Untersuchen der Regression mit dem Azure Machine Learning-Designer
Hinweis: Um dieses Lab abzuschließen, benötigen Sie ein Azure-Abonnement, in dem Sie über Administratorzugriff verfügen.
In dieser Übung werden Sie ein Regressionsmodell trainieren, das den Preis eines Autos anhand seiner Merkmale vorhersagt.
Erstellen eines Azure Machine Learning-Arbeitsbereichs
-
Melden Sie sich mit Ihren Microsoft-Anmeldeinformationen beim Azure-Portal an.
- Klicken Sie auf + Ressource erstellen, suchen Sie nach Machine Learning, und erstellen Sie eine neue Azure Machine Learning-Ressource mit einem Azure Machine Learning-Plan. Verwenden Sie folgende Einstellungen:
- Abonnement: Ihr Azure-Abonnement.
- Ressourcengruppe: Erstellen Sie eine Ressourcengruppe, oder wählen Sie eine Ressourcengruppe aus.
- Arbeitsbereichsname: Geben Sie einen eindeutigen Namen für den Arbeitsbereich ein.
- Region: Wählen Sie die geografisch nächstgelegene Region aus.
- Speicherkonto: Für Ihren Arbeitsbereich wird standardmäßig ein neues Speicherkonto erstellt.
- Schlüsseltresor: Für Ihren Arbeitsbereich wird standardmäßig ein neuer Schlüsseltresor erstellt.
- Application Insights: Für Ihren Arbeitsbereich wird standardmäßig eine neue Application Insights-Ressource erstellt.
- Containerregistrierung: Keine (wird automatisch erstellt, wenn Sie das erste Mal ein Modell in einem Container bereitstellen)
-
Klicken Sie aufÜberprüfen + erstellen und dann auf Erstellen. Warten Sie, bis Ihr Arbeitsbereich erstellt wurde (dies kann einige Minuten dauern), und wechseln Sie dann zur bereitgestellten Ressource.
-
Wählen Sie Studio starten aus (oder öffnen Sie eine neue Browserregisterkarte. Navigieren Sie dann zu https://ml.azure.com, und melden Sie sich mit Ihrem Microsoft-Konto bei Azure Machine Learning Studio an).
- In Azure Machine Learning Studio sollte Ihr neu erstellter Arbeitsbereich angezeigt werden. Wenn dies nicht der Fall ist, wählen Sie im linken Menü Ihr Azure-Verzeichnis aus. Wählen Sie dann im neuen Menü auf der linken Seite Arbeitsbereiche aus, wo alle Arbeitsbereiche aufgeführt sind, die Ihrem Verzeichnis zugeordnet sind, und wählen Sie den Arbeitsbereich aus, den Sie für diese Übung erstellt haben.
Hinweis: Dieses Modul ist eines von vielen, in denen ein Azure Machine Learning-Arbeitsbereich verwendet wird (einschließlich der anderen Module im Lernpfad Microsoft Azure KI-Grundlagen: Erkunden visueller Tools für maschinelles Lernen). Wenn Sie Ihr eigenes Azure-Abonnement verwenden, sollten Sie den Arbeitsbereich einmal erstellen und in anderen Modulen wiederverwenden. Ihrem Azure-Abonnement wird eine kleine Menge an Datenspeicher in Rechnung gestellt, solange der Azure Machine Learning-Arbeitsbereich in Ihrem Abonnement vorhanden ist. Daher wird empfohlen, den Azure Machine Learning-Arbeitsbereich zu löschen, wenn er nicht mehr benötigt wird.
Erstellen von Computeressourcen
-
Wählen Sie in Azure Machine Learning Studio das Symbol ≡ aus (ein Menüsymbol, dass wie drei übereinander angeordnete Linien aussieht), um die verschiedenen Seiten auf der Benutzeroberfläche anzuzeigen (möglicherweise müssen Sie die Größe des Bildschirms maximieren). Sie können diese Seiten im linken Bereich verwenden, um die Ressourcen in Ihrem Arbeitsbereich zu verwalten. Wählen die Seite Compute (unter Verwalten) aus.
-
Klicken Sie auf der Seite Compute auf die Registerkarte Computecluster, und fügen Sie einen neuen Computecluster mit den folgenden Einstellungen hinzu, um ein Machine Learning-Modell zu trainieren:
- Standort: Wählen Sie denselben Standort wie für Ihren Arbeitsbereich aus. Wenn dieser Standort nicht aufgeführt wird, wählen Sie den nächstgelegenen Standort aus.
- VM-Dienstebene: Dediziert.
- VM-Typ: CPU
- VM-Größe:
- Klicken Sie auf Aus allen Optionen auswählen.
- Suchen Sie Standard_DS11_v2, und wählen Sie den Eintrag aus.
- Wählen Sie Weiter aus.
- Computename:Geben Sie einen eindeutigen Namen ein.
- Mindestanzahl von Knoten: 0
- Maximale Knotenanzahl: 2
- Leerlauf in Sekunden vor dem Herunterskalieren: 120
- SSH-Zugriff aktivieren: Deaktiviert.
- Klicken Sie auf Erstellen.
Hinweis: Compute-Instanzen und -cluster basieren auf Azure VM-Standardimages. Für dieses Modul wird das Image Standard_DS11_v2 empfohlen, um ein optimales Gleichgewicht zwischen Kosten und Leistung zu erzielen. Wenn Ihr Abonnement über ein Kontingent verfügt, das dieses Image nicht enthält, wählen Sie ein alternatives Image aus. Beachten Sie jedoch, dass ein größeres Image höhere Kosten verursachen kann und ein kleineres Image möglicherweise nicht ausreicht, um die Aufgaben auszuführen. Bitten Sie alternativ Ihren Azure-Administrator, Ihr Kontingent zu erhöhen.
Die Erstellung des Computeclusters nimmt einige Zeit in Anspruch. Sie können mit dem nächsten Schritt fortfahren, während Sie warten.
Erstellen einer Pipeline in Designer und Hinzufügen eines Datasets
Azure Machine Learning enthält ein Beispieldataset, das Sie für Ihr Regressionsmodell verwenden können.
-
Erweitern Sie in Azure Machine Learning Studio den linken Bereich, indem Sie das Menüsymbol oben links auf dem Bildschirm auswählen. Zeigen Sie die Seite Designer (unter Erstellung) an, und wählen Sie + aus, um eine neue Pipeline zu erstellen.
-
Ändern Sie den Entwurfsnamen (Pipeline-Created-on-* Datum*) in Auto Price Training.
-
Wählen Sie neben dem Pipelinenamen auf der linken Seite das Pfeilsymbol, um das Panel zu erweitern, wenn es nicht bereits erweitert ist. Der Bereich sollte standardmäßig im Bereich Ressourcenbibliothek geöffnet werden. Dies wird durch das Büchersymbol am oberen Rand des Bereichs gekennzeichnet. Es gibt eine Suchleiste zum Suchen von Objekten im Bereich und zwei Schaltflächen: Daten und Komponente.
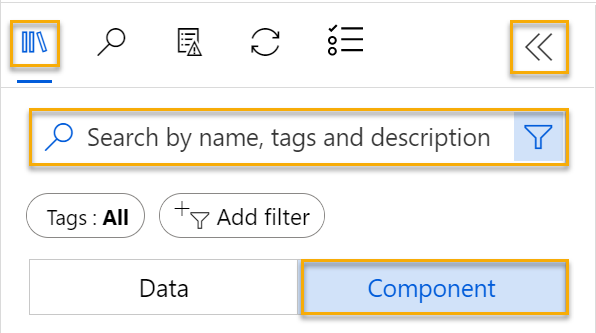
-
Wählen Sie Komponente aus. Suchen Sie nach dem Dataset Automobile price data (Raw), und platzieren Sie es auf der Canvas.
-
Klicken Sie mit der rechten Maustaste (Ctrl + Klick auf dem Mac) auf das Dataset Automobile price data (Raw) im Canvas-Panel, und wählen Sie Datenvorschau aus.
-
Sehen Sie sich das Schema Datasetausgabe an. Beachten Sie, dass die Verteilungen der verschiedenen Spalten als Histogramme angezeigt werden.
-
Scrollen Sie im Dataset nach rechts, bis die Spalte Price (Preis) angezeigt wird, die die Bezeichnung darstellt, die von Ihrem Modell vorhersagt wird.
-
Scrollen Sie zurück nach links, und wählen Sie die Spaltenüberschrift normalized-losses aus. Überprüfen Sie dann die Statistiken für diese Spalte. Beachten Sie, dass in dieser Spalte einige Werte fehlen. Fehlende Werte schränken die Zweckmäßigkeit der Spalte für die Vorhersage der Preisbezeichnung ein, deshalb sollten Sie sie aus dem Training ausschließen.
-
Schließen Sie das Fenster DataOutput, damit das Dataset wie folgt im Canvas-Panel angezeigt wird:
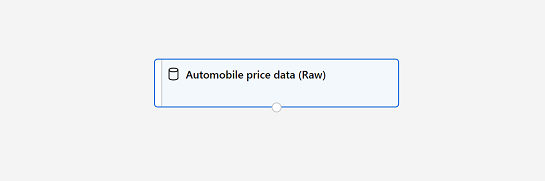
Hinzufügen von Datentransformationen
In der Regel wenden Sie Datentransformationen an, um die Daten für die Modellierung vorzubereiten. Im Fall der Autopreisdaten fügen Sie Transformationen hinzu, um die Probleme zu beheben, die Sie beim Untersuchen der Daten festgestellt haben.
-
Wählen Sie links im Bereich Ressourcenbibliothek die Option Komponente aus. Diese enthält verschiedenste Module, die Sie für Datentransformationen und Modelltrainings verwenden können. Für die schnelle Suche nach Modulen können Sie auch die Suchleiste verwenden.
-
Suchen Sie nach einem Modul vom Typ Spalten im Dataset auswählen, und platzieren Sie es auf der Canvas unterhalb des Moduls Fahrzeugpreisdaten (Rohdaten). Verbinden Sie dann wie folgt die Ausgabe unten des Moduls Automobile price data (Raw) mit der Eingabe oben des Moduls Spalten im Dataset auswählen:
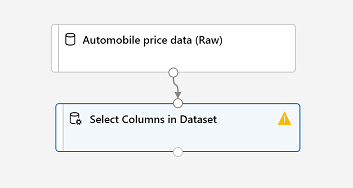
-
Doppelklicken Sie auf das Modul Spalten im Dataset auswählen, um rechts auf einen Bereich mit Einstellungen zuzugreifen. Wählen Sie Spalte bearbeiten aus. Wählen Sie dann im Fenster Spalten auswählen die Optionen Nach Name und Alle hinzufügen aus, um alle Spalten hinzuzufügen. Entfernen Sie die Spalte normalized-losses, sodass Ihre endgültige Spaltenauswahl wie folgt aussieht:
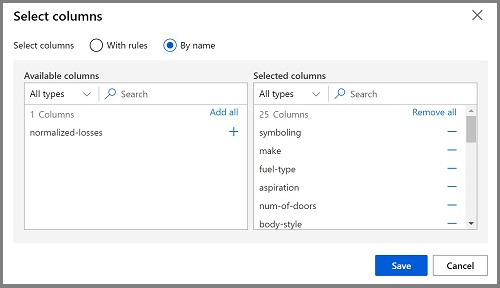
-
Wählen Sie Speichern aus, und schließen Sie das Eigenschaftenfenster.
Im weiteren Verlauf dieser Übung erstellen Sie eine Pipeline, die wie folgt aussehen sollte:
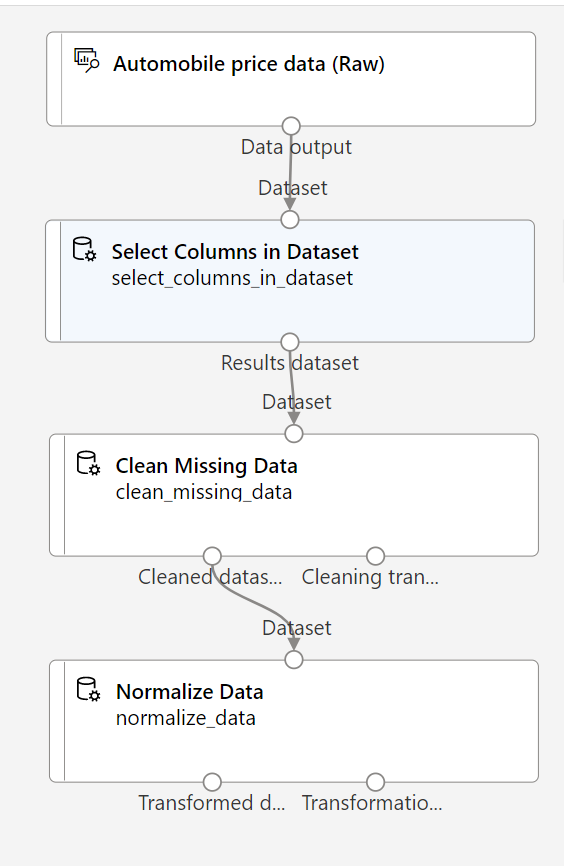
Führen Sie die restlichen Schritte aus, und verwenden Sie die Abbildung als Referenz für das Hinzufügen und Konfigurieren der erforderlichen Module.
-
Suchen Sie in der Ressourcenbibliothek nach einem Modul vom Typ Fehlende Daten bereinigen, und platzieren Sie es auf der Canvas unterhalb des Moduls Spalten im Dataset auswählen. Verbinden Sie dann die Ausgabe des Moduls Spalten in Dataset auswählen mit der Eingabe des Moduls Fehlende Daten bereinigen.
-
Doppelklicken Sie auf das Modul Fehlende Daten bereinigen, und wählen Sie im Bereich rechts Spalte bearbeiten aus. Klicken Sie im Fenster Zu bereinigende Spalten auf Mit Regeln, wählen Sie in der Liste Einschließen die Option Spaltennamen aus, und geben Sie folgendermaßen bore, stroke und horsepower in das Feld für Spaltennamen ein:
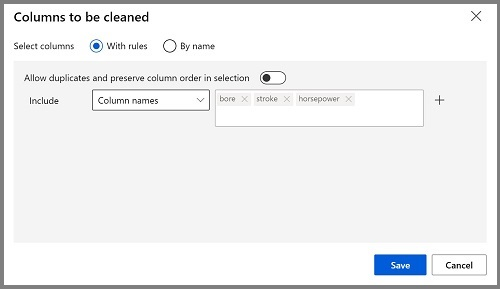
- Während das Modul Fehlende Daten bereinigen noch ausgewählt ist, legen Sie im Bereich auf der rechten Seite die folgenden Konfigurationseinstellungen fest:
- Mindestanzahl fehlender Werte: 0,0
- Maximale Anzahl fehlender Werte: 1,0
- Bereinigungsmodus: Gesamte Zeile entfernen
Tipp: Wenn Sie sich die Statistiken für die Spalten bore, stroke und horsepower ansehen, werden Sie eine Reihe von fehlenden Werten feststellen. In diesen Spalten fehlen weniger Werte als in normalized-losses. Sie können also weiterhin zum Vorhersagen der Bezeichnung Price nützlich sein, sobald Sie die Zeilen aus dem Training ausschließen, in denen Werte fehlen.
-
Suchen Sie in der Ressourcenbibliothek nach einem Modul vom Typ Daten normalisieren, und platzieren Sie es auf der Canvas unter dem Modul Fehlende Daten bereinigen. Verbinden Sie dann die Ausgabe ganz links des Fehlende Daten bereinigen-Moduls mit der Eingabe des Daten normalisieren-Moduls.
- Doppelklicken Sie auf das Modul Daten normalisieren, um den zugehörigen Parameterbereich anzuzeigen. Sie müssen die Transformationsmethode und die zu transformierenden Spalten angeben. Legen Sie die Transformationsmethode auf MinMax fest. Wenden Sie eine Regel an, indem Sie Spalte bearbeiten auswählen und die folgenden Spaltennamen einschließen:
- symboling
- wheel-base
- length
- width
- height
- curb-weight
- engine-size
- bore
- stroke
- compression-ratio
- horsepower
- peak-rpm
- city-mpg
- highway-mpg
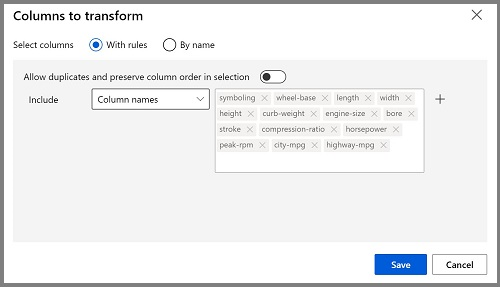
Tipp: Wenn Sie sich die Spalten stroke, peak-rpm und city-mpg ansehen, werden Sie feststellen, dass alle in verschiedenen Größenordnungen gemessen werden, und es ist möglich, dass die größeren Werte für peak-rpm zu einer Verzerrung des Trainingsalgorithmus und einer übermäßigen Abhängigkeit von dieser Spalte im Vergleich zu Spalten mit niedrigeren Werten wie z. B. stroke führen. Data Scientists mindern diese mögliche Abweichung in der Regel, indem sie numerische Spalten normalisieren, damit sie eine ähnliche Skalierung aufweisen.
Führen Sie die Pipeline aus.
Um Ihre Datentransformationen anzuwenden, müssen Sie die Pipeline ausführen.
-
Stellen Sie sicher, dass Ihre Pipeline in etwa wie in dieser Abbildung aussieht:
-
Wählen Sie oben auf der Seite Konfigurieren und Übermitteln aus, um das Dialogfeld Pipelineauftrag einrichten zu öffnen.
-
Wählen Sie auf der Seite Grundlagen die Option Neu erstellen aus, und legen Sie den Namen des Experiments auf mslearn-auto-training fest. Wählen Sie dann Weiter aus.
-
Wählen Sie auf der Seite Eingaben und Ausgaben die Option Weiter aus, ohne Änderungen vorzunehmen.
-
Auf der Seite Laufzeiteinstellungen wird ein Fehler angezeigt, da Sie nicht über eine Standardcomputeressource für die Ausführung der Pipeline verfügen. Wählen Sie in der Dropdownliste Computetyp auswählen die Option Computecluster und in der Dropdownliste Azure ML Computecluster auswählen Ihren kürzlich erstellten Computecluster aus.
-
Wählen Sie Weiter aus, um den Pipelineauftrag zu überprüfen, und wählen Sie dann Übermitteln aus, um die Trainingspipeline auszuführen.
-
Warten Sie einige Minuten, bis die Ausführung abgeschlossen ist. Sie können den Status des Auftrags überprüfen, indem Sie unter Ressourcen die Option Aufträge auswählen. Wählen Sie dort den Auftrag Auto Price Training aus. Hier können Sie sehen, wenn der Auftrag abgeschlossen ist. Sobald der Auftrag abgeschlossen ist, wird das Dataset für das Modelltraining vorbereitet.
-
Navigieren Sie zum linken Menü. Wählen Sie unter Dokumenterstellung die Option Designer aus. Wählen Sie dann Ihre Pipeline Automatisches Preistraining aus der Liste der Pipelines aus.
Erstellen einer Trainingspipeline
Nachdem Sie die Daten mithilfe von Datentransformationen vorbereitet haben, können Sie sie zum Trainieren eines Machine Learning-Modells verwenden. Führen Sie die folgenden Schritte aus, um die Pipeline Auto Price Training zu erweitern.
-
Stellen Sie sicher, dass im Menü auf der linken Seite Designer ausgewählt ist, und dass Sie zur Pipeline Automatisches Preistraining zurückgekehrt sind.
-
Suchen Sie im Bereich Ressourcenbibliothek auf der linken Seite nach einem Modul vom Typ Daten teilen, und platzieren Sie es auf der Canvas unter dem Modul Daten normalisieren. Verbinden Sie dann die (linke) Ausgabe Transformiertes Dataset des Moduls Daten normalisieren mit der Eingabe des Moduls Daten teilen.
Tipp: Für die schnelle Suche nach Modulen verwenden Sie die Suchleiste.
- Doppelklicken Sie auf das Modul Daten teilen, und konfigurieren Sie seine Einstellungen wie folgt:
- Aufteilungsmodus: Zeilen aufteilen
- Bruchteil von Zeilen im ersten Ausgabedataset: 0,7
- Zufällige Aufteilung: True
- Zufälliger Ausgangswert: 123
- Geschichtete Aufteilung: FALSE
-
Suchen Sie in der Ressourcenbibliothek nach einem Modul vom Typ Modell trainieren, und platzieren Sie es auf der Canvas unter dem Modul Daten teilen. Verbinden Sie dann die (linke) Ausgabe Ergebnisse Dataset1 des Moduls Daten teilen mit der (rechten) Eingabe Dataset des Moduls Modell trainieren.
-
Das Modell, das Sie trainieren, sagt den Wert von price vorher. Wählen Sie also das Modul Modell trainieren aus, und ändern Sie seine Einstellungen, um die Bezeichnungsspalte auf price (achten Sie auf Groß-/Kleinschreibung) festzulegen.
Die Bezeichnung price, die das Modell vorhersagt, ist ein numerischer Wert. Daher müssen Sie das Modell mithilfe eines Regressionsalgorithmus trainieren.
-
Suchen Sie in der Ressourcenbibliothek nach einem Modul vom Typ Lineare Regression, und platzieren Sie es auf der Canvas links neben dem Modul Daten teilen und über dem Modul Modell trainieren. Verbinden Sie anschließend seinen Ausgang mit dem (linken) Eingang Untrainiertes Modell des Moduls Modell trainieren.
Hinweis: Es gibt mehrere Algorithmen, mit denen Sie Regressionsmodelle trainieren können. Wenn Sie Hilfe bei der Auswahl benötigen, sehen Sie sich den Spickzettel mit Machine Learning-Algorithmen für den Azure Machine Learning-Designer an.
Sie können das trainierte Modell testen, indem Sie es für die Bewertung des Validierungsdatasets verwenden, das Sie bei der Aufteilung der ursprünglichen Daten zurückgehalten haben. Sie sollen also die Bezeichnungen für die Features im Validierungsdataset vorhersagen.
-
Suchen Sie in der Ressourcenbibliothek nach einem Modul vom Typ Modell bewerten, und platzieren Sie es auf der Canvas unter dem Modul Modell trainieren. Verbinden Sie anschließend die Ausgabe des Moduls Modell trainieren mit der (linken) Eingabe Trainiertes Modell des Moduls Modell bewerten. Ziehen Sie die (rechte) Ausgabe Ergebnisse Dataset2 des Moduls Daten teilen in die (rechte) Eingabe Dataset des Moduls Modell bewerten.
-
Vergewissern Sie sich, dass Ihre Pipeline wie folgt aussieht:
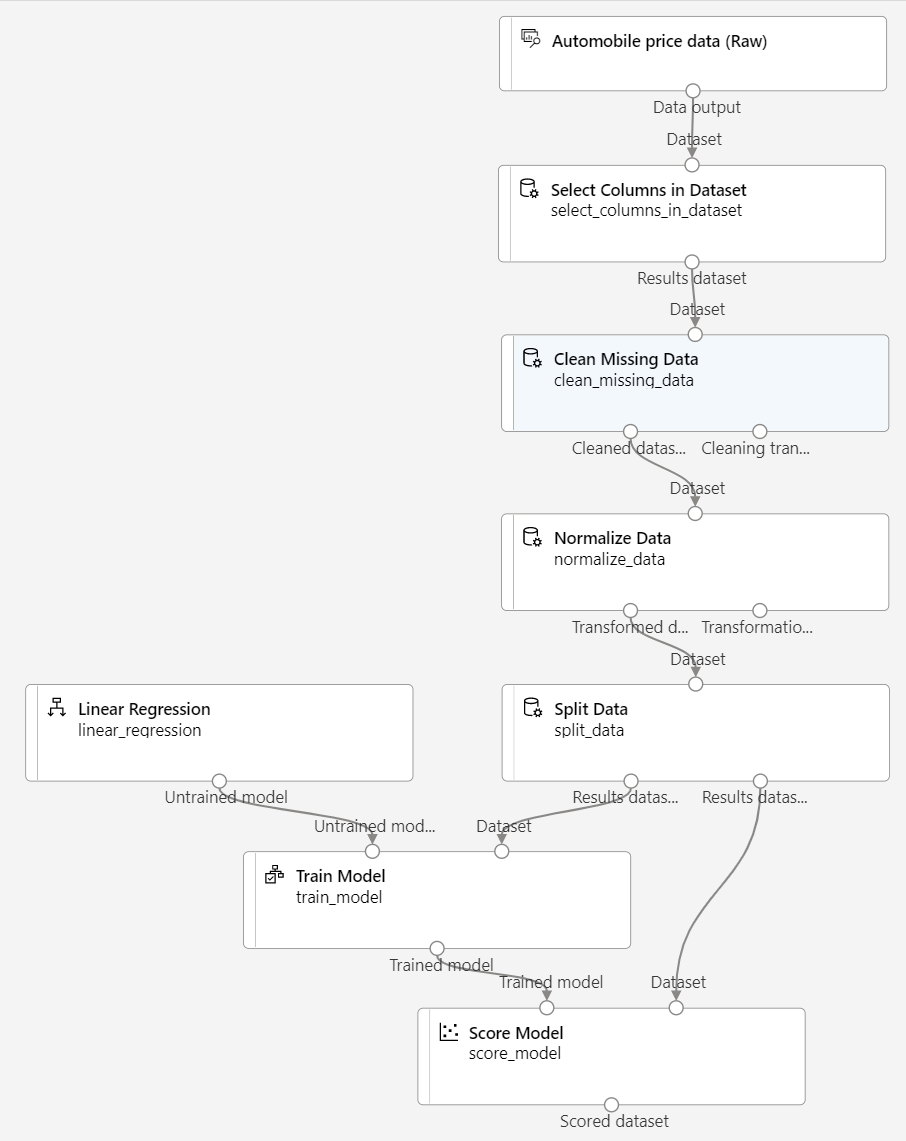
Ausführen der Trainingspipeline
Nun können Sie die Trainingspipeline ausführen und das Modell trainieren.
-
Wählen Sie Konfigurieren und Übermitteln aus, und führen Sie die Pipeline mithilfe des vorhandenen Experiments mslearn-auto-training aus.
-
Das Ausführen des Experiments wird fünf Minuten oder mehr dauern. Kehren Sie zur Seite Aufträge zurück, und wählen Sie die neueste Ausführung des Auftrags Auto Price Training aus.
-
Wenn die Ausführung des Experiments abgeschlossen wurde, klicken Sie mit der rechten Maustaste auf das Modul Modell auswerten, und wählen Sie Datenvorschau anzeigen und anschließend Bewertetes Dataset aus, um die Ergebnisse anzuzeigen.
-
Wenn Sie nach rechts scrollen, sollte neben der Spalte price (die die bekannten TRUE-Werte der Bezeichnung enthält) eine neue Spalte mit dem Namen Bewertete Bezeichnungen angezeigt werden, die die vorhergesagten Bezeichnungswerte enthält.
-
Schließen Sie die Registerkarte scored_dataset.
Das Modell prognostiziert nun Werte für die Bezeichnung price – aber wie zuverlässig sind diese Prognosen? Damit Sie dies bewerten können, müssen Sie zunächst das Modell auswerten.
Bewerten eines Modells
Eine Möglichkeit, ein Regressionsmodell zu bewerten, besteht darin, die vorhergesagten Bezeichnungen mit den tatsächlichen Bezeichnungen im Validierungsdataset zu vergleichen, das während des Trainings zurückgehalten wurde. Eine andere Möglichkeit besteht darin, die Leistung mehrerer Modelle zu vergleichen.
-
Öffnen Sie die von Ihnen erstellte Pipeline Auto Price Training.
-
Suchen Sie in der Ressourcenbibliothek nach einem Modul vom Typ Modell auswerten und platzieren Sie es auf der Canvas unter dem Modul Modell bewerten. Verbinden Sie die Ausgabe des Moduls Modell bewerten mit der Eingabe Bewertetes Dataset (links) des Moduls Modell auswerten.
-
Vergewissern Sie sich, dass Ihre Pipeline wie folgt aussieht:
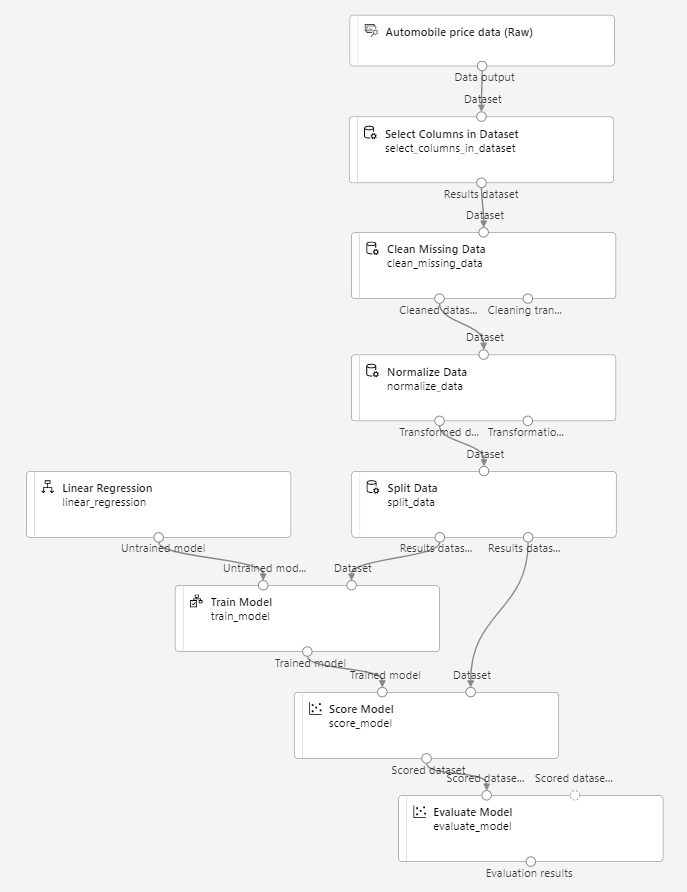
-
Wählen Sie Konfigurieren und Übermitteln aus, und führen Sie die Pipeline mithilfe des vorhandenen Experiments mslearn-auto-training aus.
-
Dieser Vorgang dauert einige Minuten. Kehren Sie zur Seite Aufträge zurück, und wählen Sie die neueste Ausführung des Auftrags Auto Price Training aus.
-
Wenn die Experimentausführung abgeschlossen wurde, wählen Sie Auftragsdetails aus, wodurch eine weitere Registerkarte geöffnet wird. Suchen Sie nach dem Modul Evaluate Model, und klicken Sie mit der rechten Maustaste darauf. Wählen Sie Datenvorschau anzeigen und anschließend Auswertungsergebnisse aus.
- Überprüfen Sie im Bereich Evaluation_results die Leistungsmetriken für die Regression:
- Mittlere absolute Abweichung (Mean Absolute Error, MAE)
- Mittlere quadratische Gesamtabweichung (Root Mean Squared Error, RMSE)
- Relative quadratische Abweichung (Relative Squared Error, RSE)
- Relative absolute Abweichung (Relative Absolute Error, RAE)
- Bestimmtheitsmaß (R2)
- Schließen Sie den Bereich Evaluation_results.
Wenn Sie ein Modell mit Bewertungsmetriken ermitteln konnten, dass Ihre Anforderungen erfüllen kann, können Sie die Verwendung dieses Modells mit neuen Daten vorbereiten.
Erstellen und Ausführen einer Rückschlusspipeline
-
Wählen Sie im Menü oberhalb des Canvas-Panels Rückschlusspipeline erstellen aus. Möglicherweise müssen Sie hierfür in den Vollbildmodus wechseln und rechts oben auf das Symbol mit den drei Punkten … klicken, damit die Option Rückschlusspipeline erstellen im Menü angezeigt wird.

-
Klicken Sie in der Dropdownliste Rückschlusspipeline erstellen auf Echtzeit-Rückschlusspipeline. Nach einigen Sekunden wird eine neue Version Ihrer Pipeline mit dem Namen Auto Price Training-real time inference geöffnet.
-
Benennen Sie die neue Pipeline in Predict Auto Price um, und überprüfen Sie dann die neue Pipeline. Sie enthält eine Webdiensteingabe für neue Daten, die übermittelt werden sollen, sowie eine Webdienstausgabe für die Rückgabe von Ergebnissen. Einige der Transformationen und Trainingsschritte sind Teil dieser Pipeline. Das trainierte Modell wird zur Bewertung der neuen Daten verwendet.
Nehmen Sie in den nächsten Schritten die folgenden Änderungen an der Rückschlusspipeline vor:
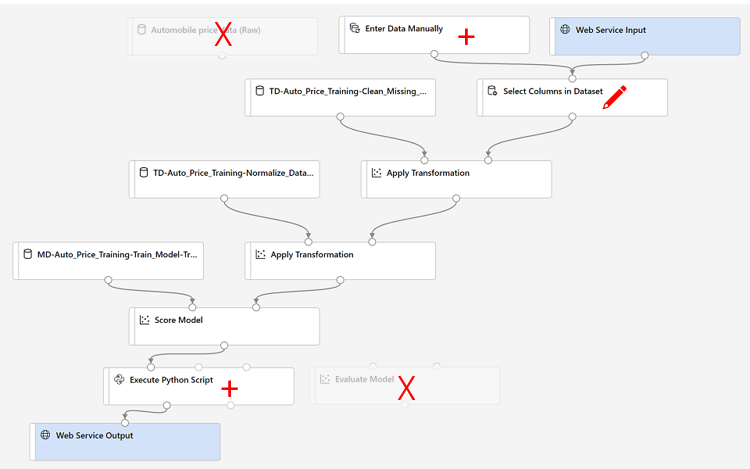
Verwenden Sie diese Abbildung als Referenz, wenn Sie die Pipeline in den nächsten Schritten ändern.
- Die Rückschlusspipeline geht davon aus, dass neue Daten dem Schema der ursprünglichen Trainingsdaten entsprechen, sodass das Dataset Automobile price data (Raw) aus der Trainingspipeline eingeschlossen wird. Diese Eingabedaten enthalten jedoch die Bezeichnung Price, die vom Modell vorhergesagt wird. Diese Bezeichnung in neue Autodaten einzubeziehen, ist nicht intuitiv, da noch keine Preisvorhersage gemacht wurde. Löschen Sie dieses Modul, und ersetzen Sie es durch ein Manuelle Eingabe von Daten-Modul aus dem Bereich Dateneingabe und -ausgabe.
-
Bearbeiten Sie das Modul Manuelle Eingabe von Daten, und geben Sie die folgenden CSV-Daten ein. Diese umfassen Merkmalwerte ohne Bezeichnungen für drei Autos. Kopieren Sie einfach den gesamten Textblock, und fügen Sie ihn ein:
symboling,normalized-losses,make,fuel-type,aspiration,num-of-doors,body-style,drive-wheels,engine-location,wheel-base,length,width,height,curb-weight,engine-type,num-of-cylinders,engine-size,fuel-system,bore,stroke,compression-ratio,horsepower,peak-rpm,city-mpg,highway-mpg 3,NaN,alfa-romero,gas,std,two,convertible,rwd,front,88.6,168.8,64.1,48.8,2548,dohc,four,130,mpfi,3.47,2.68,9,111,5000,21,27 3,NaN,alfa-romero,gas,std,two,convertible,rwd,front,88.6,168.8,64.1,48.8,2548,dohc,four,130,mpfi,3.47,2.68,9,111,5000,21,27 1,NaN,alfa-romero,gas,std,two,hatchback,rwd,front,94.5,171.2,65.5,52.4,2823,ohcv,six,152,mpfi,2.68,3.47,9,154,5000,19,26 -
Verbinden Sie das neue Modul Daten manuell eingeben mit derselben Eingabe des Datasets des Moduls Spalten im Dataset auswählen wie bei der Webdiensteingabe.
-
Da Sie nun das Schema der eingehenden Daten so geändert haben, dass das Feld Price ausgeschlossen wird, müssen Sie alle expliziten Verwendungen dieses Felds in den übrigen Modulen entfernen. Klicken Sie auf das Modul Spalten im Dataset auswählen, und bearbeiten Sie dann im Bereich „Einstellungen“ die Spalten, um das Feld Price zu entfernen.
-
Die Rückschlusspipeline umfasst das Modell Modul auswerten, das bei der Vorhersage aus neuen Daten nicht nützlich ist. Löschen Sie daher dieses Modul.
- Die Ausgabe des Moduls Modell bewerten umfasst alle Eingabemerkmale sowie die vorhergesagte Bezeichnung. Führen Sie die folgenden Schritte aus, wenn Sie die Ausgabe so bearbeiten möchten, dass nur die Vorhersage eingeschlossen wird:
- Löschen Sie die Verbindung zwischen dem Modul Modell bewerten und dem Webdienstausgang.
- Fügen Sie das Modul Python-Skript ausführen aus dem Abschnitt Python-Sprache hinzu. Ersetzen Sie dabei das gesamte Python-Standardskript durch den folgenden Code. Dabei wird nur die Spalte Scored Labels ausgewählt, und sie wird in predicted_price umbenannt:
import pandas as pd def azureml_main(dataframe1 = None, dataframe2 = None): scored_results = dataframe1[['Scored Labels']] scored_results.rename(columns={'Scored Labels':'predicted_price'}, inplace=True) return scored_resultsHinweis: Durch Kopieren und Einfügen können in das Python-Skript Leerzeichen eingefügt werden, die nicht enthalten sein sollten. Vergewissern Sie sich, dass sich vor import, def oder return keine Leerzeichen befinden. Stellen Sie sicher, dass sich vor scored_results und scored_results.rename() eine einfache Tabulator-Einrückung befindet.
-
Verbinden Sie die Ausgabe aus dem Modul Modell auswerten mit der Eingabe Dataset1 (ganz links) von Python-Skript ausführen.
-
Verbinden Sie die Ausgabe Ergebnisdataset (links) des Moduls Python-Skript ausführen mit dem Modul Webdienstausgabe.
-
Ihre Pipeline sollte etwa wie die folgende aussehen:
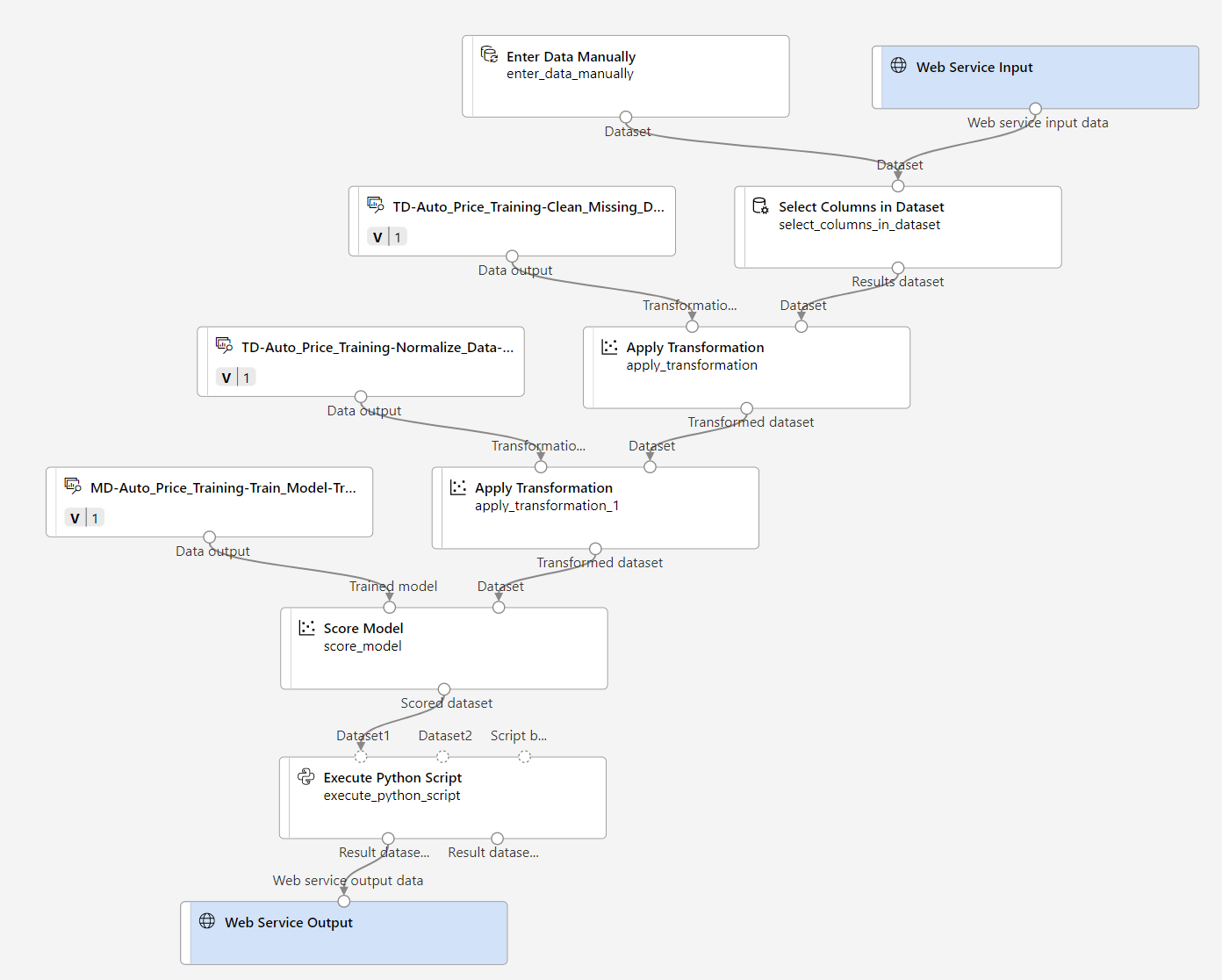
-
Übermitteln Sie die Pipeline als neues Experiment mit dem Namen mslearn-auto-inference an Ihren Computecluster. Die Ausführung des Experiments kann einige Minuten dauern.
-
Kehren Sie zur Seite Aufträge zurück, und wählen Sie die neueste Ausführung des Auftrags Auto Price Training aus (die Ausführung, die sich auf das Experiment mslearn-auto-inference bezieht).
-
Wenn die Pipeline abgeschlossen ist, klicken Sie mit der rechten Maustaste auf das Modul Python-Skript ausführen. Wählen Sie Datenvorschau anzeigen und anschließend Ergebnisdataset aus, um die vorhergesagten Preise für die drei Fahrzeuge aus den Eingabedaten anzuzeigen.
- Schließen Sie die Registerkarte Result_Dataset.
Ihre Rückschlusspipeline sagt Preise für Autos basierend auf ihren Merkmalen vorher. Sie können die Pipeline nun so veröffentlichen, dass sie von Clientanwendungen verwendet werden kann.
Bereitstellen des Modells
Nachdem Sie eine Rückschlusspipeline für Echtzeitrückschlüsse erstellt und getestet haben, können Sie sie als Dienst veröffentlichen, der von Clientanwendungen verwendet werden kann.
Hinweis: In dieser Übung stellen Sie den Webdienst in einer Azure-Containerinstanz bereit. Solche Computeressourcen werden dynamisch erstellt und sind für Entwicklungs- und Testzwecke nützlich. Für Produktionszwecke sollten Sie einen Rückschlusscluster erstellen, der einen AKS-Cluster (Azure Kubernetes Service) mit verbesserter Skalierbarkeit und Sicherheit bereitstellt.
Bereitstellen eines Diensts
-
Wählen Sie auf der Ausführungsseite des Auftrags Predict Auto Price in der oberen Menüleiste Bereitstellen aus.

- Wählen Sie auf dem Konfigurationsbildschirm die Option Neuen Echtzeitendpunkt bereitstellen aus, und verwenden Sie die folgenden Einstellungen:
- Name: predict-auto-price
- Beschreibung: Automatische Preisregression
- Computetyp: Azure Container Instances
- Wählen Sie Bereitstellen aus, und warten Sie einige Minuten, bis der Webdienst bereitgestellt wird.
Testen des Diensts
-
Öffnen Sie auf der Seite Endpunkte den Echtzeitendpunkt predict-auto-price.
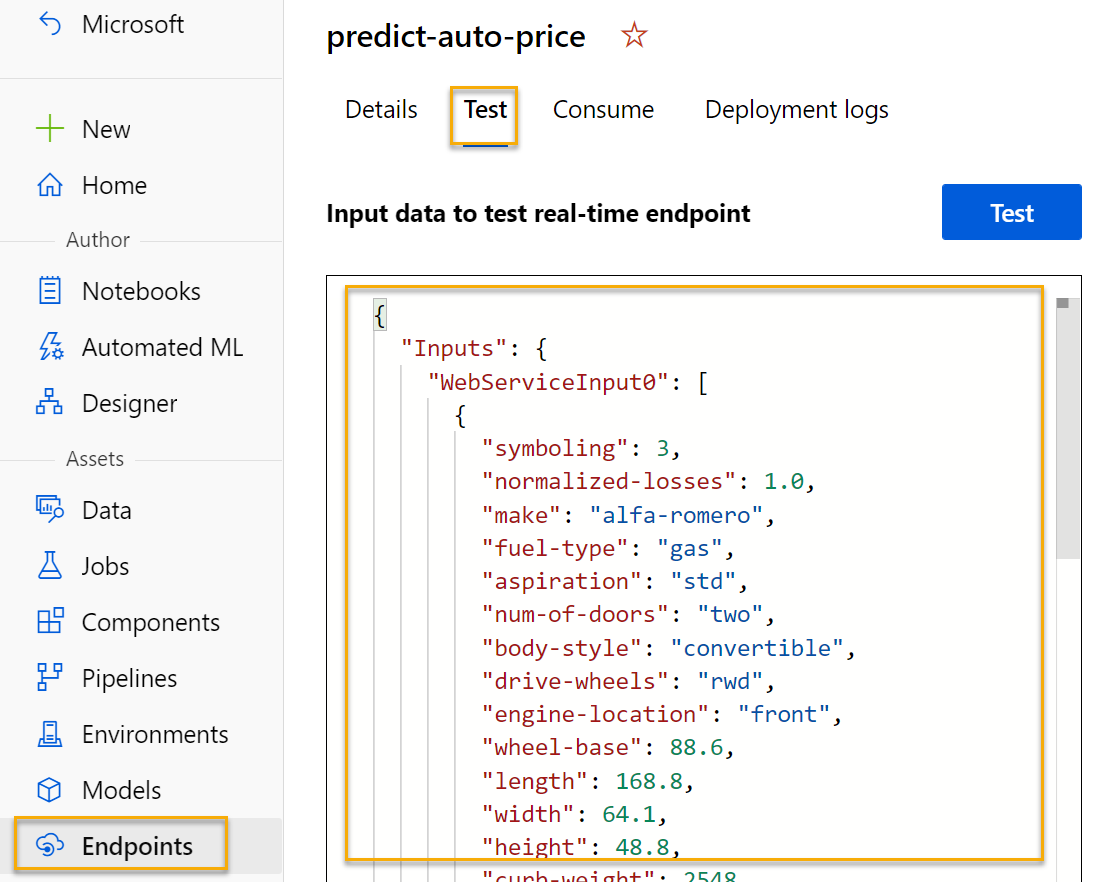
-
Wenn der Endpunkt predict-auto-price geöffnet wird, wählen Sie die Registerkarte Test aus. Hier testen wir unser Modell mit neuen Daten. Löschen Sie die vorhandenen Daten unter Input data to test endpoint (Eingabedaten zum Testen des Endpunkts). Kopieren Sie die folgenden Daten, und fügen Sie sie in den Abschnitt „Daten“ ein:
{ "Inputs": { "WebServiceInput0": [ { "symboling": 3, "normalized-losses": 1.0, "make": "alfa-romero", "fuel-type": "gas", "aspiration": "std", "num-of-doors": "two", "body-style": "convertible", "drive-wheels": "rwd", "engine-location": "front", "wheel-base": 88.6, "length": 168.8, "width": 64.1, "height": 48.8, "curb-weight": 2548, "engine-type": "dohc", "num-of-cylinders": "four", "engine-size": 130, "fuel-system": "mpfi", "bore": 3.47, "stroke": 2.68, "compression-ratio": 9, "horsepower": 111, "peak-rpm": 5000, "city-mpg": 21, "highway-mpg": 27 } ] }, "GlobalParameters": {} } -
Klicken Sie auf Test. Auf der rechten Seite des Bildschirms sollte die Ausgabe predicted_price angezeigt werden. Die Ausgabe ist der vorhergesagte Preis für ein Fahrzeug mit den in den Daten angegebenen Eingabefeatures.
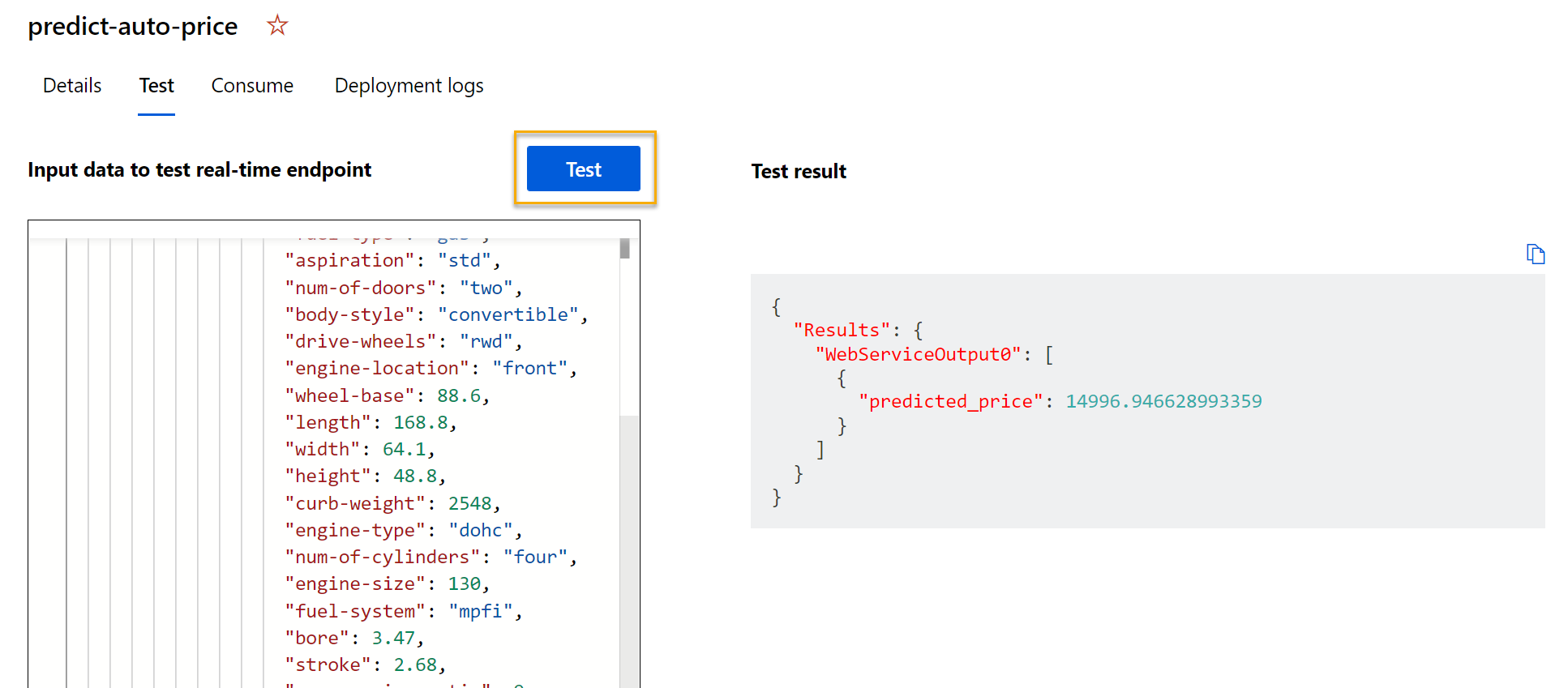
Sehen wir uns an, was Sie getan haben. Sie haben ein Dataset von Automobildaten bereinigt und transformiert und dann die Fahrzeugmerkmale verwendet, um ein Modell zu trainieren. Das Modell prognostiziert den Preis eines Autos, das die Bezeichnung darstellt.
Sie haben auch einen Dienst getestet, der mit einer Clientanwendung eine Verbindung herstellen kann, indem die Anmeldeinformationen auf der Registerkarte Consume (Verbrauchen) verwendet werden. Das Lab endet hier. Sie können gern weiter mit dem Dienst experimentieren, den Sie gerade eingerichtet haben.
Bereinigung
Der von Ihnen erstellte Webdienst wird in einer Azure-Containerinstanz gehostet. Wenn Sie nicht weiter experimentieren möchten, sollten Sie den Endpunkt löschen, um eine unnötige Azure-Nutzung zu vermeiden. Sie sollten auch den Computecluster löschen.
-
Wählen Sie in Azure Machine Learning Studio auf der Registerkarte Endpunkte den Endpunkt predict-auto-price aus. Klicken Sie dann auf Löschen, und bestätigen Sie, dass Sie den Endpunkt löschen möchten.
-
Wählen Sie auf der Seite Compute auf der Registerkarte Computecluster Ihren Computecluster aus, und klicken Sie dann auf Löschen.
Hinweis: Durch das Löschen Ihrer Compute-Instanz wird sichergestellt, dass Ihrem Abonnement keine Computeressourcen in Rechnung gestellt werden. Ihnen wird jedoch eine geringe Datenspeichermenge in Rechnung gestellt, solange der Azure Machine Learning-Arbeitsbereich in Ihrem Abonnement enthalten ist. Wenn Sie mit dem Erkunden von Azure Machine Learning fertig sind, können Sie Ihren Azure Machine Learning-Arbeitsbereich und die zugehörigen Ressourcen löschen. Wenn Sie jedoch andere Labs in dieser Reihe abschließen möchten, müssen Sie ihn neu erstellen.
So löschen Sie Ihren Arbeitsbereich:
- Öffnen Sie im Azure-Portal auf der Seite Ressourcengruppen die Ressourcengruppe, die Sie beim Erstellen des Azure Machine Learning-Arbeitsbereichs angegeben haben.
- Klicken Sie auf Ressourcengruppe löschen, geben Sie den Ressourcengruppennamen ein, um zu bestätigen, dass Sie ihn löschen möchten, und klicken Sie dann auf Löschen.