Sie auf der Seite Compute die Registerkarte Computecluster aus, und fügen Sie einen neuen Computecluster mit den folgenden Einstellungen hinzu. Sie verwenden diesen zum Trainieren eines Machine Learning-Modells:
- Standort: Wählen Sie denselben Standort wie für Ihren Arbeitsbereich aus. Wenn dieser Standort nicht aufgeführt wird, wählen Sie den nächstgelegenen Standort aus.
- VM-Dienstebene: Dediziert.
- VM-Typ: CPU
- VM-Größe:
- Klicken Sie auf Aus allen Optionen auswählen.
- Suchen Sie Standard_DS11_v2, und wählen Sie den Eintrag aus.
- Wählen Sie Weiter aus.
- Computename: Geben Sie einen eindeutigen Namen ein.
- Mindestanzahl von Knoten: 0
- Maximale Knotenanzahl: 2
- Leerlauf in Sekunden vor dem Herunterskalieren: 120
- SSH-Zugriff aktivieren: Deaktiviert.
- Klicken Sie auf Erstellen.
Hinweis: Compute-Instanzen und -cluster basieren auf Azure VM-Standardimages. Für dieses Modul wird das Image Standard_DS11_v2 empfohlen, um ein optimales Gleichgewicht zwischen Kosten und Leistung zu erzielen. Wenn Ihr Abonnement über ein Kontingent verfügt, das dieses Image nicht enthält, wählen Sie ein alternatives Image aus. Beachten Sie jedoch, dass ein größeres Image höhere Kosten verursachen kann und ein kleineres Image möglicherweise nicht ausreicht, um die Aufgaben auszuführen. Bitten Sie alternativ Ihren Azure-Administrator, Ihr Kontingent zu erhöhen.
Die Erstellung des Computeclusters nimmt einige Zeit in Anspruch. Sie können mit dem nächsten Schritt fortfahren, während Sie warten.
Erstellen eines Datasets
-
Erweitern Sie in Azure Machine Learning Studio den linken Bereich, indem Sie das Menüsymbol oben links auf dem Bildschirm auswählen. Wählen Sie die Seite Daten aus (unter Ressourcen). Die Seite „Daten“ enthält bestimmte Datendateien oder Tabellen, mit denen Sie in Azure Machine Learning arbeiten möchten. Sie können auch auf dieser Seite Datasets erstellen.
- Wählen Sie auf der Seite Daten auf der Registerkarte Datenressourcen die Option +Erstellen aus. Konfigurieren Sie dann eine Datenressource mit den folgenden Einstellungen:
- Datentyp:
- Name: diabetes-data
- Beschreibung: Diabetesdaten
- Datasettyp: Tabellarisch
- Datenquelle: Aus Webdateien
- Web-URL:
- Web-URL: https://aka.ms/diabetes-data
- Skip data validation (Datenüberprüfung überspringen): Nicht auswählen
- Einstellungen:
- Dateiformat: Zeichengetrennt
- Trennzeichen: Komma
- Codierung: UTF-8
- Spaltenüberschriften: Nur erste Datei enthält Header
- Zeilen überspringen: Keine
- Dataset contains multi-line data (Dataset enthält mehrzeilige Daten): Nicht auswählen
- Schema:
- Alle Spalten einschließen außer Pfad
- Überprüfen der automatisch erkannten Typen
- Überprüfung
- Klicken Sie auf Erstellen.
- Datentyp:
- Nachdem das Dataset erstellt wurde, öffnen Sie es, und zeigen Sie die Seite Erkunden an, um eine Stichprobe der Daten anzuzeigen. Diese Daten stellen Details von Patienten dar, die auf Diabetes getestet wurden.
Erstellen einer Pipeline in Designer und Laden der Daten im Canvas-Panel
Für den Einstieg in den Azure Machine Learning-Designer müssen Sie zunächst eine Pipeline erstellen und das Dataset hinzufügen, mit dem Sie arbeiten möchten.
-
Wählen Sie in Azure Machine Learning Studio im linken Bereich das Element Designer (unter Erstellung) aus, und wählen Sie dann + aus, um eine neue Pipeline zu erstellen.
-
Ändern Sie den Namen des Entwurfs von Pipeline-Created-on-Datum in Diabetes Training.
-
Klicken Sie dann im Projekt neben dem Pipelinenamen auf das Pfeilsymbol auf der linken Seite, um den Bereich zu erweitern, sofern er nicht bereits erweitert ist. Der Bereich sollte standardmäßig im Bereich Ressourcenbibliothek geöffnet werden. Dies wird durch das Büchersymbol am oberen Rand des Bereichs gekennzeichnet. Beachten Sie, dass eine Suchleiste für die Suche nach Objekten vorhanden ist. Beachten Sie die beiden Schaltflächen Daten und Komponente.
-
Wählen Sie Daten aus. Suchen Sie den Datensatz diabetes-data und platzieren Sie ihn auf deM Canvas.
-
Klicken Sie mit der rechten Maustaste (Ctrl + Klick auf dem Mac) auf das Dataset diabetes-data im Canvas-Panel, und wählen Sie dann Datenvorschau aus.
-
Überprüfen Sie das Schema der Daten auf der Registerkarte Profil und beachten Sie, dass Sie die Verteilungen der verschiedenen Spalten als Histogramme angezeigt bekommen.
-
Scrollen Sie nach unten, und wählen Sie die Überschrift der Spalte Diabetic aus. Beachten Sie, dass sie zwei Werte enthält 0 und 1. Diese Werte stellen die beiden möglichen Klassen für die Bezeichnung dar, die Ihr Modell vorhersagen soll. Dabei bedeutet der Wert 0, dass der Patient keinen Diabetes hat, und der Wert 1, dass es sich um einen Diabetiker handelt.
-
Scrollen Sie zurück nach oben, und überprüfen Sie die anderen Spalten, die die zum Vorhersagen der Bezeichnung verwendeten Features darstellen. Beachten Sie, dass die meisten dieser Spalten numerisch sind, aber jedes Feature eine eigene Skalierung aufweist. Die Werte für Age liegen z. B. zwischen 21 und 77, während die Werte von DiabetesPedigree zwischen 0,078 und 2,3016 liegen. Beim Trainieren eines Machine Learning-Modells ist es manchmal möglich, dass größere Werte die resultierende Vorhersagefunktion dominieren und dadurch der Einfluss von Features auf eine kleinere Skalierung verringert wird. Data Scientists mindern diese mögliche Abweichung in der Regel, indem sie numerische Spalten normalisieren, damit sie eine ähnliche Skalierung aufweisen.
-
Schließen Sie die Registerkarte DataOutput, damit das Dataset wie folgt im Canvas-Panel angezeigt wird:
Transformationen hinzufügen
Bevor Sie ein Modell trainieren können, müssen Sie in der Regel einige Vorverarbeitungstransformationen auf die Daten anwenden.
-
Wählen Sie links im Bereich Ressourcenbibliothek die Option Komponente aus. Diese enthält verschiedenste Module, die Sie für Datentransformationen und Modelltrainings verwenden können. Für die schnelle Suche nach Modulen können Sie auch die Suchleiste verwenden.
-
Suchen Sie nach dem Modul Spalten im Dataset auswählen, und platzieren Sie es im Canvas-Panel unterhalb des Datasets diabetes-data. Verbinden Sie anschließend den Ausgang vom unteren Rand des Datasets diabetes-data mit dem Eingang am oberen Rand des Moduls Spalten im Dataset auswählen.
-
Doppelklicken Sie auf das Modul Spalten im Dataset auswählen, um rechts auf einen Bereich mit Einstellungen zuzugreifen. Wählen Sie Spalte bearbeiten aus. Wählen Sie dann im Fenster Spalten auswählen die Optionen Nach Name und Alle hinzufügen aus, um die Spalten hinzuzufügen. Entfernen Sie dann PatientID, und klicken Sie auf Speichern.
-
Suchen Sie nach dem Modul Daten normalisieren, und platzieren Sie es im Canvas-Panel unterhalb des Moduls Spalten im Dataset auswählen. Verbinden Sie anschließend den Ausgang vom unteren Rand des Moduls Spalten im Dataset auswählen mit dem Eingang am oberen Rand des Moduls Daten normalisieren, wie im Folgenden gezeigt:
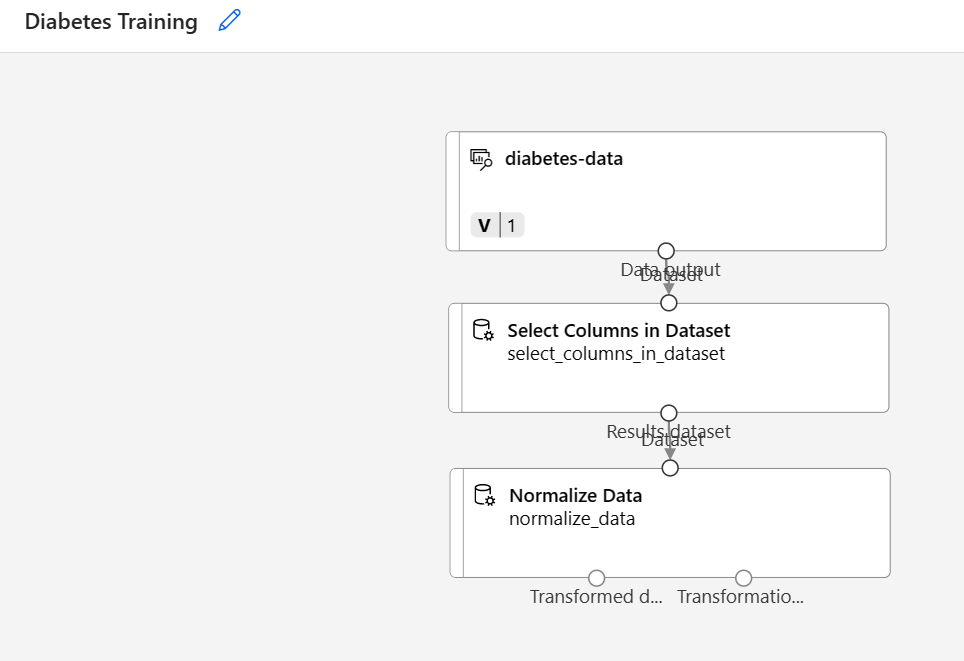
-
Doppelklicken Sie auf das Modul Daten normalisieren, um dessen Einstellungen anzuzeigen. Beachten Sie, dass Sie die Transformationsmethode und die zu transformierenden Spalten angeben müssen.
-
Legen Sie die Transformationsmethode auf MinMax und Use 0 for constant columns when checked (Bei der Überprüfung 0 für konstante Spalten verwenden) auf TRUE fest. Bearbeiten Sie die zu transformierenden Spalten mit Spalten bearbeiten. Wählen Sie Spalten mit Regeln aus, und kopieren Sie die folgende Liste unter „Spaltennamen einschließen“, und fügen Sie sie ein:
Pregnancies, PlasmaGlucose, DiastolicBloodPressure, TricepsThickness, SerumInsulin, BMI, DiabetesPedigree, Age
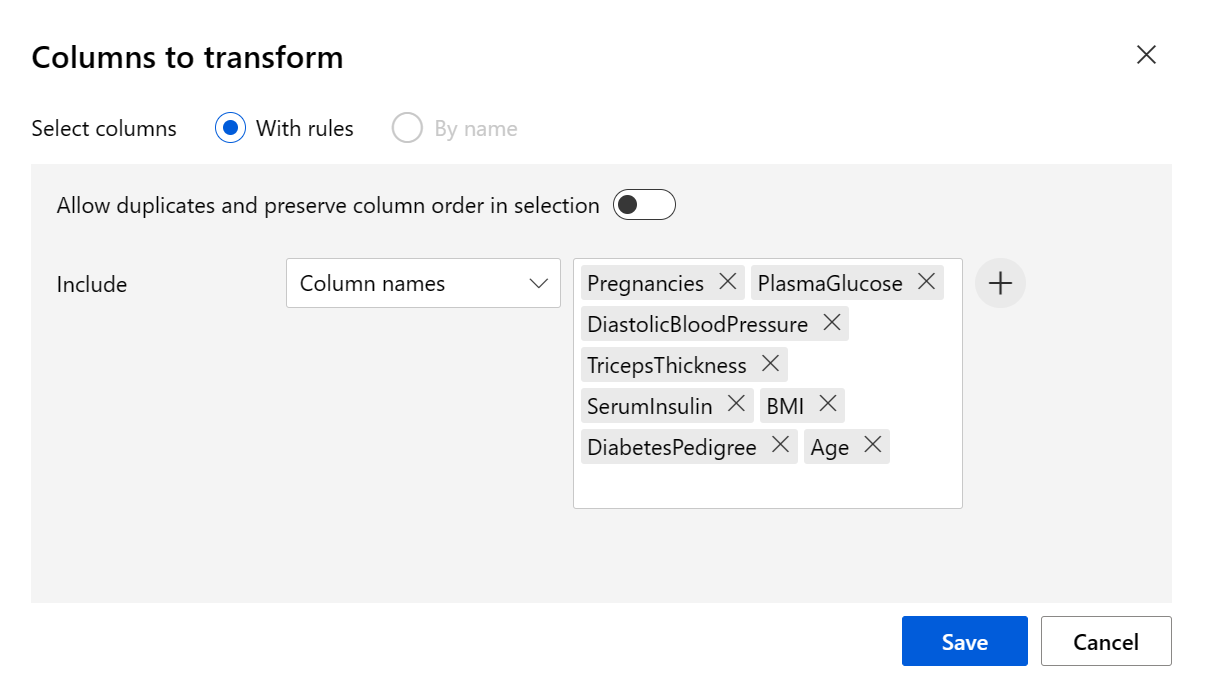
Klicken Sie auf Speichern, und schließen Sie das Auswahlfeld.
Bei der Datentransformation werden die numerischen Spalten normalisiert, um ihre Skalierung anzugleichen. Dadurch soll verhindert werden, dass Spalten mit großen Werten das Modelltraining dominieren. Sie würden normalerweise eine ganze Reihe von Transformationen wie diese zur Vorverarbeitung anwenden, um Ihre Daten für das Training vorzubereiten, aber wir halten diese Übung einfach.
Führen Sie die Pipeline aus.
Zum Anwenden der Datentransformationen müssen Sie die Pipeline als Experiment ausführen.
-
Wählen Sie oben auf der Seite Konfigurieren und Übermitteln aus, um das Dialogfeld Pipelineauftrag einrichten zu öffnen.
-
Wählen Sie auf der Seite Grundlagen die Option Neu erstellen aus, und legen Sie den Namen des Experiments auf mslearn-diabetes-training fest. Wählen Sie dann Weiter aus.
-
Wählen Sie auf der Seite Eingaben und Ausgaben die Option Weiter aus, ohne Änderungen vorzunehmen.
-
Auf der Seite Laufzeiteinstellungen wird ein Fehler angezeigt, da Sie nicht über eine Standardcomputeressource für die Ausführung der Pipeline verfügen. Wählen Sie in der Dropdownliste Computetyp auswählen die Option Computecluster und in der Dropdownliste Azure ML Computecluster auswählen Ihren kürzlich erstellten Computecluster aus.
-
Wählen Sie Überprüfen und übermitteln aus, um den Pipelineauftrag zu überprüfen, und wählen Sie dann Übermitteln aus, um die Trainingspipeline auszuführen.
-
Warten Sie einige Minuten, bis die Ausführung abgeschlossen ist. Sie können den Status des Auftrags überprüfen, indem Sie unter Ressourcen die Option Aufträge auswählen. Wählen Sie dort das Experiment mslearn-diabetes-training und dann den Auftrag Diabetes Training aus.
Anzeigen der transformierten Daten
Wenn die Ausführung abgeschlossen ist, wird das Dataset nun für das Modelltraining vorbereitet.
-
Klicken Sie mit der rechten Maustaste (Ctrl + Klick auf dem Mac) auf das Modul Daten normalisieren im Canvas-Panel, und wählen Sie Datenvorschau aus. Wählen Sie Transformiertes Dataset.
-
Zeigen Sie die Daten an, und beachten Sie, dass die ausgewählten numerischen Spalten auf eine gemeinsame Skalierung normalisiert wurden.
-
Schließen Sie die Visualisierung der Ergebnisse der Datennormalisierung. Kehren Sie zur vorherigen Registerkarte zurück.
Nachdem Sie die Daten mithilfe von Datentransformationen vorbereitet haben, können Sie sie zum Trainieren eines Machine Learning-Modells verwenden.
Hinzufügen von Trainingsmodulen
Es ist üblich, das Modell mit einer Teilmenge der Daten zu trainieren und einige Daten zurückzuhalten, mit denen das trainierte Modell anschließend getestet werden kann. Dadurch können Sie die vom Modell vorhergesagten Bezeichnungen mit den tatsächlichen bekannten Bezeichnungen im ursprünglichen Dataset vergleichen.
In dieser Übung werden Sie die Schritte zur Erweiterung der Pipeline Diabetes Training wie hier gezeigt durcharbeiten:
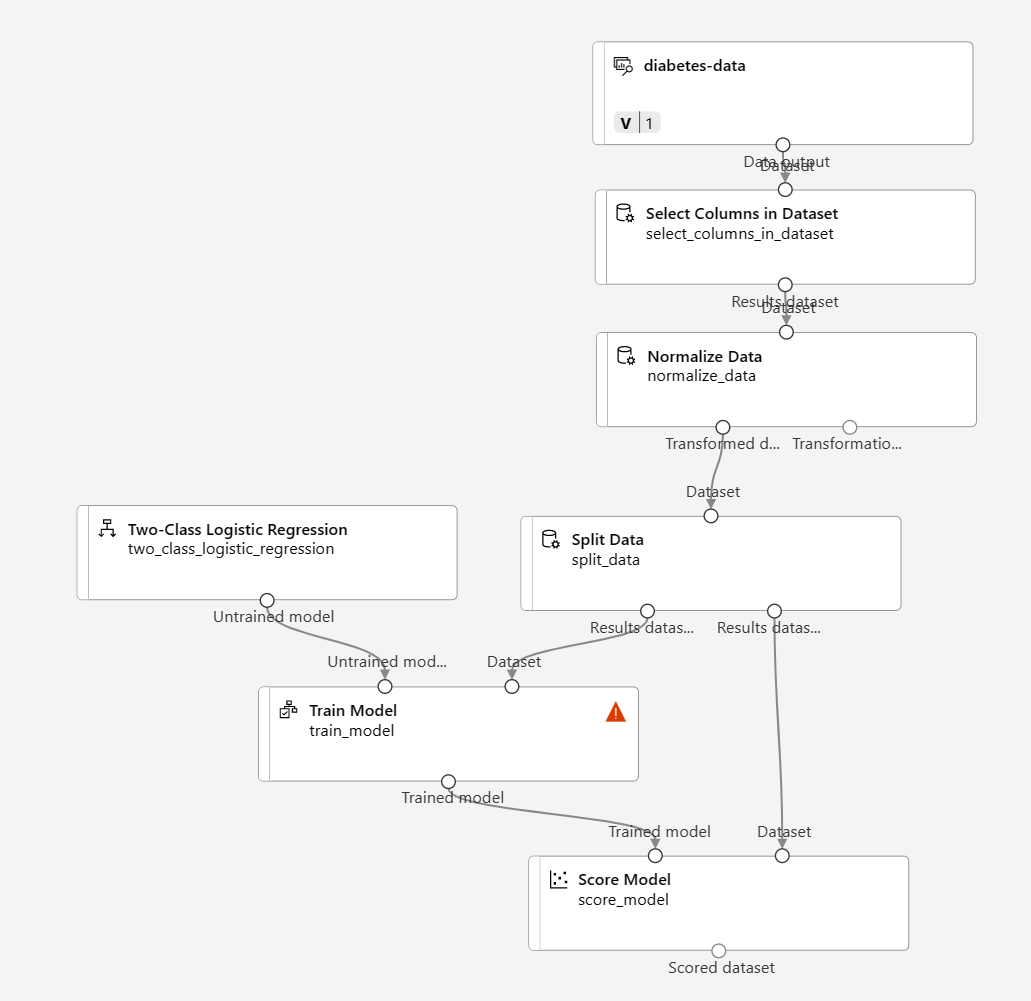
Führen Sie die folgenden Schritte aus, und verwenden Sie die obige Abbildung als Referenz für das Hinzufügen und Konfigurieren der erforderlichen Module.
-
Kehren Sie zur Seite Designer zurück, und wählen Sie die Pipeline Diabetes Training aus.
-
Suchen Sie im Bereich Objektbibliothek auf der linken Seite unter Komponente nach einem Modul Daten aufteilen, und platzieren Sie es auf der Canvas unter dem Modul Daten normalisieren. Verbinden Sie dann die (linke) Ausgabe Transformiertes Dataset des Moduls Daten normalisieren mit der Eingabe des Moduls Daten teilen.
Tipp: Für die schnelle Suche nach Modulen verwenden Sie die Suchleiste.
- Wählen Sie das Modul Daten teilen aus, und konfigurieren Sie dessen Einstellungen wie folgt:
- Aufteilungsmodus: Zeilen aufteilen
- Bruchteil von Zeilen im ersten Ausgabedataset: 0,7
- Zufällige Aufteilung: True
- Zufälliger Ausgangswert: 123
- Geschichtete Aufteilung: FALSE
-
Suchen Sie in der Ressourcenbibliothek nach einem Modul vom Typ Modell trainieren, und platzieren Sie es auf der Canvas unter dem Modul Daten teilen. Verbinden Sie dann die (linke) Ausgabe Ergebnisse Dataset1 des Moduls Daten teilen mit der (rechten) Eingabe Dataset des Moduls Modell trainieren.
-
Das Modell, das wir trainieren, sagt den Wert Diabetic vorher. Wählen Sie also das Modul Modell trainieren aus, und ändern Sie dessen Einstellungen, um die Spalte Bezeichnung auf Diabetic festzulegen.
Die Bezeichnung Diabetic, die das Modell vorhersagt, ist eine Klasse (0 oder 1). Daher müssen Sie das Modell mithilfe eines Algorithmus zur Klassifizierung trainieren. Es gibt zwei mögliche Klassen, daher benötigen Sie einen Algorithmus zur binären Klassifizierung.
-
Suchen Sie in der Ressourcenbibliothek nach dem Modul Logistische Zwei-Klassen-Regression und platzieren Sie es im Canvas links neben dem Modul Daten teilen und über dem Modul Modell trainieren. Verbinden Sie anschließend seinen Ausgang mit dem (linken) Eingang Untrainiertes Modell des Moduls Modell trainieren.
Sie können das trainierte Modell testen, indem Sie es für die Bewertung des Validierungsdatasets verwenden, das Sie bei der Aufteilung der ursprünglichen Daten zurückgehalten haben. Sie sollen also die Bezeichnungen für die Features im Validierungsdataset vorhersagen.
- Suchen Sie in der Ressourcenbibliothek nach einem Modul vom Typ Modell bewerten, und platzieren Sie es auf der Canvas unter dem Modul Modell trainieren. Verbinden Sie anschließend den Ausgang des Moduls Modell trainieren mit dem (linken) Eingang Trainiertes Modell des Moduls Modell bewerten. Verbinden Sie den (rechten) Ausgang Ergebnisse Dataset2 des Moduls Daten teilen mit dem (rechten) Eingang Dataset des Moduls Modell bewerten.
Ausführen der Trainingspipeline
Nun können Sie die Trainingspipeline ausführen und das Modell trainieren.
-
Wählen Sie Konfigurieren und Übermitteln aus, und führen Sie die Pipeline mithilfe des vorhandenen Experiments mslearn-diabetes-training aus.
-
Warten Sie, bis die Experimentausführung abgeschlossen ist. Dies kann 5 Minuten oder länger dauern.
-
Sie können den Status des Auftrags überprüfen, indem Sie unter Ressourcen die Option Aufträge auswählen. Wählen Sie dort das Experiment mslearn-diabetes-training und dann den aktuellen Diabetes Training-Auftrag aus.
-
Klicken Sie auf der neuen Registerkarte mit der rechten Maustaste (Ctrl + Klick auf einem Mac) auf das Modul Modell auswerten im Canvas-Panel, wählen Sie Datenvorschau und dann Bewertetes Dataset aus, um die Ergebnisse anzuzeigen.
-
Scrollen Sie nach rechts, und beachten Sie, dass neben der Spalte Diabetic (die die bekannten wahren Werte der Bezeichnung enthält) eine neue Spalte mit dem Namen Scored Labels (Bewertete Bezeichnungen) vorhanden ist, die die vorhergesagten Bezeichnungswerte enthält, und eine Spalte Scored Probabilities (Bewertete Wahrscheinlichkeiten), die einen Wahrscheinlichkeitswert zwischen 0 und 1 enthält. Dies gibt die Wahrscheinlichkeit einer positiven Vorhersage an. Wahrscheinlichkeiten größer als 0,5 führen also zu einer vorhergesagten Bezeichnung von 1 (Diabetiker), während Wahrscheinlichkeiten zwischen 0 und 0,5 zu einer vorhergesagten Bezeichnung von 0 (kein Diabetiker) führen.
-
Schließen Sie die Registerkarte Scored_dataset.
Das Modell prognostiziert Werte für die Bezeichnung Diabetic, aber wie zuverlässig sind die Vorhersagen? Um dies zu bewerten, müssen Sie das Modell auswerten.
Die Validierungsdaten, die Sie zurückgehalten und zum Bewerten des Modells verwendet haben, enthalten die bekannten Werte für die Bezeichnung. Um das Modell zu überprüfen, können Sie die tatsächlichen Werte für die Bezeichnung daher mit den Bezeichnungswerten vergleichen, die vorhergesagt wurden, als Sie das Validierungsdataset bewertet haben. Basierend auf diesem Vergleich können Sie verschiedene Metriken berechnen, die beschreiben, wie gut das Modell ist.
Hinzufügen eines Moduls „Modell auswerten“
-
Kehren Sie zu Designer zurück, und öffnen Sie die Pipeline Diabetes Training, die Sie erstellt haben.
-
Suchen Sie in der Ressourcenbibliothek nach einem Modul vom Typ Modell auswerten und platzieren Sie es auf der Canvas unter dem Modul Modell bewerten. Verbinden Sie die Ausgabe des Moduls Modell bewerten mit der Eingabe Bewertetes Dataset (links) des Moduls Modell auswerten.
-
Vergewissern Sie sich, dass Ihre Pipeline wie folgt aussieht:
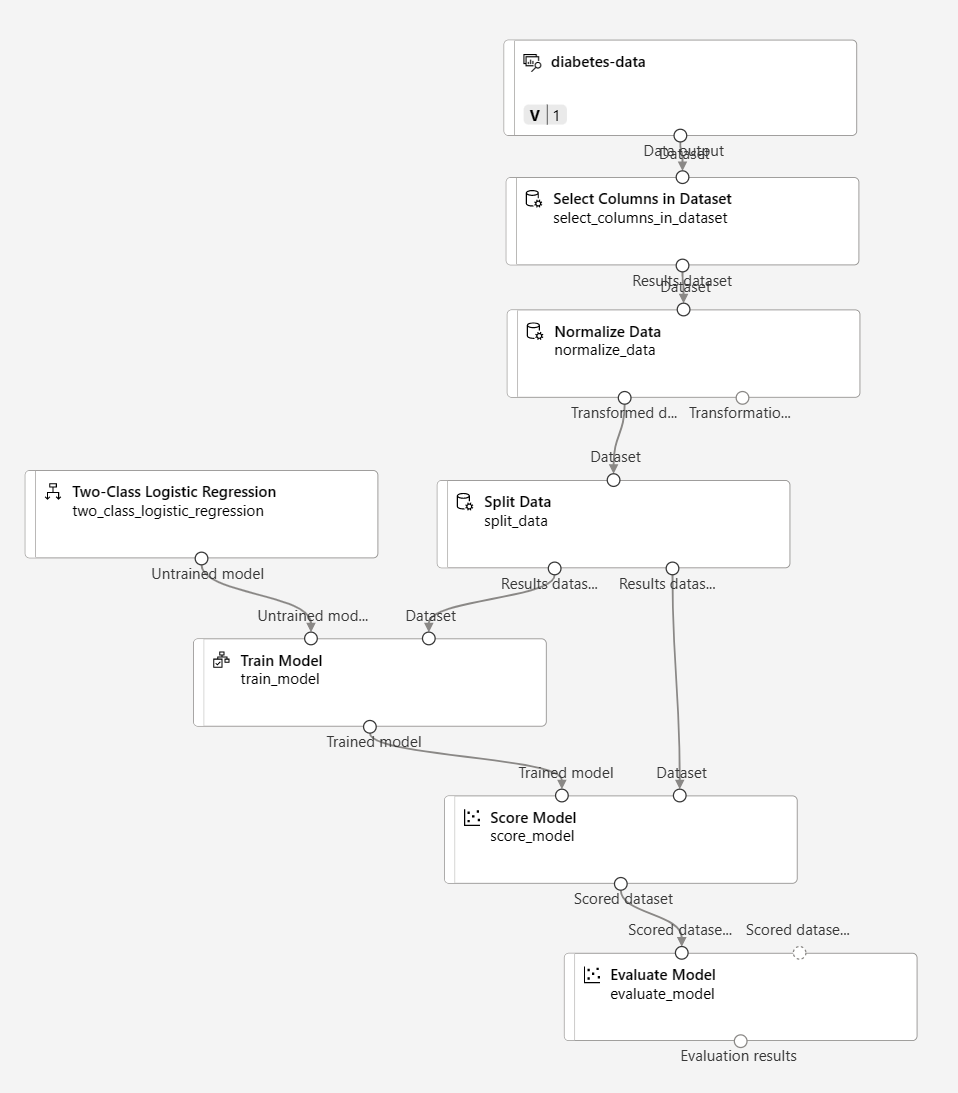
-
Wählen Sie Konfigurieren und Übermitteln aus, und führen Sie die Pipeline mithilfe des vorhandenen Experiments mslearn-diabetes-training aus.
-
Warten Sie, bis die Experimentausführung abgeschlossen ist.
-
Sie können den Status des Auftrags überprüfen, indem Sie unter Ressourcen die Option Aufträge auswählen. Wählen Sie dort das Experiment mslearn-diabetes-training und dann den aktuellen Diabetes Training-Auftrag aus.
-
Klicken Sie auf der neuen Registerkarte mit der rechten Maustaste (Ctrl + Klick auf einem Mac) auf das Modul Modell auswerten im Canvas-Panel, wählen Sie Vorschaudaten und dann Auswertungsergebnisse aus, um die Leistungsmetriken anzuzeigen. Mithilfe dieser Metriken können Data Scientists bewerten, wie gut die Vorhersagen des Modells basierend auf den Validierungsdaten sind.
-
Scrollen Sie nach unten, um die Konfusionsmatrix für das Modell anzuzeigen. Beobachten Sie die vorhergesagten und tatsächlichen Werte für jede mögliche Klasse.
- Überprüfen Sie die Metriken auf der linken Seite der Konfusionsmatrix, die Folgendes umfassen:
- Genauigkeit: Mit anderen Worten: Welchen Anteil von Diabetesfällen hat das Modell richtig vorhergesagt?
- Genauigkeit: Mit anderen Worten: Welcher Prozentsatz der Patienten, für die das Modell eine Diabeteserkrankung vorhergesagt hat, wurde richtig vorhergesagt?
- Abruf: Mit anderen Worten: Wie viele der Patienten, die tatsächlich Diabetes haben, hat das Modell richtig identifiziert?
- F1-Bewertung
-
Verwenden Sie den Schieberegler Grenzwert oberhalb der Liste der Metriken. Verschieben Sie den Schwellenwert-Schieberegler, und beobachten Sie die Auswirkung auf die Konfusionsmatrix. Wenn Sie ihn ganz nach links verschieben (0), wird die Metrik „Trefferquote“ 1, und wenn Sie ihn ganz nach rechts verschieben (1), wird die Metrik „Trefferquote“ 0.
-
Über dem Schieberegler „Grenzwert“ befinden sich die ROC-Kurve und die AUC-Metrik zusammen mit den anderen Metriken unten. Um eine Vorstellung davon zu erhalten, wie dieser Bereich die Leistung des Modells darstellt, stellen Sie sich eine gerade diagonale Linie von links unten nach rechts oben im ROC-Diagramm vor. Diese stellt die erwartete Leistung dar, wenn Sie für jeden Patienten raten oder eine Münze werfen. Sie könnten dabei davon ausgehen, dass Sie ungefähr die Hälfte richtig und die Hälfte falsch hätten, sodass der Bereich unter der diagonalen Linie einen AUC-Score von 0,5 darstellt. Wenn der AUC-Score Ihres Modell für ein binäres Klassifizierungsmodell höher als dieser Wert ist, ist das Modell besser als zufälliges Raten.
- Schließen Sie die Registerkarte Evaluation_results.
Die Leistung dieses Modells ist nicht besonders gut, da Sie nur eine minimale Featurisierung und Vorverarbeitung durchgeführt haben. Sie könnten einen anderen Klassifizierungsalgorithmus verwenden, z. B. einen zweiklassigen Entscheidungswald, und die Ergebnisse vergleichen. Sie können die Ausgänge des Moduls Daten teilen mit mehreren Modulen der Typen Modell trainieren und Modell bewerten verbinden, und Sie können ein zweites Modul Modell bewerten mit dem Modul Modell auswerten verbinden, um einen direkten Vergleich zu erhalten. Bei dieser Übung geht es lediglich um eine Einführung in die Klassifizierung und die Benutzeroberfläche des Azure Machine Learning-Designers, nicht um das Trainieren eines perfekten Modells.
Erstellen einer Rückschlusspipeline
-
Wählen Sie im Menü oberhalb des Canvas-Panels Rückschlusspipeline erstellen aus. Möglicherweise müssen Sie hierfür in den Vollbildmodus wechseln und rechts oben auf das Symbol mit den drei Punkten … klicken, damit die Option Rückschlusspipeline erstellen im Menü angezeigt wird.

-
Klicken Sie in der Dropdownliste Rückschlusspipeline erstellen auf Echtzeit-Rückschlusspipeline. Nach einigen Sekunden wird eine neue Version Ihrer Pipeline mit dem Namen Diabetes Training-real time inference (Diabetesschulung – Echtzeitrückschlüsse) geöffnet.
-
Benennen Sie die neue Pipeline in Predict Diabetes um, und überprüfen Sie dann die neue Pipeline. Einige der Transformationen und Trainingsschritte sind Teil dieser Pipeline. Das trainierte Modell wird zur Bewertung der neuen Daten verwendet. Die Pipeline enthält auch eine Webdienstausgabe zum Zurückgeben von Ergebnissen.
Nehmen Sie an der Rückschlusspipeline die folgenden Änderungen vor:
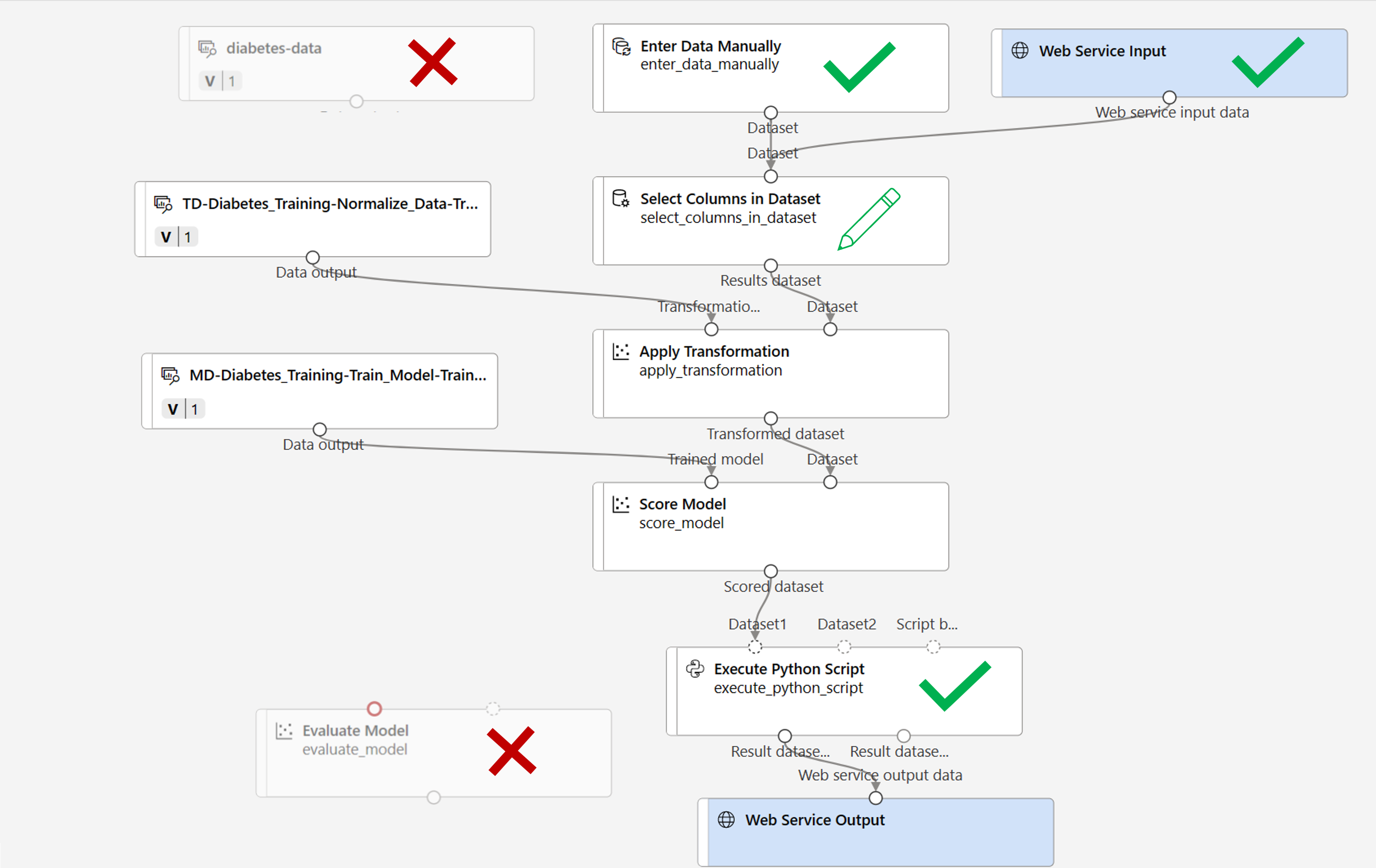
- Fügen Sie eine Webdiensteingabekomponente für neue Daten hinzu, die übermittelt werden sollen.
- Ersetzen Sie das Dataset diabetes-data durch ein Modul Daten manuell eingeben, das die Bezeichnungsspalte (Diabetic) nicht enthält.
- Bearbeiten Sie die ausgewählten Spalten im Modul Spalten im Dataset auswählen.
- Entfernen Sie das Modul Modell auswerten.
- Fügen Sie vor dem Webdienstausgang ein Modul Python-Skript ausführen ein, damit nur die Patienten-ID, der vorhergesagte Bezeichnungswert und die Wahrscheinlichkeit zurückgegeben werden.
-
Die Pipeline enthält nicht automatisch eine Webdiensteingabekomponente für Modelle, die aus benutzerdefinierten Datasets erstellt werden. Suchen Sie in der Ressourcenbibliothek nach einer Webdiensteingabekomponente, und platzieren Sie diese oben in der Pipeline. Verbinden Sie die Ausgabe der Webdiensteingabekomponente mit der Komponente Spalten im Dataset auswählen, die sich bereits auf der Canvas befindet.
-
Die Rückschlusspipeline geht davon aus, dass neue Daten dem Schema der ursprünglichen Trainingsdaten entsprechen, sodass das Dataset diabetes-data aus der Trainingspipeline eingeschlossen wird. Diese Eingabedaten enthalten jedoch die Bezeichnung Diabetic, die vom Modell vorhergesagt wird. Diese Bezeichnung ist in neuen Patientendaten, für die noch keine Vorhersage über den Diabetes ausgeführt wurde, nicht enthalten. Löschen Sie dieses Modul und ersetzen Sie es durch ein Modul Daten manuell eingeben, das die folgenden CSV-Daten enthält, die Merkmalswerte ohne Beschriftungen für drei neue Patientenbeobachtungen enthalten:
PatientID,Pregnancies,PlasmaGlucose,DiastolicBloodPressure,TricepsThickness,SerumInsulin,BMI,DiabetesPedigree,Age 1882185,9,104,51,7,24,27.36983156,1.350472047,43 1662484,6,73,61,35,24,18.74367404,1.074147566,75 1228510,4,115,50,29,243,34.69215364,0.741159926,59 -
Verbinden Sie das neue Modul Daten manuell eingeben mit derselben Eingabe des Datasets des Moduls Spalten im Dataset auswählen wie bei der Webdiensteingabe.
-
Bearbeiten Sie das Modul Spalten im Dataset auswählen. Entfernen Sie Diabetic aus Ausgewählte Spalten.
-
Die Rückschlusspipeline umfasst das Modell Modul auswerten, das bei der Vorhersage aus neuen Daten nicht nützlich ist. Löschen Sie daher dieses Modul.
- Die Ausgabe des Moduls Modell bewerten umfasst alle Eingabefeatures sowie die vorhergesagte Bezeichnung und den Wahrscheinlichkeitsscore. So beschränken Sie die Ausgabe nur auf die Vorhersage und die Wahrscheinlichkeit
- Löschen Sie die Verbindung zwischen dem Modul Modell bewerten und dem Webdienstausgang.
- Fügen Sie ein Modul Python-Skript ausführen hinzu und ersetzen Sie das gesamte Standard-Python-Skript durch den folgenden Code (der nur die Spalten PatientID, Bewertete Etiketten und Bewertete Wahrscheinlichkeiten auswählt und sie entsprechend umbenennt):
import pandas as pd def azureml_main(dataframe1 = None, dataframe2 = None): scored_results = dataframe1[['Scored Labels', 'Scored Probabilities']] scored_results.rename(columns={'Scored Labels':'DiabetesPrediction', 'Scored Probabilities':'Probability'}, inplace=True) return scored_results -
Verbinden Sie die Ausgabe des Moduls Modell auswerten mit der Eingabe Dataset1 (ganz links) von Python-Skript ausführen, und verbinden Sie die Ausgabe Ergebnisdataset (links) des Moduls Python-Skript ausführen mit Webdienstausgabe.
-
Ihre Pipeline sollte etwa wie die folgende aussehen:
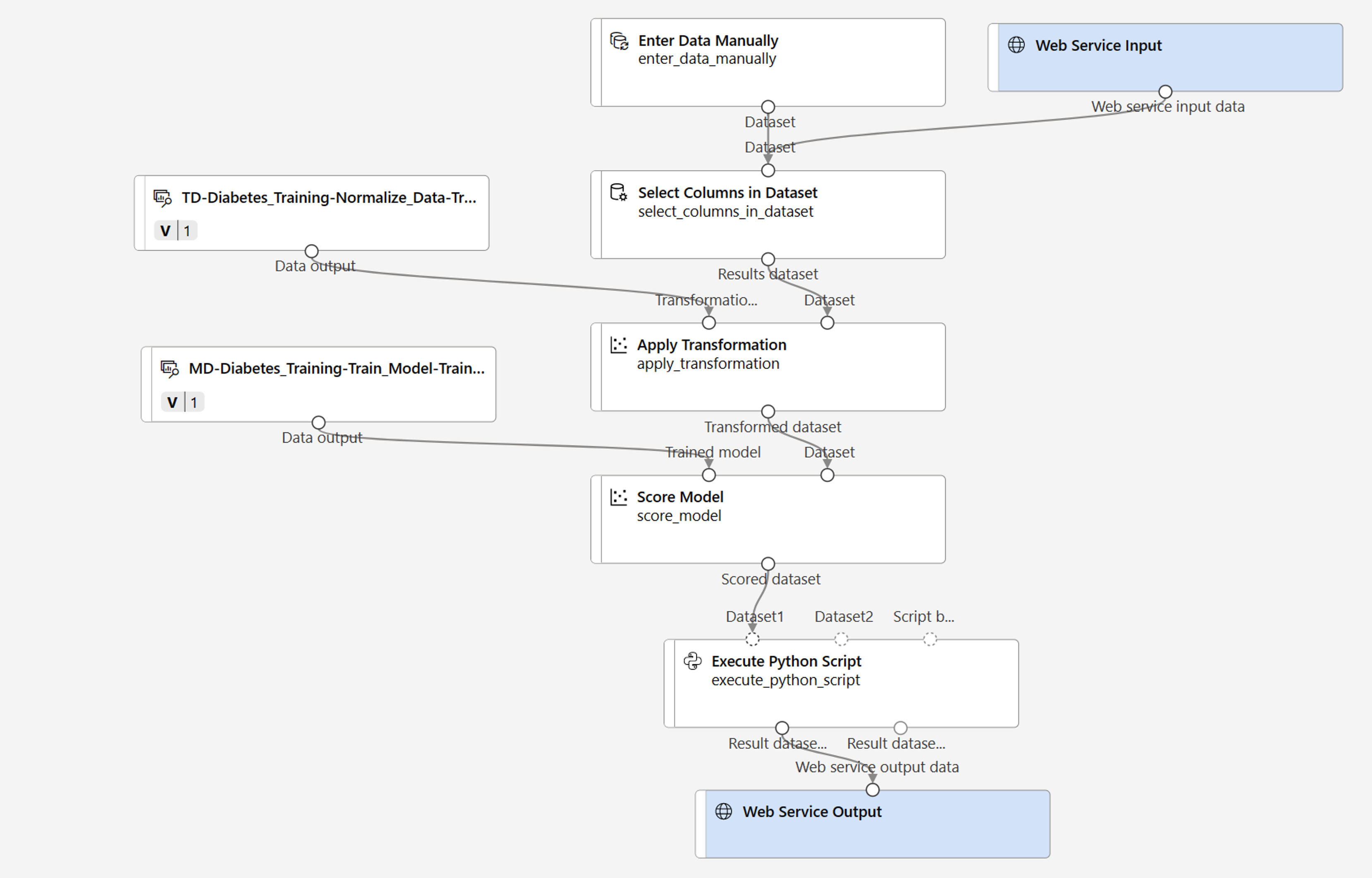
-
Führen Sie die Pipeline als neues Experiment mit dem Namen mslearn-diabetes-inference auf Ihrem Computecluster aus. Die Ausführung des Experiments kann einige Minuten dauern.
-
Kehren Sie zur Registerkarte Aufträge zurück. Wählen Sie dort das Experiment mslearn-diabetes-inference und dann den Auftrag Predict Diabetes aus.
- Wenn die Pipeline abgeschlossen ist, wählen Sie das Modul Python-Skript ausführen aus. Wählen Sie die Datenvorschau und dann Ergebnisdataset aus, um die vorhergesagten Bezeichnungen und Wahrscheinlichkeiten für die drei Patientenbeobachtungen in den Eingabedaten anzuzeigen.
Ihre Rückschlusspipeline sagt basierend auf den Features der Patienten vorher, ob für diese eine Gefahr für Diabetes vorliegt. Sie können die Pipeline nun so veröffentlichen, dass sie von Clientanwendungen verwendet werden kann.
Nachdem Sie eine Rückschlusspipeline für Echtzeitrückschlüsse erstellt und getestet haben, können Sie sie als Dienst veröffentlichen, der von Clientanwendungen verwendet werden kann.
Hinweis: In dieser Übung stellen Sie den Webdienst in einer Azure-Containerinstanz bereit. Solche Computeressourcen werden dynamisch erstellt und sind für Entwicklungs- und Testzwecke nützlich. Für Produktionszwecke sollten Sie einen Rückschlusscluster erstellen, der einen AKS-Cluster (Azure Kubernetes Service) mit verbesserter Skalierbarkeit und Sicherheit bereitstellt.
Bereitstellen eines Diensts
-
Wählen Sie oben im Auftragsfenster Predict Diabetes die Option Bereitstellen aus.

- Wählen Sie unter Echtzeitendpunkt einrichten die Option Neuen Echtzeitendpunkt bereitstellen aus, und verwenden Sie die folgenden Einstellungen:
- Name: predict-diabetes
- Beschreibung: Diabetes klassifizieren
- Computetyp: Azure Container Instances
- Wählen Sie Bereitstellen aus, und warten Sie, bis der Webdienst bereitgestellt wurde. Dieser Vorgang kann einige Minuten dauern.
Testen des Diensts
-
Öffnen Sie auf der Seite Endpunkte den Echtzeitendpunkt predict-diabetes.
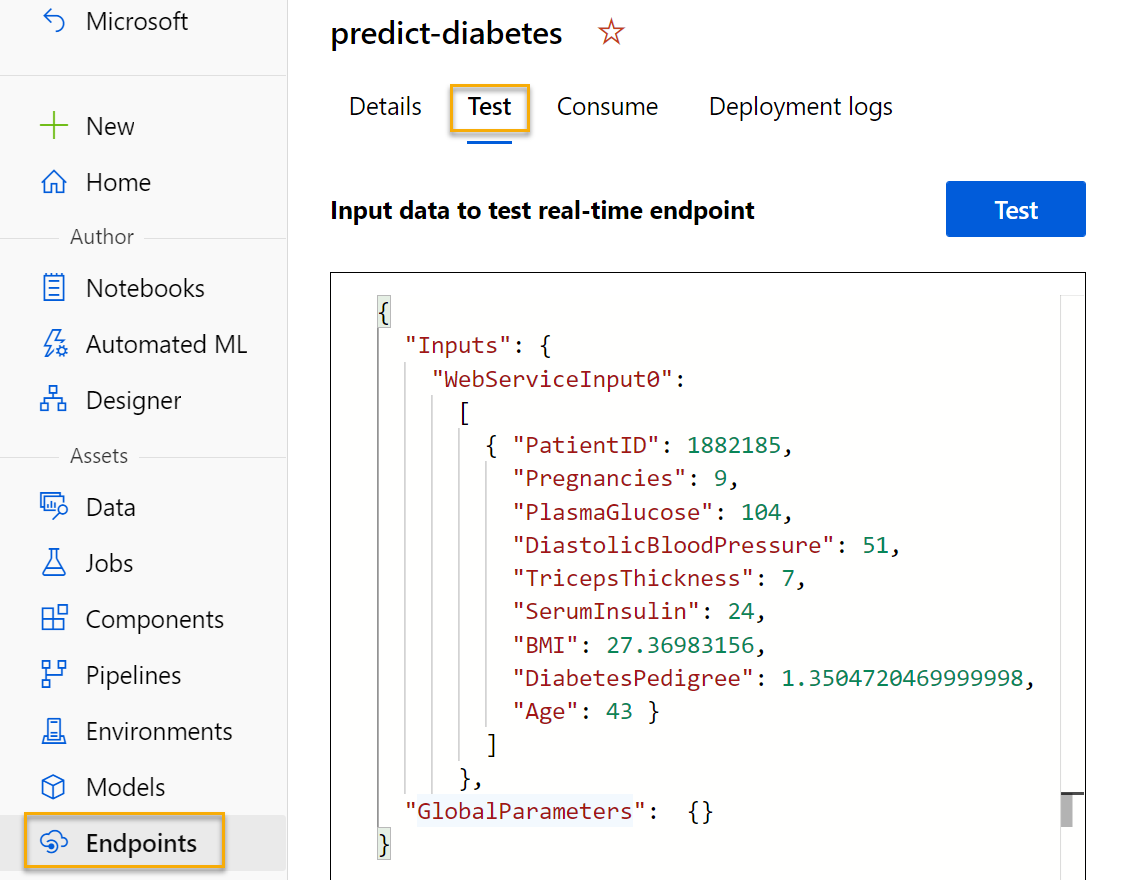
-
Wenn der Endpunkt predict-diabetes geöffnet wird, wählen Sie die Registerkarte Test aus. Hier testen wir unser Modell mit neuen Daten. Löschen Sie die vorhandenen Daten unter Input data to test real-time endpoint (Eingabedaten zum Testen des Echtzeitendpunkts). Kopieren Sie die folgenden Daten, und fügen Sie sie in den Abschnitt „Daten“ ein:
{ "Inputs": { "input1": [ { "PatientID": 1882185, "Pregnancies": 9, "PlasmaGlucose": 104, "DiastolicBloodPressure": 51, "TricepsThickness": 7, "SerumInsulin": 24, "BMI": 27.36983156, "DiabetesPedigree": 1.3504720469999998, "Age": 43 } ] }, "GlobalParameters": {} }Hinweis: Der JSON-Code oben definiert Funktionen für einen Patienten und verwendet den von Ihnen erstellten Dienst predict-diabetes, um eine Diabetesdiagnose vorherzusagen.
-
Klicken Sie auf Test. Auf der rechten Seite des Bildschirms sollte die Ausgabe ‘DiabetesPrediction’ angezeigt werden. Die Ausgabe ist 1, wenn für den Patienten Diabetes vorhergesagt wird, und 0, wenn für den Patienten kein Diabetes vorhergesagt wird.
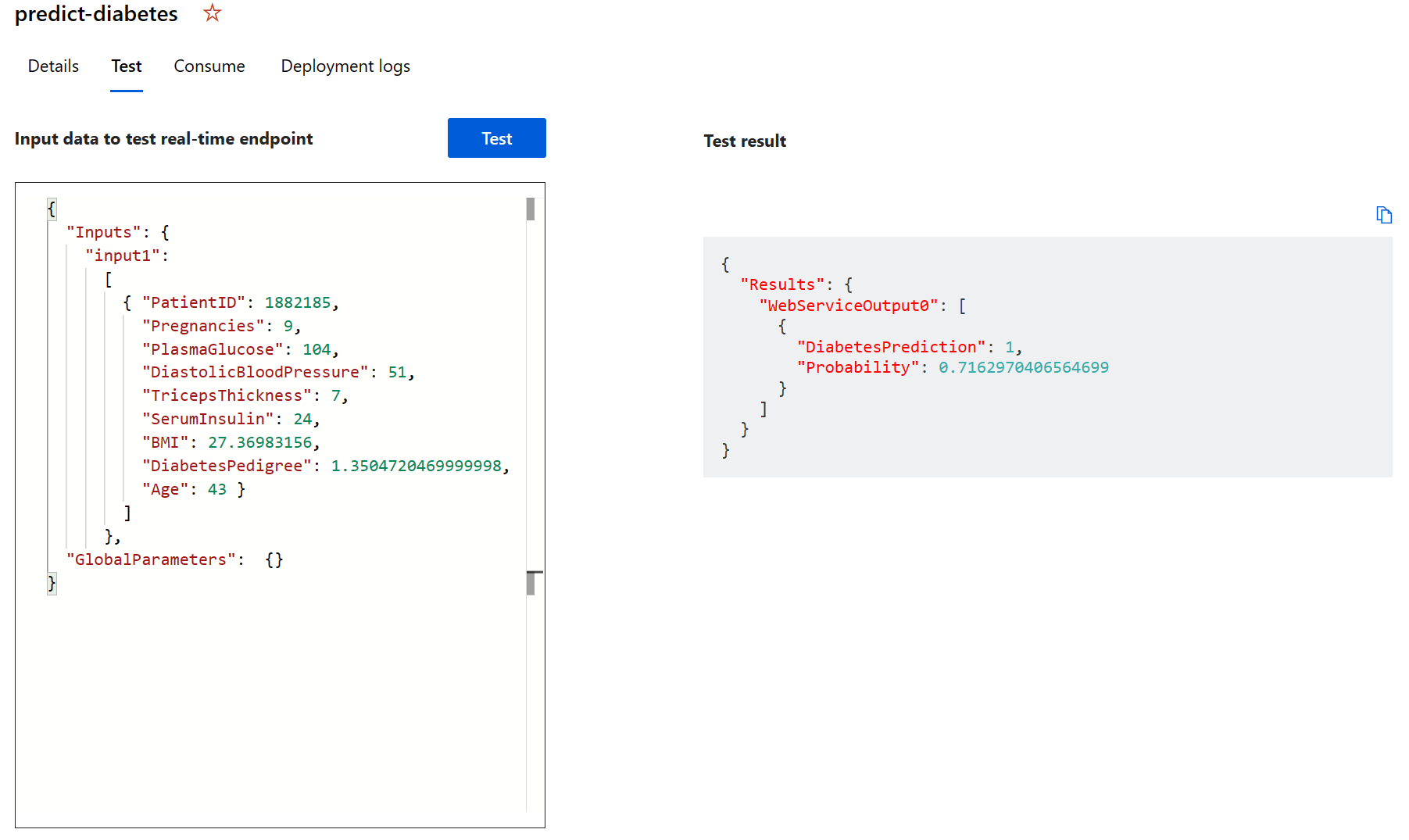
Sie haben gerade einen Dienst getestet, der mit einer Clientanwendung eine Verbindung herstellen kann, indem die Anmeldeinformationen auf der Registerkarte Consume (Verbrauchen) verwendet werden. Das Lab endet hier. Sie können gern weiter mit dem Dienst experimentieren, den Sie gerade eingerichtet haben.
Bereinigung
Der von Ihnen erstellte Webdienst wird in einer Azure-Containerinstanz gehostet. Wenn Sie nicht weiter experimentieren möchten, sollten Sie den Endpunkt löschen, um eine unnötige Azure-Nutzung zu vermeiden. Sie sollten auch den Computecluster löschen.
-
Wählen Sie in Azure Machine Learning Studio auf der Registerkarte Endpunkte den Endpunkt predict-diabetes aus. Klicken Sie dann auf Löschen, und bestätigen Sie, dass Sie den Endpunkt löschen möchten.
-
Wählen Sie auf der Seite Compute auf der Registerkarte Computecluster Ihren Computecluster aus, und klicken Sie dann auf Löschen.
Hinweis: Durch das Löschen Ihrer Compute-Instanz wird sichergestellt, dass Ihrem Abonnement keine Computeressourcen in Rechnung gestellt werden. Ihnen wird jedoch eine geringe Datenspeichermenge in Rechnung gestellt, solange der Azure Machine Learning-Arbeitsbereich in Ihrem Abonnement enthalten ist. Wenn Sie mit dem Erkunden von Azure Machine Learning fertig sind, können Sie Ihren Azure Machine Learning-Arbeitsbereich und die zugehörigen Ressourcen löschen. Wenn Sie jedoch andere Labs in dieser Reihe abschließen möchten, müssen Sie ihn neu erstellen.
So löschen Sie Ihren Arbeitsbereich:
- Öffnen Sie im Azure-Portal auf der Seite Ressourcengruppen die Ressourcengruppe, die Sie beim Erstellen des Azure Machine Learning-Arbeitsbereichs angegeben haben.
- Klicken Sie auf Ressourcengruppe löschen, geben Sie den Ressourcengruppennamen ein, um zu bestätigen, dass Sie ihn löschen möchten, und klicken Sie dann auf Löschen.